 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOD Aware Supervised Contrastive Learning
Oct 03, 2023Out-of-Distribution (OOD) detection is a crucial problem for the safe deployment of machine learning models identifying samples that fall outside of the training distribution, i.e. in-distribution data (ID). Most OOD works focus on the classification models trained with Cross Entropy (CE) and attempt to fix its inherent issues. In this work we leverage powerful representation learned with Supervised Contrastive (SupCon) training and propose a holistic approach to learn a classifier robust to OOD data. We extend SupCon loss with two additional contrast terms. The first term pushes auxiliary OOD representations away from ID representations without imposing any constraints on similarities among auxiliary data. The second term pushes OOD features far from the existing class prototypes, while pushing ID representations closer to their corresponding class prototype. When auxiliary OOD data is not available, we propose feature mixing techniques to efficiently generate pseudo-OOD features. Our solution is simple and efficient and acts as a natural extension of the closed-set supervised contrastive representation learning. We compare against different OOD detection methods on the common benchmarks and show state-of-the-art results.
Contrastive Classification and Representation Learning with Probabilistic Interpretation
Nov 07, 2022
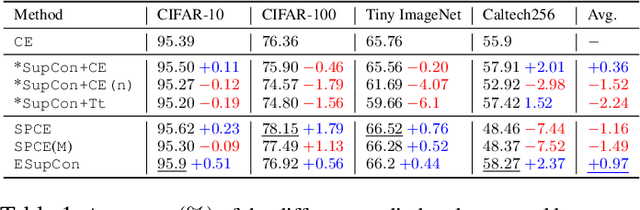


Cross entropy loss has served as the main objective function for classification-based tasks. Widely deployed for learning neural network classifiers, it shows both effectiveness and a probabilistic interpretation. Recently, after the success of self supervised contrastive representation learning methods, supervised contrastive methods have been proposed to learn representations and have shown superior and more robust performance, compared to solely training with cross entropy loss. However, cross entropy loss is still needed to train the final classification layer. In this work, we investigate the possibility of learning both the representation and the classifier using one objective function that combines the robustness of contrastive learning and the probabilistic interpretation of cross entropy loss. First, we revisit a previously proposed contrastive-based objective function that approximates cross entropy loss and present a simple extension to learn the classifier jointly. Second, we propose a new version of the supervised contrastive training that learns jointly the parameters of the classifier and the backbone of the network. We empirically show that our proposed objective functions show a significant improvement over the standard cross entropy loss with more training stability and robustness in various challenging settings.
Continual Novelty Detection
Jun 24, 2021



Novelty Detection methods identify samples that are not representative of a model's training set thereby flagging misleading predictions and bringing a greater flexibility and transparency at deployment time. However, research in this area has only considered Novelty Detection in the offline setting. Recently, there has been a growing realization in the computer vision community that applications demand a more flexible framework - Continual Learning - where new batches of data representing new domains, new classes or new tasks become available at different points in time. In this setting, Novelty Detection becomes more important, interesting and challenging. This work identifies the crucial link between the two problems and investigates the Novelty Detection problem under the Continual Learning setting. We formulate the Continual Novelty Detection problem and present a benchmark, where we compare several Novelty Detection methods under different Continual Learning settings. We show that Continual Learning affects the behaviour of novelty detection algorithms, while novelty detection can pinpoint insights in the behaviour of a continual learner. We further propose baselines and discuss possible research directions. We believe that the coupling of the two problems is a promising direction to bring vision models into practice.
Identifying Wrongly Predicted Samples: A Method for Active Learning
Oct 14, 2020



State-of-the-art machine learning models require access to significant amount of annotated data in order to achieve the desired level of performance. While unlabelled data can be largely available and even abundant, annotation process can be quite expensive and limiting. Under the assumption that some samples are more important for a given task than others, active learning targets the problem of identifying the most informative samples that one should acquire annotations for. Instead of the conventional reliance on model uncertainty as a proxy to leverage new unknown labels, in this work we propose a simple sample selection criterion that moves beyond uncertainty. By first accepting the model prediction and then judging its effect on the generalization error, we can better identify wrongly predicted samples. We further present an approximation to our criterion that is very efficient and provides a similarity based interpretation. In addition to evaluating our method on the standard benchmarks of active learning, we consider the challenging yet realistic scenario of imbalanced data where categories are not equally represented. We show state-of-the-art results and better rates at identifying wrongly predicted samples. Our method is simple, model agnostic and relies on the current model status without the need for re-training from scratch.