 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyes on the Grass: Biodiversity-Increasing Robotic Mowing Using Deep Visual Embeddings
Dec 17, 2025This paper presents a robotic mowing framework that actively enhances garden biodiversity through visual perception and adaptive decision-making. Unlike passive rewilding approaches, the proposed system uses deep feature-space analysis to identify and preserve visually diverse vegetation patches in camera images by selectively deactivating the mower blades. A ResNet50 network pretrained on PlantNet300K provides ecologically meaningful embeddings, from which a global deviation metric estimates biodiversity without species-level supervision. These estimates drive a selective mowing algorithm that dynamically alternates between mowing and conservation behavior. The system was implemented on a modified commercial robotic mower and validated both in a controlled mock-up lawn and on real garden datasets. Results demonstrate a strong correlation between embedding-space dispersion and expert biodiversity assessment, confirming the feasibility of deep visual diversity as a proxy for ecological richness and the effectiveness of the proposed mowing decision approach. Widespread adoption of such systems will turn ecologically worthless, monocultural lawns into vibrant, valuable biotopes that boost urban biodiversity.
Person Detection Using an Ultra Low-resolution Thermal Imager on a Low-cost MCU
Dec 16, 2022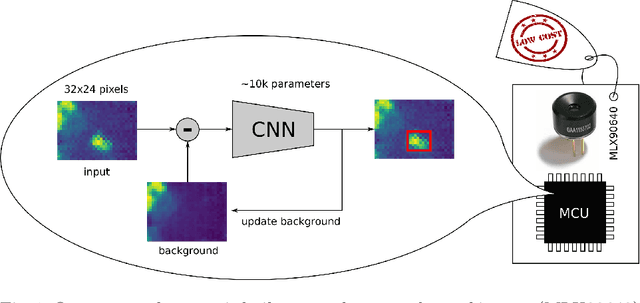
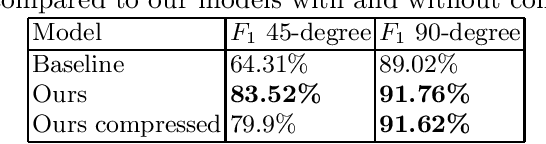
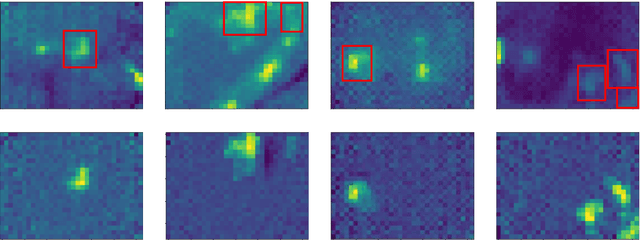
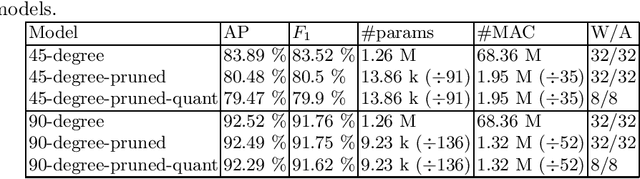
Detecting persons in images or video with neural networks is a well-studied subject in literature. However, such works usually assume the availability of a camera of decent resolution and a high-performance processor or GPU to run the detection algorithm, which significantly increases the cost of a complete detection system. However, many applications require low-cost solutions, composed of cheap sensors and simple microcontrollers. In this paper, we demonstrate that even on such hardware we are not condemned to simple classic image processing techniques. We propose a novel ultra-lightweight CNN-based person detector that processes thermal video from a low-cost 32x24 pixel static imager. Trained and compressed on our own recorded dataset, our model achieves up to 91.62% accuracy (F1-score), has less than 10k parameters, and runs as fast as 87ms and 46ms on low-cost microcontrollers STM32F407 and STM32F746, respectively.
