 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo: Embedding-Guided Personalization of Vision-Language Models
Mar 11, 2026AI assistants that support humans in daily life are becoming increasingly feasible, driven by the rapid advancements in multimodal language models. A key challenge lies in overcoming the generic nature of these models to deliver personalized experiences. Existing approaches to personalizing large vision language models often rely on additional training stages, which limit generality and scalability, or on engineered pipelines with external pre-trained modules, which hinder deployment efficiency. In this work, we propose an efficient personalization method that leverages the model's inherent ability to capture personalized concepts. Specifically, we extract visual tokens that predominantly represent the target concept by utilizing the model's internal attention mechanisms. These tokens serve as a memory of that specific concept, enabling the model to recall and describe it when it appears in test images. We conduct a comprehensive and unified evaluation of our approach and SOTA methods across various personalization settings including single-concept, multi-concept, and video personalization, demonstrating strong performance gains with minimal personalization overhead.
Personalization Toolkit: Training Free Personalization of Large Vision Language Models
Feb 04, 2025Large Vision Language Models (LVLMs) have significant potential to deliver personalized assistance by adapting to individual users' unique needs and preferences. Personalization of LVLMs is an emerging area that involves customizing models to recognize specific object instances and provide tailored responses. However, existing approaches rely on time-consuming test-time training for each user and object, rendering them impractical. This paper proposes a novel, training-free approach to LVLM personalization by leveraging pre-trained vision foundation models to extract distinct features, retrieval-augmented generation (RAG) techniques to recognize instances in the visual input, and visual prompting methods. Our model-agnostic vision toolkit enables flexible and efficient personalization without extensive retraining. We demonstrate state-of-the-art results, outperforming conventional training-based approaches and establish a new standard for LVLM personalization.
Annotation Free Semantic Segmentation with Vision Foundation Models
Mar 14, 2024Semantic Segmentation is one of the most challenging vision tasks, usually requiring large amounts of training data with expensive pixel-level annotations. With the success of foundation models and especially vision-language models, recent works attempt to achieve zero-shot semantic segmentation while requiring either large scale training or additional image/pixel-level annotations. In this work, we build a lightweight module on top of a self-supervised pretrained vision encoder to align patch features with a pre-trained text encoder. Importantly, we generate free annotations for any semantic segmentation dataset using existing foundation models and train our alignment module cost free. We use CLIP to detect objects and SAM to generate high quality object masks. Our approach can bring language-based semantics to any pre-trained vision encoder with minimal training. Our module is lightweight, uses foundation models as a sole source of supervision and shows impressive generalization capability from little training data with no annotation.
OOD Aware Supervised Contrastive Learning
Oct 03, 2023Out-of-Distribution (OOD) detection is a crucial problem for the safe deployment of machine learning models identifying samples that fall outside of the training distribution, i.e. in-distribution data (ID). Most OOD works focus on the classification models trained with Cross Entropy (CE) and attempt to fix its inherent issues. In this work we leverage powerful representation learned with Supervised Contrastive (SupCon) training and propose a holistic approach to learn a classifier robust to OOD data. We extend SupCon loss with two additional contrast terms. The first term pushes auxiliary OOD representations away from ID representations without imposing any constraints on similarities among auxiliary data. The second term pushes OOD features far from the existing class prototypes, while pushing ID representations closer to their corresponding class prototype. When auxiliary OOD data is not available, we propose feature mixing techniques to efficiently generate pseudo-OOD features. Our solution is simple and efficient and acts as a natural extension of the closed-set supervised contrastive representation learning. We compare against different OOD detection methods on the common benchmarks and show state-of-the-art results.
