 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Latent Diffusion Approach for Panoptic Segmentation and Mask Inpainting
Jan 18, 2024



Panoptic and instance segmentation networks are often trained with specialized object detection modules, complex loss functions, and ad-hoc post-processing steps to handle the permutation-invariance of the instance masks. This work builds upon Stable Diffusion and proposes a latent diffusion approach for panoptic segmentation, resulting in a simple architecture which omits these complexities. Our training process consists of two steps: (1) training a shallow autoencoder to project the segmentation masks to latent space; (2) training a diffusion model to allow image-conditioned sampling in latent space. The use of a generative model unlocks the exploration of mask completion or inpainting, which has applications in interactive segmentation. The experimental validation yields promising results for both panoptic segmentation and mask inpainting. While not setting a new state-of-the-art, our model's simplicity, generality, and mask completion capability are desirable properties.
Weakly-Supervised Semantic Segmentation by Learning Label Uncertainty
Oct 12, 2021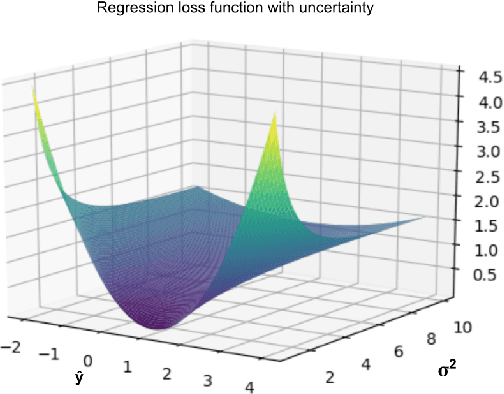
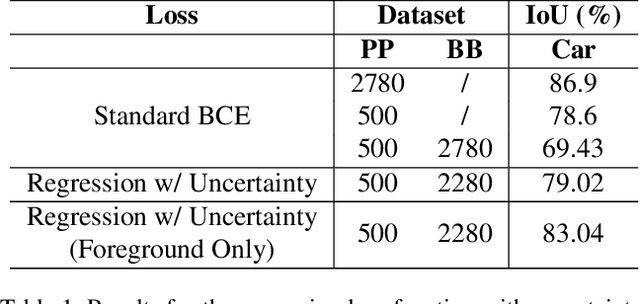

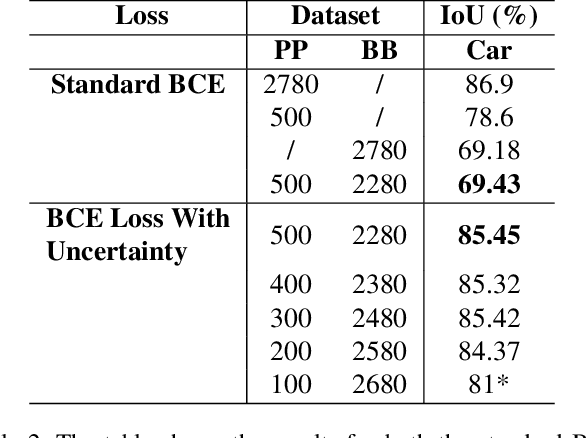
Since the rise of deep learning, many computer vision tasks have seen significant advancements. However, the downside of deep learning is that it is very data-hungry. Especially for segmentation problems, training a deep neural net requires dense supervision in the form of pixel-perfect image labels, which are very costly. In this paper, we present a new loss function to train a segmentation network with only a small subset of pixel-perfect labels, but take the advantage of weakly-annotated training samples in the form of cheap bounding-box labels. Unlike recent works which make use of box-to-mask proposal generators, our loss trains the network to learn a label uncertainty within the bounding-box, which can be leveraged to perform online bootstrapping (i.e. transforming the boxes to segmentation masks), while training the network. We evaluated our method on binary segmentation tasks, as well as a multi-class segmentation task (CityScapes vehicles and persons). We trained each task on a dataset comprised of only 18% pixel-perfect and 82% bounding-box labels, and compared the results to a baseline model trained on a completely pixel-perfect dataset. For the binary segmentation tasks, our method achieves an IoU score which is ~98.33% as good as our baseline model, while for the multi-class task, our method is 97.12% as good as our baseline model (77.5 vs. 79.8 mIoU).
Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth
Aug 02, 2019
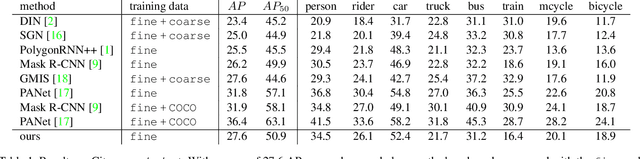
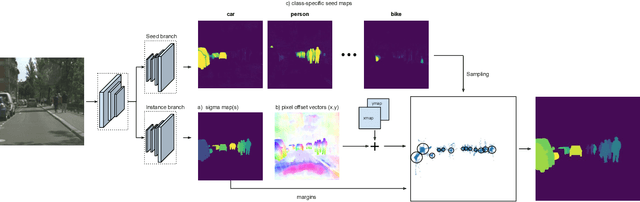

Current state-of-the-art instance segmentation methods are not suited for real-time applications like autonomous driving, which require fast execution times at high accuracy. Although the currently dominant proposal-based methods have high accuracy, they are slow and generate masks at a fixed and low resolution. Proposal-free methods, by contrast, can generate masks at high resolution and are often faster, but fail to reach the same accuracy as the proposal-based methods. In this work we propose a new clustering loss function for proposal-free instance segmentation. The loss function pulls the spatial embeddings of pixels belonging to the same instance together and jointly learns an instance-specific clustering bandwidth, maximizing the intersection-over-union of the resulting instance mask. When combined with a fast architecture, the network can perform instance segmentation in real-time while maintaining a high accuracy. We evaluate our method on the challenging Cityscapes benchmark and achieve top results (5\% improvement over Mask R-CNN) at more than 10 fps on 2MP images. Code will be available at https://github.com/davyneven/SpatialEmbeddings .
Branched Multi-Task Networks: Deciding What Layers To Share
Apr 05, 2019

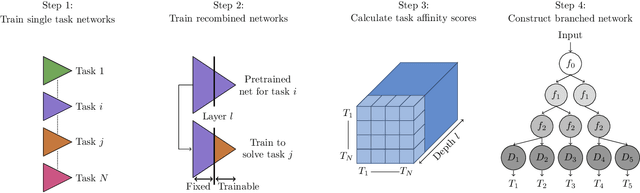

In the context of deep learning, neural networks with multiple branches have been used that each solve different tasks. Such ramified networks typically start with a number of shared layers, after which different tasks branch out into their own sequence of layers. As the number of possible network configurations is combinatorially large, prior work has often relied on ad hoc methods to determine the level of layer sharing. This work proposes a novel method to assess the relatedness of tasks in a principled way. We base the relatedness of a task pair on the usefulness of a set of features of one task for the other, and vice versa. The resulting task affinities are used for the automated construction of a branched multi-task network in which deeper layers gradually grow more task-specific. Our multi-task network outperforms the state-of-the-art on CelebA. Additionally, the layer sharing schemes devised by our method outperform common multi-task learning models which were constructed ad hoc. We include additional experiments on Cityscapes and SUN RGB-D to illustrate the wide applicability of our approach. Code and trained models for this paper are made available https://github.com/SimonVandenhende/
A Three-Player GAN: Generating Hard Samples To Improve Classification Networks
Mar 08, 2019



We propose a Three-Player Generative Adversarial Network to improve classification networks. In addition to the game played between the discriminator and generator, a competition is introduced between the generator and the classifier. The generator's objective is to synthesize samples that are both realistic and hard to label for the classifier. Even though we make no assumptions on the type of augmentations to learn, we find that the model is able to synthesize realistically looking examples that are hard for the classification model. Furthermore, the classifier becomes more robust when trained on these difficult samples. The method is evaluated on a public dataset for traffic sign recognition.
