 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Semantic Segmentation by Learning Label Uncertainty
Paper and Code
Oct 12, 2021
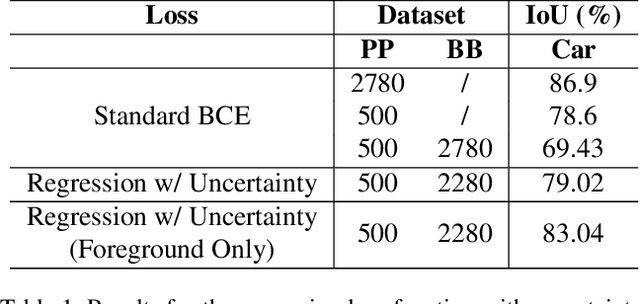

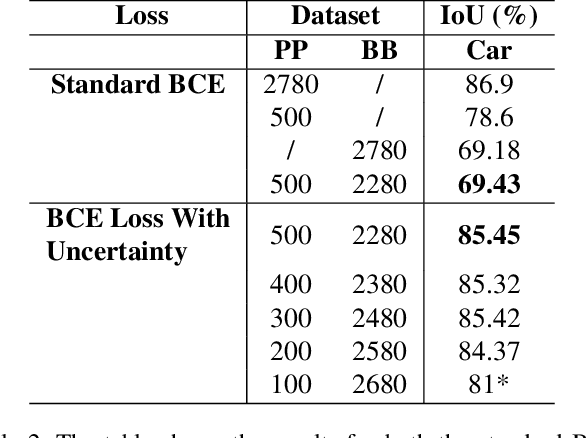
Since the rise of deep learning, many computer vision tasks have seen significant advancements. However, the downside of deep learning is that it is very data-hungry. Especially for segmentation problems, training a deep neural net requires dense supervision in the form of pixel-perfect image labels, which are very costly. In this paper, we present a new loss function to train a segmentation network with only a small subset of pixel-perfect labels, but take the advantage of weakly-annotated training samples in the form of cheap bounding-box labels. Unlike recent works which make use of box-to-mask proposal generators, our loss trains the network to learn a label uncertainty within the bounding-box, which can be leveraged to perform online bootstrapping (i.e. transforming the boxes to segmentation masks), while training the network. We evaluated our method on binary segmentation tasks, as well as a multi-class segmentation task (CityScapes vehicles and persons). We trained each task on a dataset comprised of only 18% pixel-perfect and 82% bounding-box labels, and compared the results to a baseline model trained on a completely pixel-perfect dataset. For the binary segmentation tasks, our method achieves an IoU score which is ~98.33% as good as our baseline model, while for the multi-class task, our method is 97.12% as good as our baseline model (77.5 vs. 79.8 mIoU).