 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning with a Multi-Task Latent Space Objective
Feb 05, 2026Self-supervised learning (SSL) methods based on Siamese networks learn visual representations by aligning different views of the same image. The multi-crop strategy, which incorporates small local crops to global ones, enhances many SSL frameworks but causes instability in predictor-based architectures such as BYOL, SimSiam, and MoCo v3. We trace this failure to the shared predictor used across all views and demonstrate that assigning a separate predictor to each view type stabilizes multi-crop training, resulting in significant performance gains. Extending this idea, we treat each spatial transformation as a distinct alignment task and add cutout views, where part of the image is masked before encoding. This yields a simple multi-task formulation of asymmetric Siamese SSL that combines global, local, and masked views into a single framework. The approach is stable, generally applicable across backbones, and consistently improves the performance of ResNet and ViT models on ImageNet.
Camera-Only 3D Panoptic Scene Completion for Autonomous Driving through Differentiable Object Shapes
May 14, 2025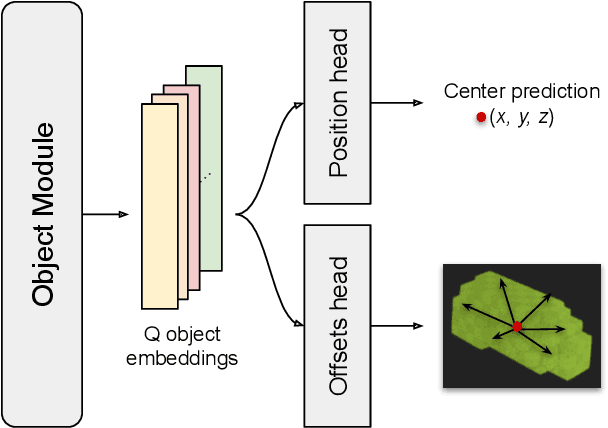
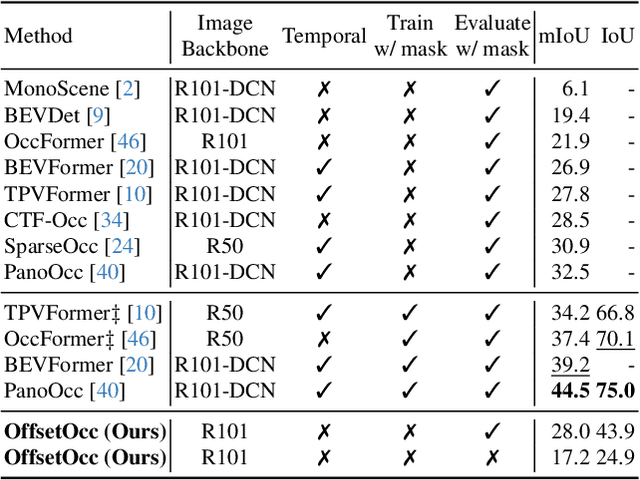
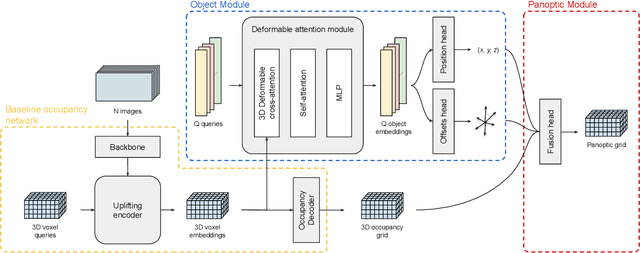
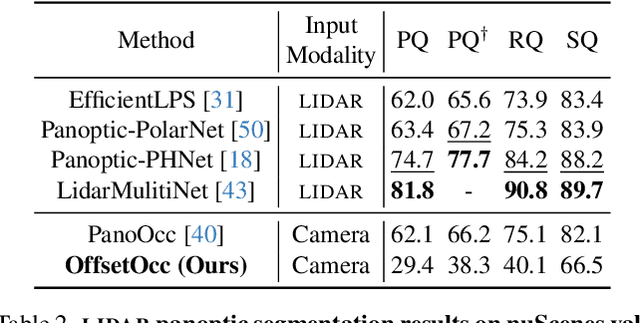
Autonomous vehicles need a complete map of their surroundings to plan and act. This has sparked research into the tasks of 3D occupancy prediction, 3D scene completion, and 3D panoptic scene completion, which predict a dense map of the ego vehicle's surroundings as a voxel grid. Scene completion extends occupancy prediction by predicting occluded regions of the voxel grid, and panoptic scene completion further extends this task by also distinguishing object instances within the same class; both aspects are crucial for path planning and decision-making. However, 3D panoptic scene completion is currently underexplored. This work introduces a novel framework for 3D panoptic scene completion that extends existing 3D semantic scene completion models. We propose an Object Module and Panoptic Module that can easily be integrated with 3D occupancy and scene completion methods presented in the literature. Our approach leverages the available annotations in occupancy benchmarks, allowing individual object shapes to be learned as a differentiable problem. The code is available at https://github.com/nicolamarinello/OffsetOcc .