Weakly-Supervised Semantic Segmentation by Learning Label Uncertainty
Oct 12, 2021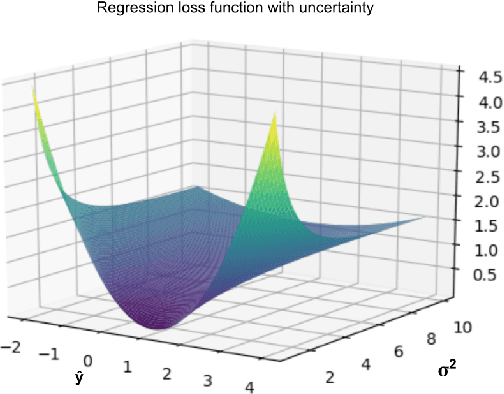
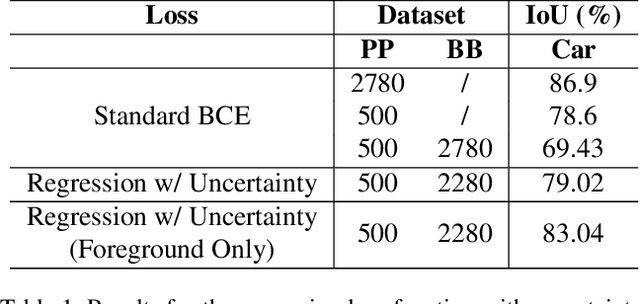

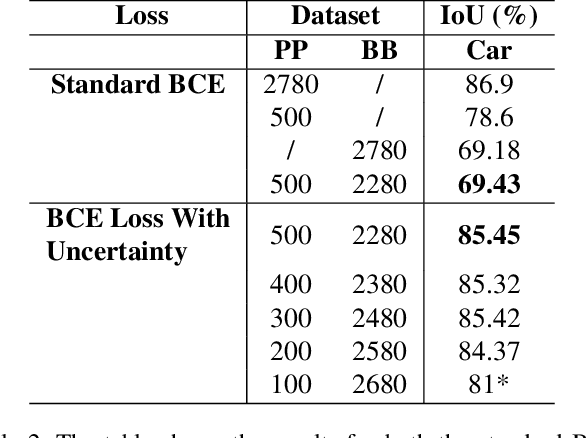
Since the rise of deep learning, many computer vision tasks have seen significant advancements. However, the downside of deep learning is that it is very data-hungry. Especially for segmentation problems, training a deep neural net requires dense supervision in the form of pixel-perfect image labels, which are very costly. In this paper, we present a new loss function to train a segmentation network with only a small subset of pixel-perfect labels, but take the advantage of weakly-annotated training samples in the form of cheap bounding-box labels. Unlike recent works which make use of box-to-mask proposal generators, our loss trains the network to learn a label uncertainty within the bounding-box, which can be leveraged to perform online bootstrapping (i.e. transforming the boxes to segmentation masks), while training the network. We evaluated our method on binary segmentation tasks, as well as a multi-class segmentation task (CityScapes vehicles and persons). We trained each task on a dataset comprised of only 18% pixel-perfect and 82% bounding-box labels, and compared the results to a baseline model trained on a completely pixel-perfect dataset. For the binary segmentation tasks, our method achieves an IoU score which is ~98.33% as good as our baseline model, while for the multi-class task, our method is 97.12% as good as our baseline model (77.5 vs. 79.8 mIoU).
Feed-Forward On-Edge Fine-tuning Using Static Synthetic Gradient Modules
Sep 21, 2020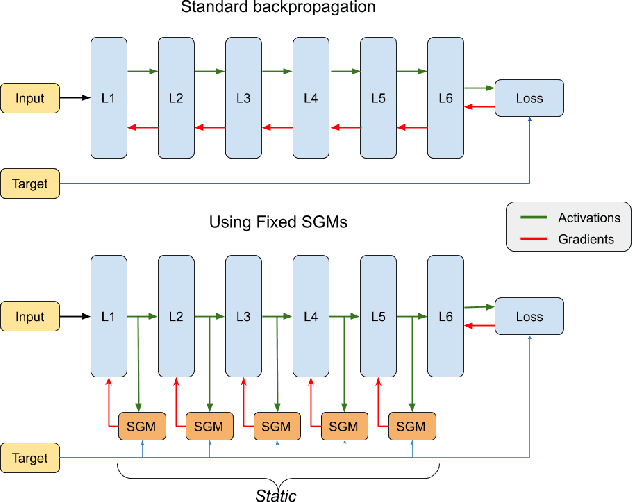
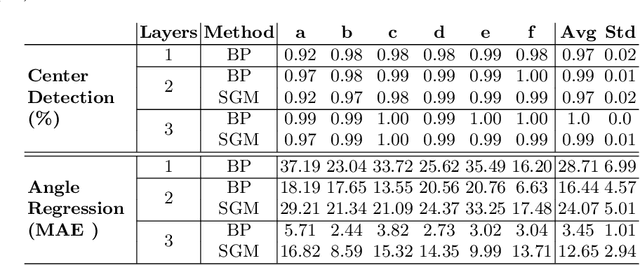
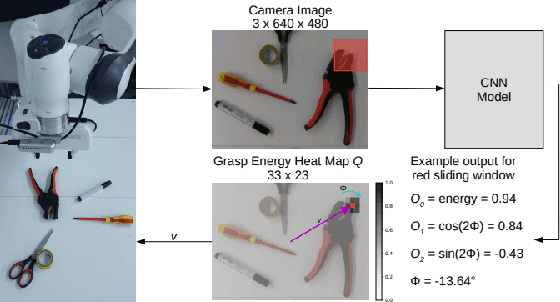
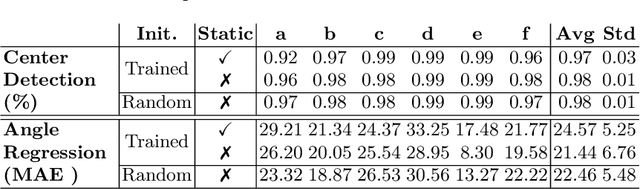
Training deep learning models on embedded devices is typically avoided since this requires more memory, computation and power over inference. In this work, we focus on lowering the amount of memory needed for storing all activations, which are required during the backward pass to compute the gradients. Instead, during the forward pass, static Synthetic Gradient Modules (SGMs) predict gradients for each layer. This allows training the model in a feed-forward manner without having to store all activations. We tested our method on a robot grasping scenario where a robot needs to learn to grasp new objects given only a single demonstration. By first training the SGMs in a meta-learning manner on a set of common objects, during fine-tuning, the SGMs provided the model with accurate gradients to successfully learn to grasp new objects. We have shown that our method has comparable results to using standard backpropagation.
Real-time Embedded Person Detection and Tracking for Shopping Behaviour Analysis
Jul 09, 2020

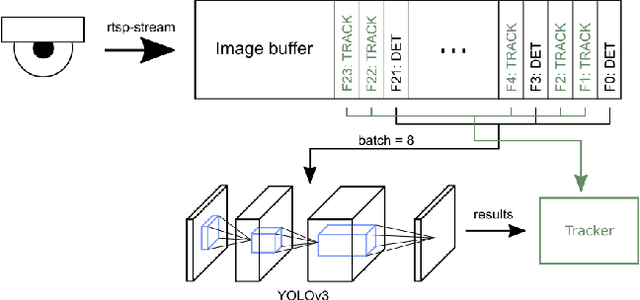