Sparse and noisy LiDAR completion with RGB guidance and uncertainty
Feb 14, 2019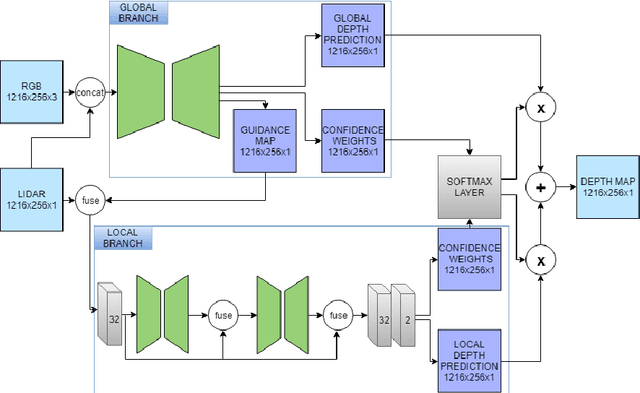
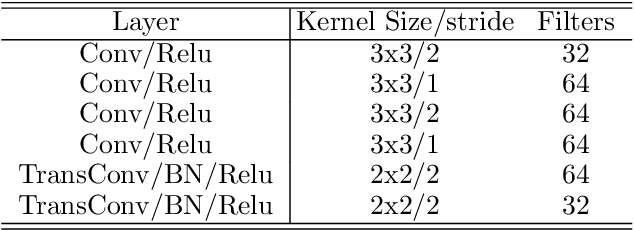
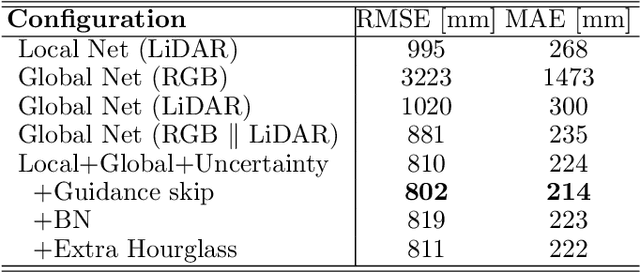
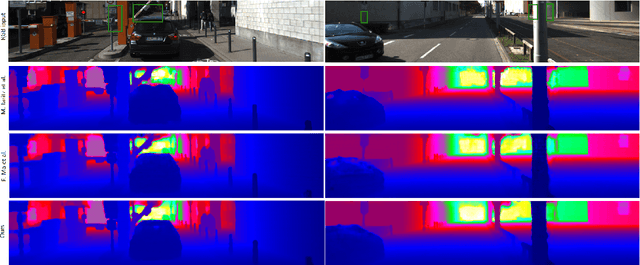
This work proposes a new method to accurately complete sparse LiDAR maps guided by RGB images. For autonomous vehicles and robotics the use of LiDAR is indispensable in order to achieve precise depth predictions. A multitude of applications depend on the awareness of their surroundings, and use depth cues to reason and react accordingly. On the one hand, monocular depth prediction methods fail to generate absolute and precise depth maps. On the other hand, stereoscopic approaches are still significantly outperformed by LiDAR based approaches. The goal of the depth completion task is to generate dense depth predictions from sparse and irregular point clouds which are mapped to a 2D plane. We propose a new framework which extracts both global and local information in order to produce proper depth maps. We argue that simple depth completion does not require a deep network. However, we additionally propose a fusion method with RGB guidance from a monocular camera in order to leverage object information and to correct mistakes in the sparse input. This improves the accuracy significantly. Moreover, confidence masks are exploited in order to take into account the uncertainty in the depth predictions from each modality. This fusion method outperforms the state-of-the-art and ranks first on the KITTI depth completion benchmark. Our code with visualizations is available.