Adversarial Dependence Minimization
Feb 05, 2025Many machine learning techniques rely on minimizing the covariance between output feature dimensions to extract minimally redundant representations from data. However, these methods do not eliminate all dependencies/redundancies, as linearly uncorrelated variables can still exhibit nonlinear relationships. This work provides a differentiable and scalable algorithm for dependence minimization that goes beyond linear pairwise decorrelation. Our method employs an adversarial game where small networks identify dependencies among feature dimensions, while the encoder exploits this information to reduce dependencies. We provide empirical evidence of the algorithm's convergence and demonstrate its utility in three applications: extending PCA to nonlinear decorrelation, improving the generalization of image classification methods, and preventing dimensional collapse in self-supervised representation learning.
Contrastive Learning for Multi-Object Tracking with Transformers
Nov 14, 2023The DEtection TRansformer (DETR) opened new possibilities for object detection by modeling it as a translation task: converting image features into object-level representations. Previous works typically add expensive modules to DETR to perform Multi-Object Tracking (MOT), resulting in more complicated architectures. We instead show how DETR can be turned into a MOT model by employing an instance-level contrastive loss, a revised sampling strategy and a lightweight assignment method. Our training scheme learns object appearances while preserving detection capabilities and with little overhead. Its performance surpasses the previous state-of-the-art by +2.6 mMOTA on the challenging BDD100K dataset and is comparable to existing transformer-based methods on the MOT17 dataset.
Unbalanced Optimal Transport: A Unified Framework for Object Detection
Jul 05, 2023During training, supervised object detection tries to correctly match the predicted bounding boxes and associated classification scores to the ground truth. This is essential to determine which predictions are to be pushed towards which solutions, or to be discarded. Popular matching strategies include matching to the closest ground truth box (mostly used in combination with anchors), or matching via the Hungarian algorithm (mostly used in anchor-free methods). Each of these strategies comes with its own properties, underlying losses, and heuristics. We show how Unbalanced Optimal Transport unifies these different approaches and opens a whole continuum of methods in between. This allows for a finer selection of the desired properties. Experimentally, we show that training an object detection model with Unbalanced Optimal Transport is able to reach the state-of-the-art both in terms of Average Precision and Average Recall as well as to provide a faster initial convergence. The approach is well suited for GPU implementation, which proves to be an advantage for large-scale models.
TripletTrack: 3D Object Tracking using Triplet Embeddings and LSTM
Oct 28, 2022



3D object tracking is a critical task in autonomous driving systems. It plays an essential role for the system's awareness about the surrounding environment. At the same time there is an increasing interest in algorithms for autonomous cars that solely rely on inexpensive sensors, such as cameras. In this paper we investigate the use of triplet embeddings in combination with motion representations for 3D object tracking. We start from an off-the-shelf 3D object detector, and apply a tracking mechanism where objects are matched by an affinity score computed on local object feature embeddings and motion descriptors. The feature embeddings are trained to include information about the visual appearance and monocular 3D object characteristics, while motion descriptors provide a strong representation of object trajectories. We will show that our approach effectively re-identifies objects, and also behaves reliably and accurately in case of occlusions, missed detections and can detect re-appearance across different field of views. Experimental evaluation shows that our approach outperforms state-of-the-art on nuScenes by a large margin. We also obtain competitive results on KITTI.
