 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Few-Shot Continual Learning in Vision-Language Models
Feb 07, 2025Vision-language models (VLMs) excel in tasks such as visual question answering and image captioning. However, VLMs are often limited by their use of pretrained image encoders, like CLIP, leading to image understanding errors that hinder overall performance. On top of that, real-world applications often require the model to be continuously adapted as new and often limited data continuously arrive. To address this, we propose LoRSU (Low-Rank Adaptation with Structured Updates), a robust and computationally efficient method for selectively updating image encoders within VLMs. LoRSU introduces structured and localized parameter updates, effectively correcting performance on previously error-prone data while preserving the model's general robustness. Our approach leverages theoretical insights to identify and update only the most critical parameters, achieving significant resource efficiency. Specifically, we demonstrate that LoRSU reduces computational overhead by over 25x compared to full VLM updates, without sacrificing performance. Experimental results on VQA tasks in the few-shot continual learning setting, validate LoRSU's scalability, efficiency, and effectiveness, making it a compelling solution for image encoder adaptation in resource-constrained environments.
Personalization Toolkit: Training Free Personalization of Large Vision Language Models
Feb 04, 2025Large Vision Language Models (LVLMs) have significant potential to deliver personalized assistance by adapting to individual users' unique needs and preferences. Personalization of LVLMs is an emerging area that involves customizing models to recognize specific object instances and provide tailored responses. However, existing approaches rely on time-consuming test-time training for each user and object, rendering them impractical. This paper proposes a novel, training-free approach to LVLM personalization by leveraging pre-trained vision foundation models to extract distinct features, retrieval-augmented generation (RAG) techniques to recognize instances in the visual input, and visual prompting methods. Our model-agnostic vision toolkit enables flexible and efficient personalization without extensive retraining. We demonstrate state-of-the-art results, outperforming conventional training-based approaches and establish a new standard for LVLM personalization.
Imperfect Vision Encoders: Efficient and Robust Tuning for Vision-Language Models
Jul 23, 2024Vision language models (VLMs) demonstrate impressive capabilities in visual question answering and image captioning, acting as a crucial link between visual and language models. However, existing open-source VLMs heavily rely on pretrained and frozen vision encoders (such as CLIP). Despite CLIP's robustness across diverse domains, it still exhibits non-negligible image understanding errors. These errors propagate to the VLM responses, resulting in sub-optimal performance. In our work, we propose an efficient and robust method for updating vision encoders within VLMs. Our approach selectively and locally updates encoders, leading to substantial performance improvements on data where previous mistakes occurred, while maintaining overall robustness. Furthermore, we demonstrate the effectiveness of our method during continual few-shot updates. Theoretical grounding, generality, and computational efficiency characterize our approach.
VRS-NeRF: Visual Relocalization with Sparse Neural Radiance Field
Apr 14, 2024



Visual relocalization is a key technique to autonomous driving, robotics, and virtual/augmented reality. After decades of explorations, absolute pose regression (APR), scene coordinate regression (SCR), and hierarchical methods (HMs) have become the most popular frameworks. However, in spite of high efficiency, APRs and SCRs have limited accuracy especially in large-scale outdoor scenes; HMs are accurate but need to store a large number of 2D descriptors for matching, resulting in poor efficiency. In this paper, we propose an efficient and accurate framework, called VRS-NeRF, for visual relocalization with sparse neural radiance field. Precisely, we introduce an explicit geometric map (EGM) for 3D map representation and an implicit learning map (ILM) for sparse patches rendering. In this localization process, EGP provides priors of spare 2D points and ILM utilizes these sparse points to render patches with sparse NeRFs for matching. This allows us to discard a large number of 2D descriptors so as to reduce the map size. Moreover, rendering patches only for useful points rather than all pixels in the whole image reduces the rendering time significantly. This framework inherits the accuracy of HMs and discards their low efficiency. Experiments on 7Scenes, CambridgeLandmarks, and Aachen datasets show that our method gives much better accuracy than APRs and SCRs, and close performance to HMs but is much more efficient.
Annotation Free Semantic Segmentation with Vision Foundation Models
Mar 14, 2024Semantic Segmentation is one of the most challenging vision tasks, usually requiring large amounts of training data with expensive pixel-level annotations. With the success of foundation models and especially vision-language models, recent works attempt to achieve zero-shot semantic segmentation while requiring either large scale training or additional image/pixel-level annotations. In this work, we build a lightweight module on top of a self-supervised pretrained vision encoder to align patch features with a pre-trained text encoder. Importantly, we generate free annotations for any semantic segmentation dataset using existing foundation models and train our alignment module cost free. We use CLIP to detect objects and SAM to generate high quality object masks. Our approach can bring language-based semantics to any pre-trained vision encoder with minimal training. Our module is lightweight, uses foundation models as a sole source of supervision and shows impressive generalization capability from little training data with no annotation.