Shopping behaviour analysis through counting and tracking of people in shop-like environments offers valuable information for store operators and provides key insights in the stores layout (e.g. frequently visited spots). Instead of using extra staff for this, automated on-premise solutions are preferred. These automated systems should be cost-effective, preferably on lightweight embedded hardware, work in very challenging situations (e.g. handling occlusions) and preferably work real-time. We solve this challenge by implementing a real-time TensorRT optimized YOLOv3-based pedestrian detector, on a Jetson TX2 hardware platform. By combining the detector with a sparse optical flow tracker we assign a unique ID to each customer and tackle the problem of loosing partially occluded customers. Our detector-tracker based solution achieves an average precision of 81.59% at a processing speed of 10 FPS. Besides valuable statistics, heat maps of frequently visited spots are extracted and used as an overlay on the video stream.
Anyone here? Smart embedded low-resolution omnidirectional video sensor to measure room occupancy
Jul 09, 2020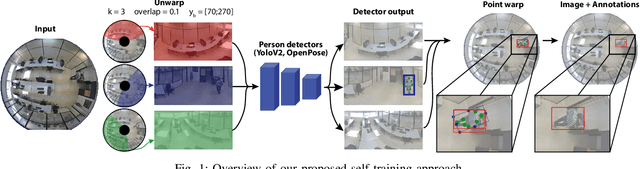


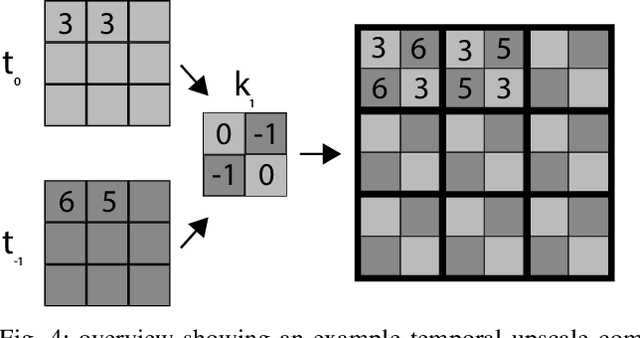
In this paper, we present a room occupancy sensing solution with unique properties: (i) It is based on an omnidirectional vision camera, capturing rich scene info over a wide angle, enabling to count the number of people in a room and even their position. (ii) Although it uses a camera-input, no privacy issues arise because its extremely low image resolution, rendering people unrecognisable. (iii) The neural network inference is running entirely on a low-cost processing platform embedded in the sensor, reducing the privacy risk even further. (iv) Limited manual data annotation is needed, because of the self-training scheme we propose. Such a smart room occupancy rate sensor can be used in e.g. meeting rooms and flex-desks. Indeed, by encouraging flex-desking, the required office space can be reduced significantly. In some cases, however, a flex-desk that has been reserved remains unoccupied without an update in the reservation system. A similar problem occurs with meeting rooms, which are often under-occupied. By optimising the occupancy rate a huge reduction in costs can be achieved. Therefore, in this paper, we develop such system which determines the number of people present in office flex-desks and meeting rooms. Using an omnidirectional camera mounted in the ceiling, combined with a person detector, the company can intelligently update the reservation system based on the measured occupancy. Next to the optimisation and embedded implementation of such a self-training omnidirectional people detection algorithm, in this work we propose a novel approach that combines spatial and temporal image data, improving performance of our system on extreme low-resolution images.