* Accepted to CVPR 2022 Workshop on Autonomous Driving
Weakly-Supervised Semantic Segmentation by Learning Label Uncertainty
Oct 12, 2021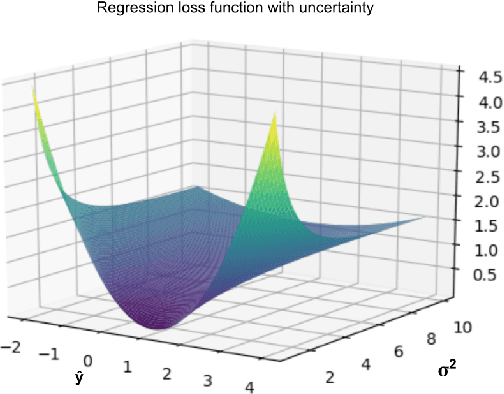
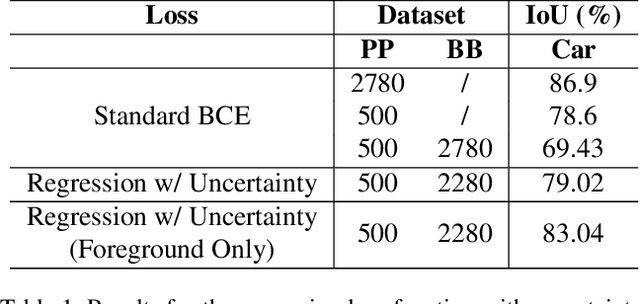

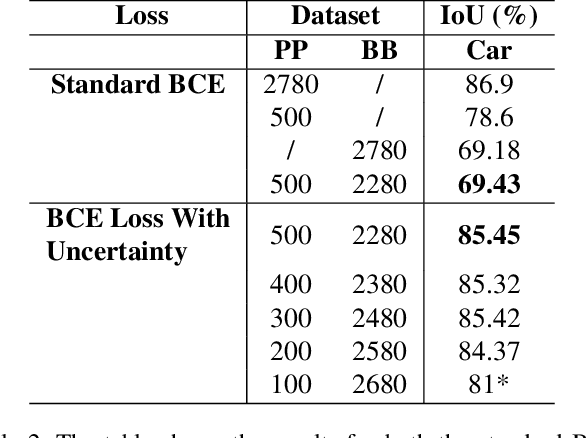
Since the rise of deep learning, many computer vision tasks have seen significant advancements. However, the downside of deep learning is that it is very data-hungry. Especially for segmentation problems, training a deep neural net requires dense supervision in the form of pixel-perfect image labels, which are very costly. In this paper, we present a new loss function to train a segmentation network with only a small subset of pixel-perfect labels, but take the advantage of weakly-annotated training samples in the form of cheap bounding-box labels. Unlike recent works which make use of box-to-mask proposal generators, our loss trains the network to learn a label uncertainty within the bounding-box, which can be leveraged to perform online bootstrapping (i.e. transforming the boxes to segmentation masks), while training the network. We evaluated our method on binary segmentation tasks, as well as a multi-class segmentation task (CityScapes vehicles and persons). We trained each task on a dataset comprised of only 18% pixel-perfect and 82% bounding-box labels, and compared the results to a baseline model trained on a completely pixel-perfect dataset. For the binary segmentation tasks, our method achieves an IoU score which is ~98.33% as good as our baseline model, while for the multi-class task, our method is 97.12% as good as our baseline model (77.5 vs. 79.8 mIoU).
MonoCInIS: Camera Independent Monocular 3D Object Detection using Instance Segmentation
Oct 01, 2021
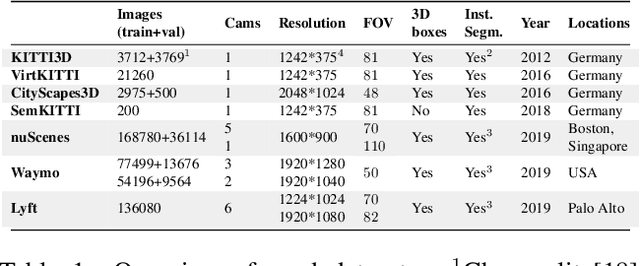
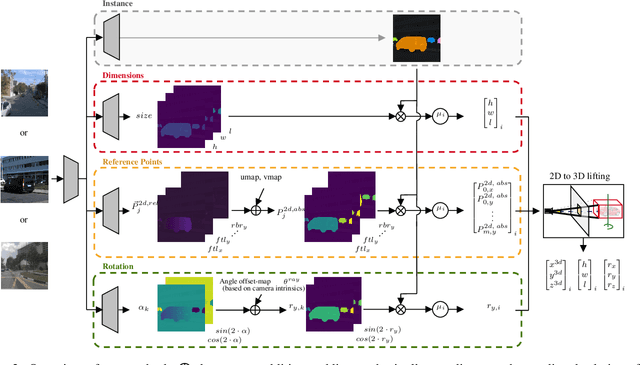
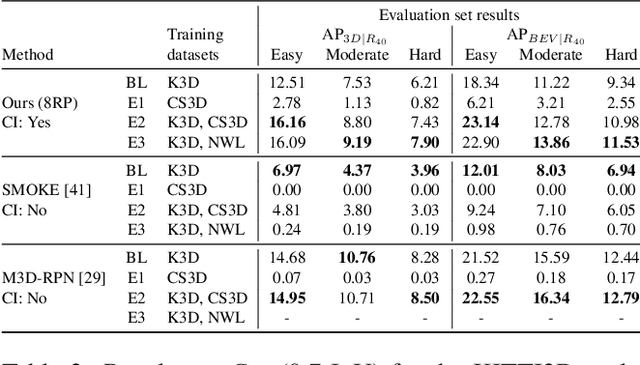
Monocular 3D object detection has recently shown promising results, however there remain challenging problems. One of those is the lack of invariance to different camera intrinsic parameters, which can be observed across different 3D object datasets. Little effort has been made to exploit the combination of heterogeneous 3D object datasets. In contrast to general intuition, we show that more data does not automatically guarantee a better performance, but rather, methods need to have a degree of 'camera independence' in order to benefit from large and heterogeneous training data. In this paper we propose a category-level pose estimation method based on instance segmentation, using camera independent geometric reasoning to cope with the varying camera viewpoints and intrinsics of different datasets. Every pixel of an instance predicts the object dimensions, the 3D object reference points projected in 2D image space and, optionally, the local viewing angle. Camera intrinsics are only used outside of the learned network to lift the predicted 2D reference points to 3D. We surpass camera independent methods on the challenging KITTI3D benchmark and show the key benefits compared to camera dependent methods.