End-to-end Lane Detection through Differentiable Least-Squares Fitting
Feb 01, 2019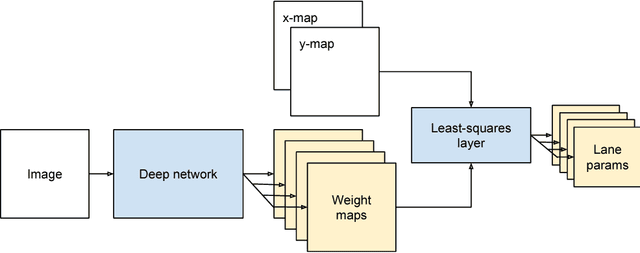
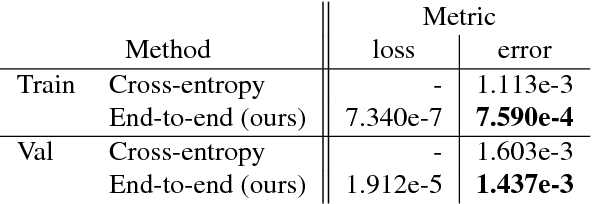
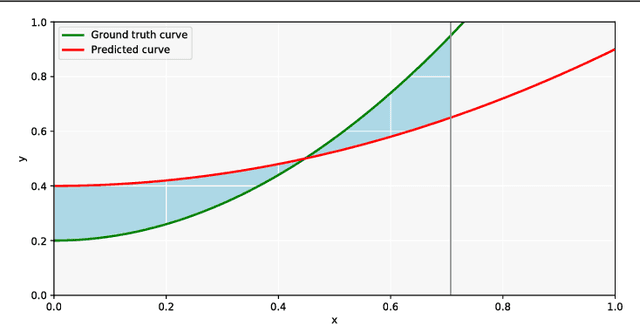
Lane detection is typically tackled with a two-step pipeline in which a segmentation mask of the lane markings is predicted first, and a lane line model (like a parabola or spline) is fitted to the post-processed mask next. The problem with such a two-step approach is that the parameters of the network are not optimized for the true task of interest (estimating the lane curvature parameters) but for a proxy task (segmenting the lane markings), resulting in sub-optimal performance. In this work, we propose a method to train a lane detector in an end-to-end manner, directly regressing the lane parameters. The architecture consists of two components: a deep network that predicts a segmentation-like weight map for each lane line, and a differentiable least-squares fitting module that returns for each map the parameters of the best-fitting curve in the weighted least-squares sense. These parameters can subsequently be supervised with a loss function of choice. Our method relies on the observation that it is possible to backpropagate through a least-squares fitting procedure. This leads to an end-to-end method where the features are optimized for the true task of interest: the network implicitly learns to generate features that prevent instabilities during the model fitting step, as opposed to two-step pipelines that need to handle outliers with heuristics. Additionally, the system is not just a black box but offers a degree of interpretability because the intermediately generated segmentation-like weight maps can be inspected and visualized. Code and a video is available at github.com/wvangansbeke/LaneDetection_End2End.