Glimpse-Attend-and-Explore: Self-Attention for Active Visual Exploration
Aug 26, 2021
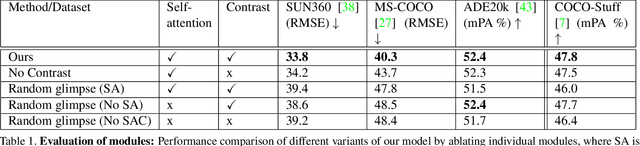
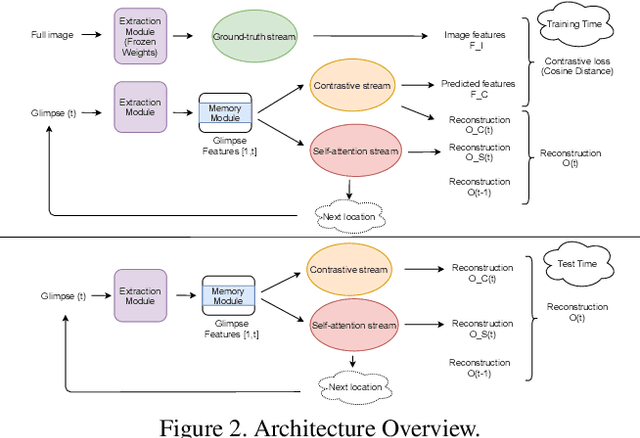
Active visual exploration aims to assist an agent with a limited field of view to understand its environment based on partial observations made by choosing the best viewing directions in the scene. Recent methods have tried to address this problem either by using reinforcement learning, which is difficult to train, or by uncertainty maps, which are task-specific and can only be implemented for dense prediction tasks. In this paper, we propose the Glimpse-Attend-and-Explore model which: (a) employs self-attention to guide the visual exploration instead of task-specific uncertainty maps; (b) can be used for both dense and sparse prediction tasks; and (c) uses a contrastive stream to further improve the representations learned. Unlike previous works, we show the application of our model on multiple tasks like reconstruction, segmentation and classification. Our model provides encouraging results while being less dependent on dataset bias in driving the exploration. We further perform an ablation study to investigate the features and attention learned by our model. Finally, we show that our self-attention module learns to attend different regions of the scene by minimizing the loss on the downstream task. Code: https://github.com/soroushseifi/glimpse-attend-explore.
Attend and Segment: Attention Guided Active Semantic Segmentation
Jul 22, 2020
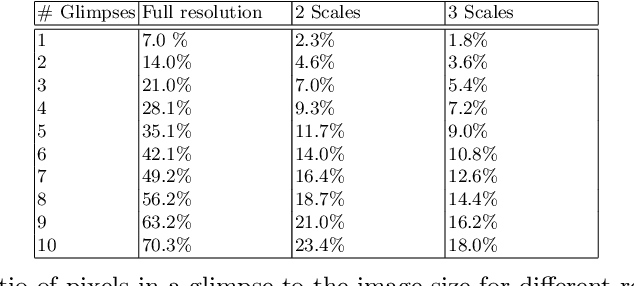
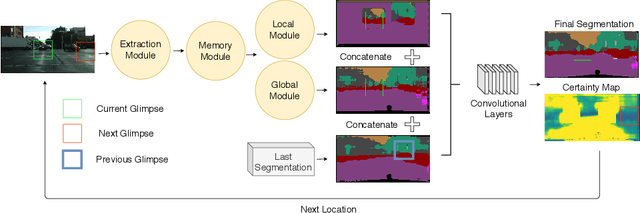
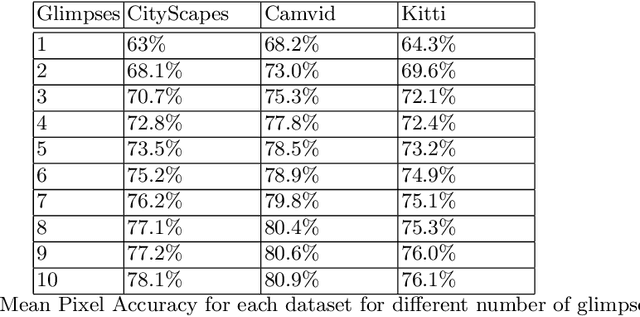
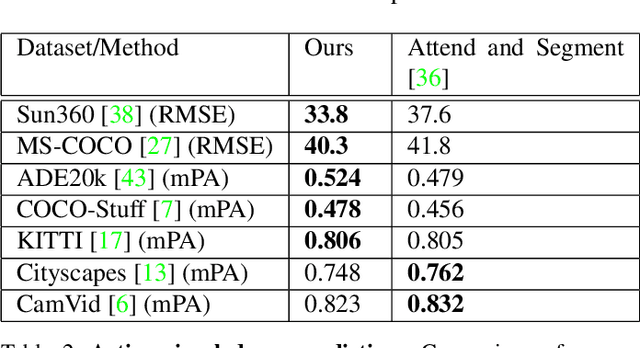
In a dynamic environment, an agent with a limited field of view/resource cannot fully observe the scene before attempting to parse it. The deployment of common semantic segmentation architectures is not feasible in such settings. In this paper we propose a method to gradually segment a scene given a sequence of partial observations. The main idea is to refine an agent's understanding of the environment by attending the areas it is most uncertain about. Our method includes a self-supervised attention mechanism and a specialized architecture to maintain and exploit spatial memory maps for filling-in the unseen areas in the environment. The agent can select and attend an area while relying on the cues coming from the visited areas to hallucinate the other parts. We reach a mean pixel-wise accuracy of 78.1%, 80.9% and 76.5% on CityScapes, CamVid, and Kitti datasets by processing only 18% of the image pixels (10 retina-like glimpses). We perform an ablation study on the number of glimpses, input image size and effectiveness of retina-like glimpses. We compare our method to several baselines and show that the optimal results are achieved by having access to a very low resolution view of the scene at the first timestep.