Context-aware Padding for Semantic Segmentation
Sep 16, 2021



Zero padding is widely used in convolutional neural networks to prevent the size of feature maps diminishing too fast. However, it has been claimed to disturb the statistics at the border. As an alternative, we propose a context-aware (CA) padding approach to extend the image. We reformulate the padding problem as an image extrapolation problem and illustrate the effects on the semantic segmentation task. Using context-aware padding, the ResNet-based segmentation model achieves higher mean Intersection-Over-Union than the traditional zero padding on the Cityscapes and the dataset of DeepGlobe satellite imaging challenge. Furthermore, our padding does not bring noticeable overhead during training and testing.
Learning To Classify Images Without Labels
May 25, 2020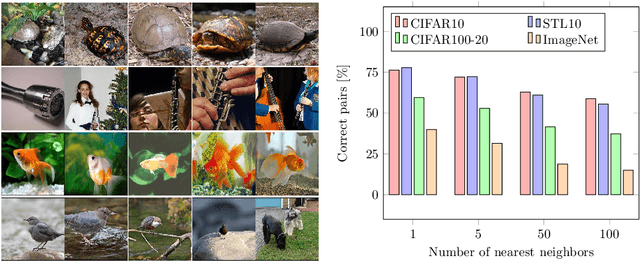
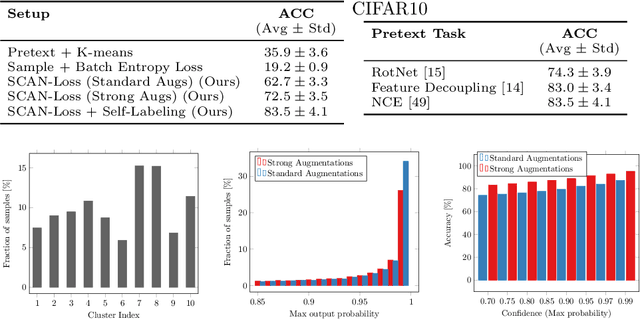
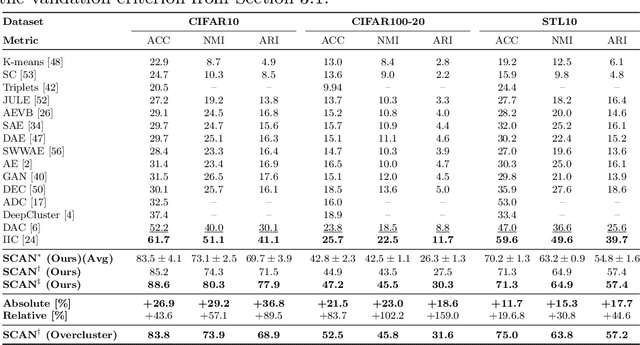
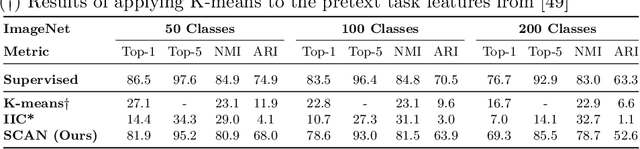
Is it possible to automatically classify images without the use of ground-truth annotations? Or when even the classes themselves, are not a priori known? These remain important, and open questions in computer vision. Several approaches have tried to tackle this problem in an end-to-end fashion. In this paper, we deviate from recent works, and advocate a two-step approach where feature learning and clustering are decoupled. First, a self-supervised task from representation learning is employed to obtain semantically meaningful features. Second, we use the obtained features as a prior in a learnable clustering approach. In doing so, we remove the ability for cluster learning to depend on low-level features, which is present in current end-to-end learning approaches. Experimental evaluation shows that we outperform state-of-the-art methods by huge margins, in particular +26.9% on CIFAR10, +21.5% on CIFAR100-20 and +11.7% on STL10 in terms of classification accuracy. Furthermore, results on ImageNet show that our approach is the first to scale well up to 200 randomly selected classes, obtaining 69.3% top-1 and 85.5% top-5 accuracy, and marking a difference of less than 7.5% with fully-supervised methods. Finally, we applied our approach to all 1000 classes on ImageNet, and found the results to be very encouraging. The code will be made publicly available.