Towards End-to-End Lane Detection: an Instance Segmentation Approach
Feb 15, 2018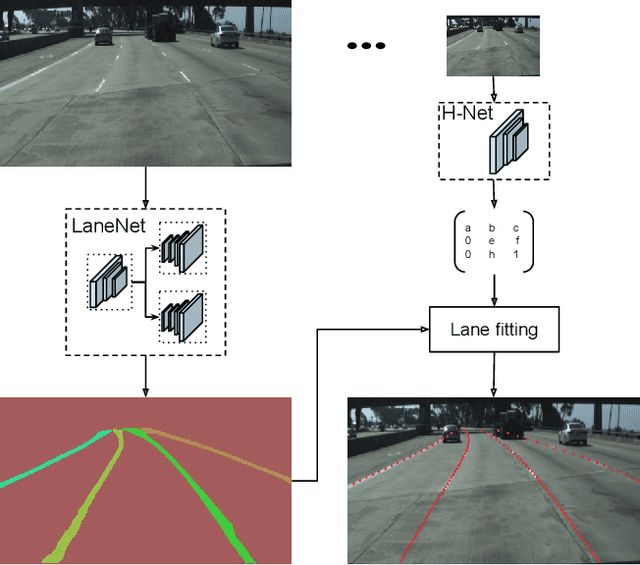

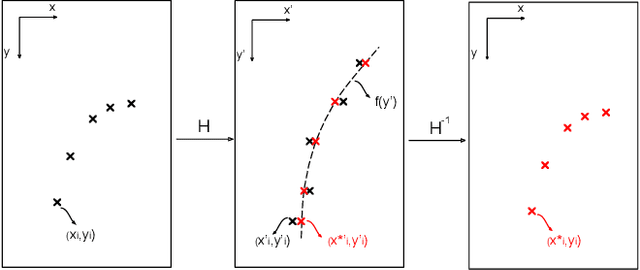

Modern cars are incorporating an increasing number of driver assist features, among which automatic lane keeping. The latter allows the car to properly position itself within the road lanes, which is also crucial for any subsequent lane departure or trajectory planning decision in fully autonomous cars. Traditional lane detection methods rely on a combination of highly-specialized, hand-crafted features and heuristics, usually followed by post-processing techniques, that are computationally expensive and prone to scalability due to road scene variations. More recent approaches leverage deep learning models, trained for pixel-wise lane segmentation, even when no markings are present in the image due to their big receptive field. Despite their advantages, these methods are limited to detecting a pre-defined, fixed number of lanes, e.g. ego-lanes, and can not cope with lane changes. In this paper, we go beyond the aforementioned limitations and propose to cast the lane detection problem as an instance segmentation problem - in which each lane forms its own instance - that can be trained end-to-end. To parametrize the segmented lane instances before fitting the lane, we further propose to apply a learned perspective transformation, conditioned on the image, in contrast to a fixed "bird's-eye view" transformation. By doing so, we ensure a lane fitting which is robust against road plane changes, unlike existing approaches that rely on a fixed, pre-defined transformation. In summary, we propose a fast lane detection algorithm, running at 50 fps, which can handle a variable number of lanes and cope with lane changes. We verify our method on the tuSimple dataset and achieve competitive results.
Semantic Instance Segmentation with a Discriminative Loss Function
Aug 08, 2017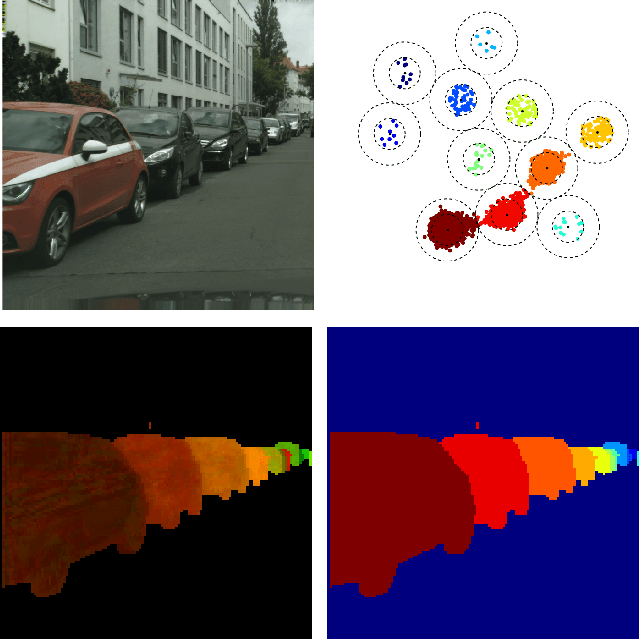



Semantic instance segmentation remains a challenging task. In this work we propose to tackle the problem with a discriminative loss function, operating at the pixel level, that encourages a convolutional network to produce a representation of the image that can easily be clustered into instances with a simple post-processing step. The loss function encourages the network to map each pixel to a point in feature space so that pixels belonging to the same instance lie close together while different instances are separated by a wide margin. Our approach of combining an off-the-shelf network with a principled loss function inspired by a metric learning objective is conceptually simple and distinct from recent efforts in instance segmentation. In contrast to previous works, our method does not rely on object proposals or recurrent mechanisms. A key contribution of our work is to demonstrate that such a simple setup without bells and whistles is effective and can perform on par with more complex methods. Moreover, we show that it does not suffer from some of the limitations of the popular detect-and-segment approaches. We achieve competitive performance on the Cityscapes and CVPPP leaf segmentation benchmarks.
