 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to improve CNN-based 6-DoF camera pose estimation
Paper and Code
Sep 23, 2019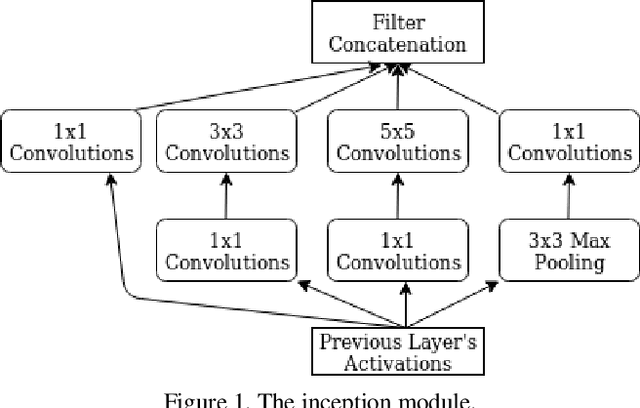
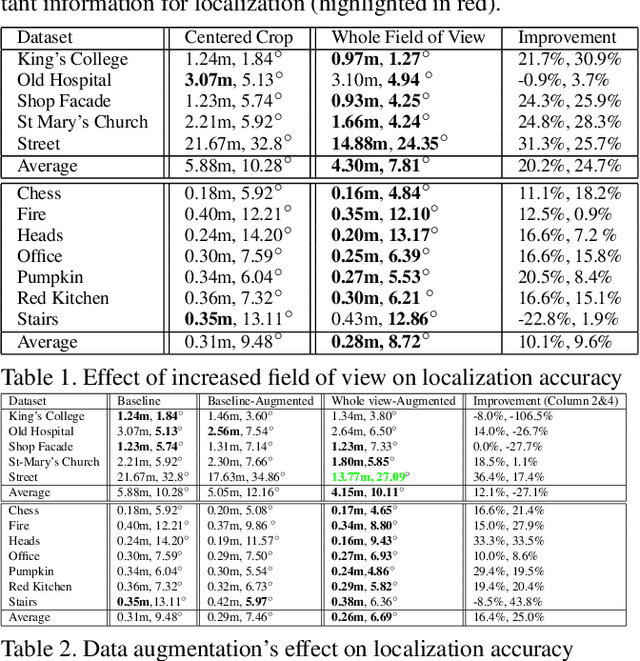
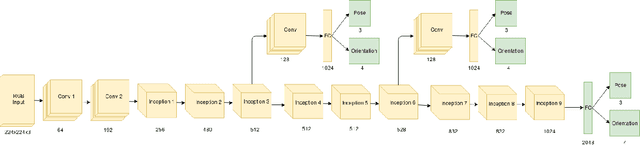

Convolutional neural networks (CNNs) and transfer learning have recently been used for 6 degrees of freedom (6-DoF) camera pose estimation. While they do not reach the same accuracy as visual SLAM-based approaches and are restricted to a specific environment, they excel in robustness and can be applied even to a single image. In this paper, we study PoseNet [1] and investigate modifications based on datasets' characteristics to improve the accuracy of the pose estimates. In particular, we emphasize the importance of field-of-view over image resolution; we present a data augmentation scheme to reduce overfitting; we study the effect of Long-Short-Term-Memory (LSTM) cells. Lastly, we combine these modifications and improve PoseNet's performance for monocular CNN based camera pose regression.