OOD Aware Supervised Contrastive Learning
Oct 03, 2023Out-of-Distribution (OOD) detection is a crucial problem for the safe deployment of machine learning models identifying samples that fall outside of the training distribution, i.e. in-distribution data (ID). Most OOD works focus on the classification models trained with Cross Entropy (CE) and attempt to fix its inherent issues. In this work we leverage powerful representation learned with Supervised Contrastive (SupCon) training and propose a holistic approach to learn a classifier robust to OOD data. We extend SupCon loss with two additional contrast terms. The first term pushes auxiliary OOD representations away from ID representations without imposing any constraints on similarities among auxiliary data. The second term pushes OOD features far from the existing class prototypes, while pushing ID representations closer to their corresponding class prototype. When auxiliary OOD data is not available, we propose feature mixing techniques to efficiently generate pseudo-OOD features. Our solution is simple and efficient and acts as a natural extension of the closed-set supervised contrastive representation learning. We compare against different OOD detection methods on the common benchmarks and show state-of-the-art results.
First Session Adaptation: A Strong Replay-Free Baseline for Class-Incremental Learning
Mar 23, 2023



In Class-Incremental Learning (CIL) an image classification system is exposed to new classes in each learning session and must be updated incrementally. Methods approaching this problem have updated both the classification head and the feature extractor body at each session of CIL. In this work, we develop a baseline method, First Session Adaptation (FSA), that sheds light on the efficacy of existing CIL approaches and allows us to assess the relative performance contributions from head and body adaption. FSA adapts a pre-trained neural network body only on the first learning session and fixes it thereafter; a head based on linear discriminant analysis (LDA), is then placed on top of the adapted body, allowing exact updates through CIL. FSA is replay-free i.e.~it does not memorize examples from previous sessions of continual learning. To empirically motivate FSA, we first consider a diverse selection of 22 image-classification datasets, evaluating different heads and body adaptation techniques in high/low-shot offline settings. We find that the LDA head performs well and supports CIL out-of-the-box. We also find that Featurewise Layer Modulation (FiLM) adapters are highly effective in the few-shot setting, and full-body adaption in the high-shot setting. Second, we empirically investigate various CIL settings including high-shot CIL and few-shot CIL, including settings that have previously been used in the literature. We show that FSA significantly improves over the state-of-the-art in 15 of the 16 settings considered. FSA with FiLM adapters is especially performant in the few-shot setting. These results indicate that current approaches to continuous body adaptation are not working as expected. Finally, we propose a measure that can be applied to a set of unlabelled inputs which is predictive of the benefits of body adaptation.
Seeking Similarities over Differences: Similarity-based Domain Alignment for Adaptive Object Detection
Oct 04, 2021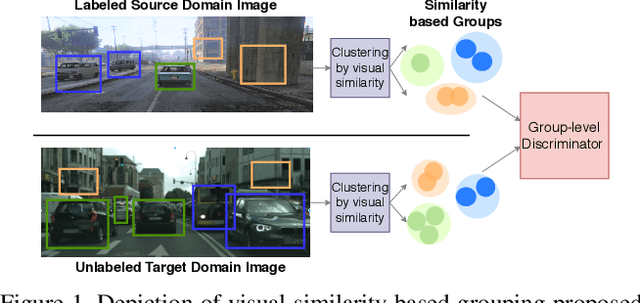
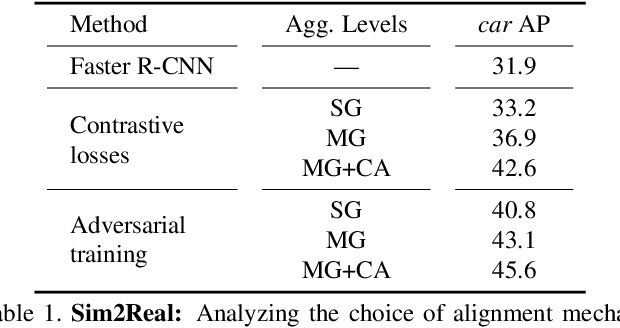
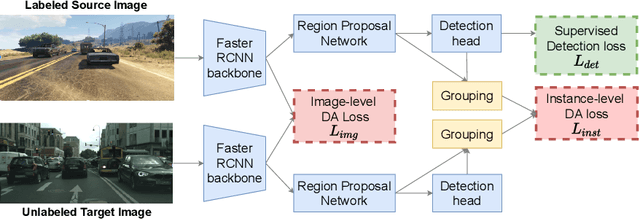

In order to robustly deploy object detectors across a wide range of scenarios, they should be adaptable to shifts in the input distribution without the need to constantly annotate new data. This has motivated research in Unsupervised Domain Adaptation (UDA) algorithms for detection. UDA methods learn to adapt from labeled source domains to unlabeled target domains, by inducing alignment between detector features from source and target domains. Yet, there is no consensus on what features to align and how to do the alignment. In our work, we propose a framework that generalizes the different components commonly used by UDA methods laying the ground for an in-depth analysis of the UDA design space. Specifically, we propose a novel UDA algorithm, ViSGA, a direct implementation of our framework, that leverages the best design choices and introduces a simple but effective method to aggregate features at instance-level based on visual similarity before inducing group alignment via adversarial training. We show that both similarity-based grouping and adversarial training allows our model to focus on coarsely aligning feature groups, without being forced to match all instances across loosely aligned domains. Finally, we examine the applicability of ViSGA to the setting where labeled data are gathered from different sources. Experiments show that not only our method outperforms previous single-source approaches on Sim2Real and Adverse Weather, but also generalizes well to the multi-source setting.