How low can you go? Privacy-preserving people detection with an omni-directional camera
Jul 09, 2020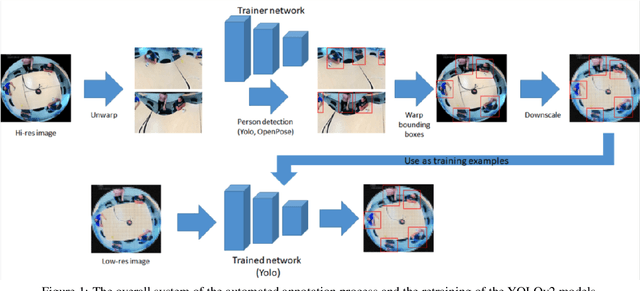

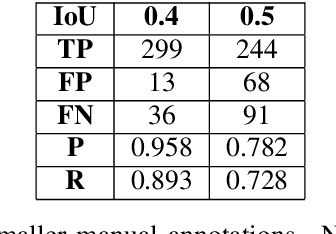
In this work, we use a ceiling-mounted omni-directional camera to detect people in a room. This can be used as a sensor to measure the occupancy of meeting rooms and count the amount of flex-desk working spaces available. If these devices can be integrated in an embedded low-power sensor, it would form an ideal extension of automated room reservation systems in office environments. The main challenge we target here is ensuring the privacy of the people filmed. The approach we propose is going to extremely low image resolutions, such that it is impossible to recognise people or read potentially confidential documents. Therefore, we retrained a single-shot low-resolution person detection network with automatically generated ground truth. In this paper, we prove the functionality of this approach and explore how low we can go in resolution, to determine the optimal trade-off between recognition accuracy and privacy preservation. Because of the low resolution, the result is a lightweight network that can potentially be deployed on embedded hardware. Such embedded implementation enables the development of a decentralised smart camera which only outputs the required meta-data (i.e. the number of persons in the meeting room).
Automated analysis of eye-tracker-based human-human interaction studies
Jul 09, 2020
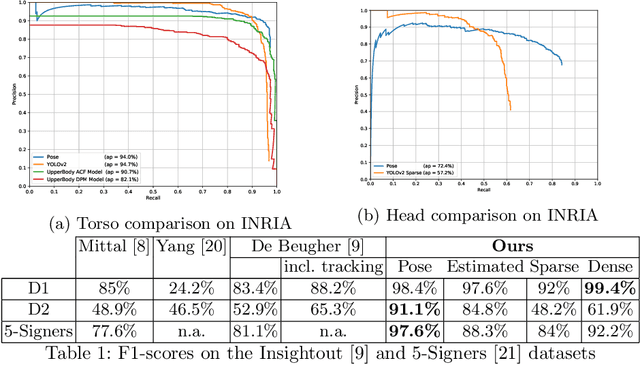
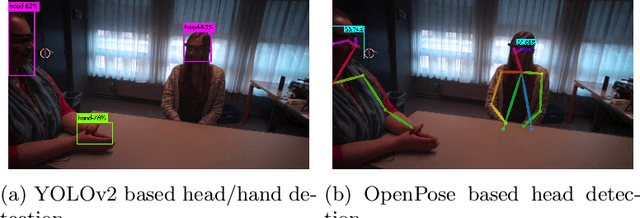

Mobile eye-tracking systems have been available for about a decade now and are becoming increasingly popular in different fields of application, including marketing, sociology, usability studies and linguistics. While the user-friendliness and ergonomics of the hardware are developing at a rapid pace, the software for the analysis of mobile eye-tracking data in some points still lacks robustness and functionality. With this paper, we investigate which state-of-the-art computer vision algorithms may be used to automate the post-analysis of mobile eye-tracking data. For the case study in this paper, we focus on mobile eye-tracker recordings made during human-human face-to-face interactions. We compared two recent publicly available frameworks (YOLOv2 and OpenPose) to relate the gaze location generated by the eye-tracker to the head and hands visible in the scene camera data. In this paper we will show that the use of this single-pipeline framework provides robust results, which are both more accurate and faster than previous work in the field. Moreover, our approach does not rely on manual interventions during this process.