How to improve CNN-based 6-DoF camera pose estimation
Sep 23, 2019
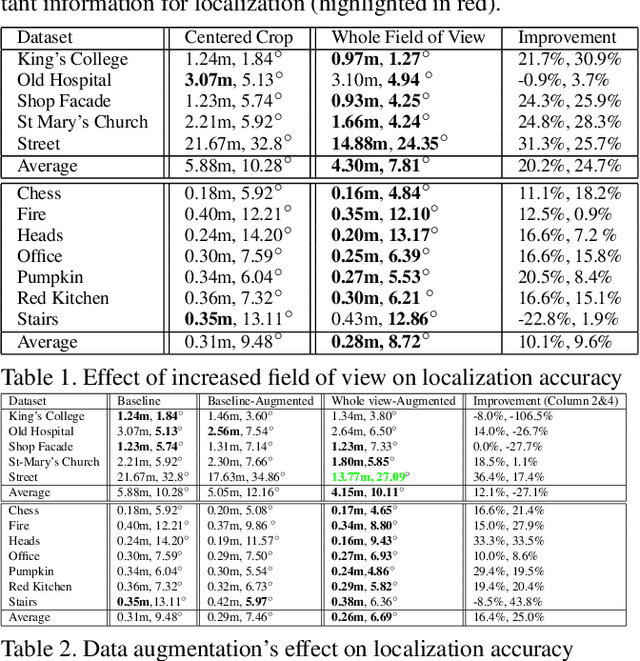
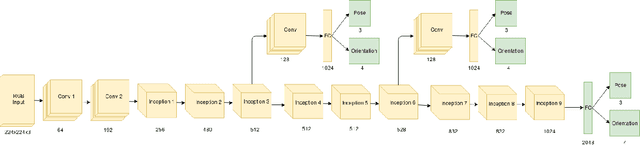

Convolutional neural networks (CNNs) and transfer learning have recently been used for 6 degrees of freedom (6-DoF) camera pose estimation. While they do not reach the same accuracy as visual SLAM-based approaches and are restricted to a specific environment, they excel in robustness and can be applied even to a single image. In this paper, we study PoseNet [1] and investigate modifications based on datasets' characteristics to improve the accuracy of the pose estimates. In particular, we emphasize the importance of field-of-view over image resolution; we present a data augmentation scheme to reduce overfitting; we study the effect of Long-Short-Term-Memory (LSTM) cells. Lastly, we combine these modifications and improve PoseNet's performance for monocular CNN based camera pose regression.
Where to Look Next: Unsupervised Active Visual Exploration on 360° Input
Sep 23, 2019

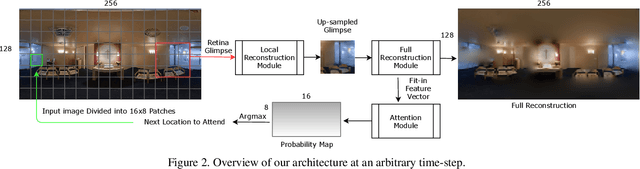
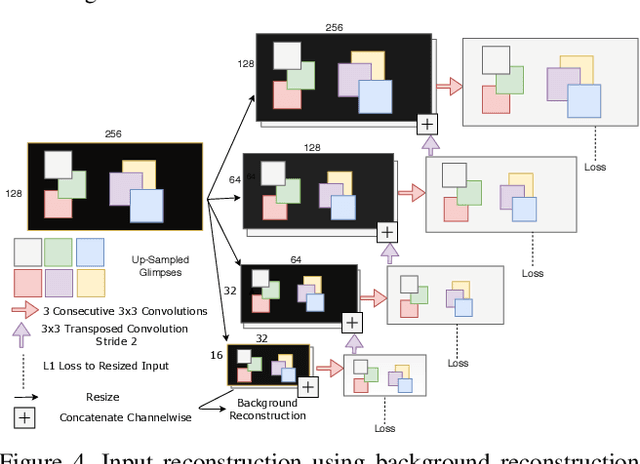
We address the problem of active visual exploration of large 360{\deg} inputs. In our setting an active agent with a limited camera bandwidth explores its 360{\deg} environment by changing its viewing direction at limited discrete time steps. As such, it observes the world as a sequence of narrow field-of-view 'glimpses', deciding for itself where to look next. Our proposed method exceeds previous works' performance by a significant margin without the need for deep reinforcement learning or training separate networks as sidekicks. A key component of our system are the spatial memory maps that make the system aware of the glimpses' orientations (locations in the 360{\deg} image). Further, we stress the advantages of retina-like glimpses when the agent's sensor bandwidth and time-steps are limited. Finally, we use our trained model to do classification of the whole scene using only the information observed in the glimpses.