MonoCInIS: Camera Independent Monocular 3D Object Detection using Instance Segmentation
Oct 01, 2021
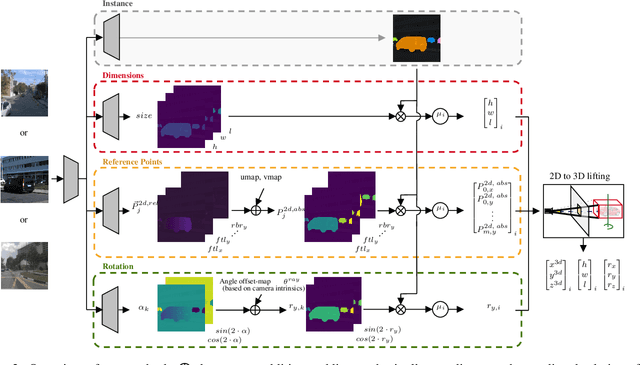
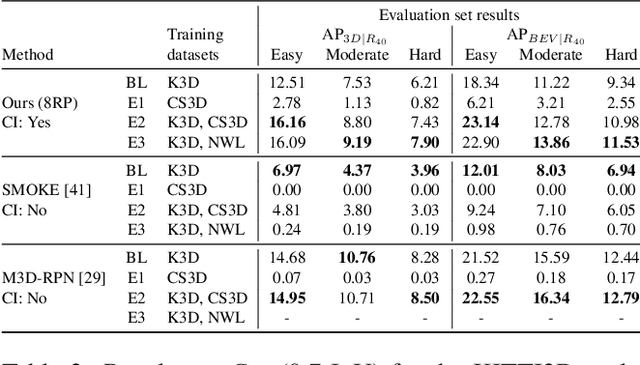
Monocular 3D object detection has recently shown promising results, however there remain challenging problems. One of those is the lack of invariance to different camera intrinsic parameters, which can be observed across different 3D object datasets. Little effort has been made to exploit the combination of heterogeneous 3D object datasets. In contrast to general intuition, we show that more data does not automatically guarantee a better performance, but rather, methods need to have a degree of 'camera independence' in order to benefit from large and heterogeneous training data. In this paper we propose a category-level pose estimation method based on instance segmentation, using camera independent geometric reasoning to cope with the varying camera viewpoints and intrinsics of different datasets. Every pixel of an instance predicts the object dimensions, the 3D object reference points projected in 2D image space and, optionally, the local viewing angle. Camera intrinsics are only used outside of the learned network to lift the predicted 2D reference points to 3D. We surpass camera independent methods on the challenging KITTI3D benchmark and show the key benefits compared to camera dependent methods.
Continual Novelty Detection
Jun 24, 2021



Novelty Detection methods identify samples that are not representative of a model's training set thereby flagging misleading predictions and bringing a greater flexibility and transparency at deployment time. However, research in this area has only considered Novelty Detection in the offline setting. Recently, there has been a growing realization in the computer vision community that applications demand a more flexible framework - Continual Learning - where new batches of data representing new domains, new classes or new tasks become available at different points in time. In this setting, Novelty Detection becomes more important, interesting and challenging. This work identifies the crucial link between the two problems and investigates the Novelty Detection problem under the Continual Learning setting. We formulate the Continual Novelty Detection problem and present a benchmark, where we compare several Novelty Detection methods under different Continual Learning settings. We show that Continual Learning affects the behaviour of novelty detection algorithms, while novelty detection can pinpoint insights in the behaviour of a continual learner. We further propose baselines and discuss possible research directions. We believe that the coupling of the two problems is a promising direction to bring vision models into practice.