Building Robust Industrial Applicable Object Detection Models Using Transfer Learning and Single Pass Deep Learning Architectures
Jul 09, 2020

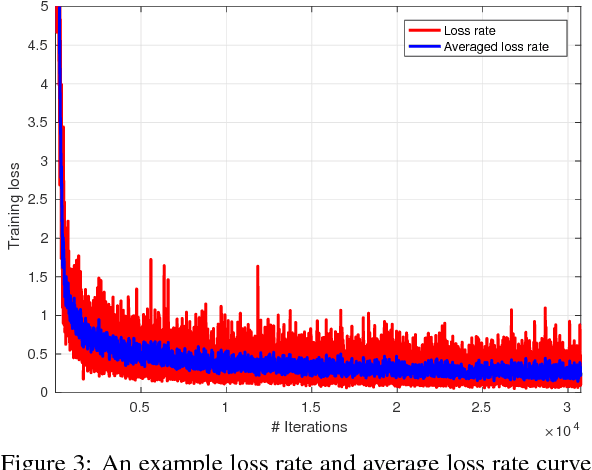
The uprising trend of deep learning in computer vision and artificial intelligence can simply not be ignored. On the most diverse tasks, from recognition and detection to segmentation, deep learning is able to obtain state-of-the-art results, reaching top notch performance. In this paper we explore how deep convolutional neural networks dedicated to the task of object detection can improve our industrial-oriented object detection pipelines, using state-of-the-art open source deep learning frameworks, like Darknet. By using a deep learning architecture that integrates region proposals, classification and probability estimation in a single run, we aim at obtaining real-time performance. We focus on reducing the needed amount of training data drastically by exploring transfer learning, while still maintaining a high average precision. Furthermore we apply these algorithms to two industrially relevant applications, one being the detection of promotion boards in eye tracking data and the other detecting and recognizing packages of warehouse products for augmented advertisements.
The autonomous hidden camera crew
Jul 09, 2020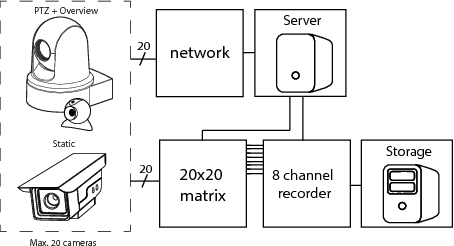
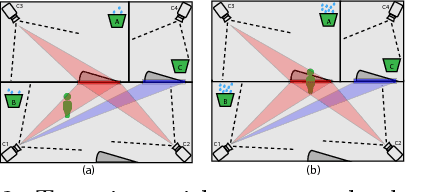

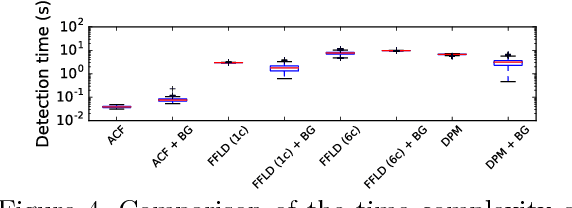
Reality TV shows that follow people in their day-to-day lives are not a new concept. However, the traditional methods used in the industry require a lot of manual labour and need the presence of at least one physical camera man. Because of this, the subjects tend to behave differently when they are aware of being recorded. This paper will present an approach to follow people in their day-to-day lives, for long periods of time (months to years), while being as unobtrusive as possible. To do this, we use unmanned cinematographically-aware cameras hidden in people's houses. Our contribution in this paper is twofold: First, we create a system to limit the amount of recorded data by intelligently controlling a video switch matrix, in combination with a multi-channel recorder. Second, we create a virtual camera man by controlling a PTZ camera to automatically make cinematographically pleasing shots. Throughout this paper, we worked closely with a real camera crew. This enabled us to compare the results of our system to the work of trained professionals.