Fast Scene Understanding for Autonomous Driving
Aug 08, 2017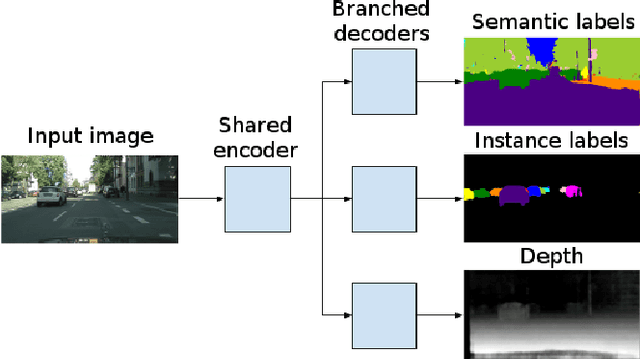

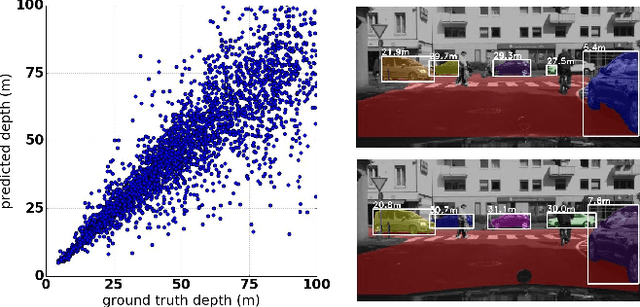
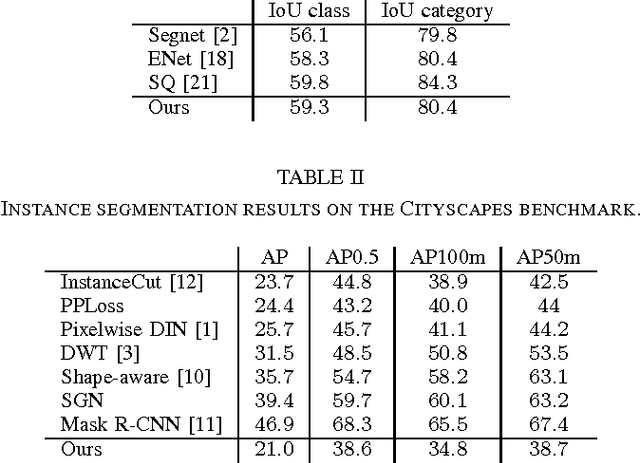
Most approaches for instance-aware semantic labeling traditionally focus on accuracy. Other aspects like runtime and memory footprint are arguably as important for real-time applications such as autonomous driving. Motivated by this observation and inspired by recent works that tackle multiple tasks with a single integrated architecture, in this paper we present a real-time efficient implementation based on ENet that solves three autonomous driving related tasks at once: semantic scene segmentation, instance segmentation and monocular depth estimation. Our approach builds upon a branched ENet architecture with a shared encoder but different decoder branches for each of the three tasks. The presented method can run at 21 fps at a resolution of 1024x512 on the Cityscapes dataset without sacrificing accuracy compared to running each task separately.