 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse and noisy LiDAR completion with RGB guidance and uncertainty
Paper and Code
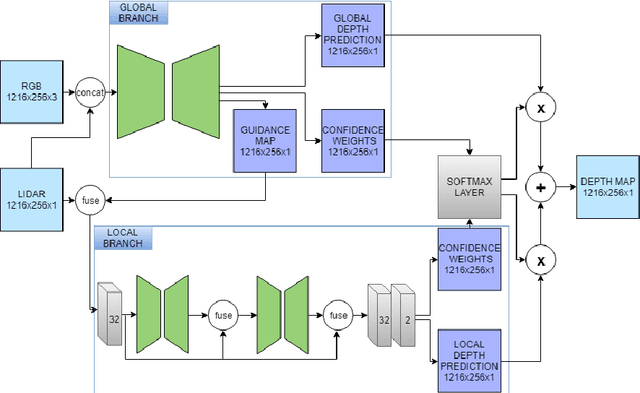
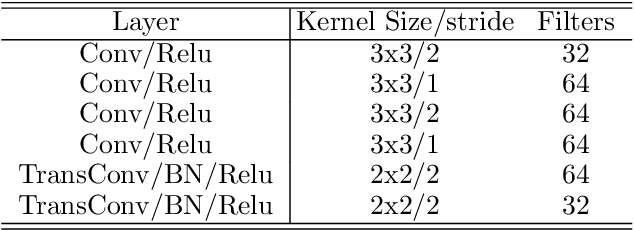
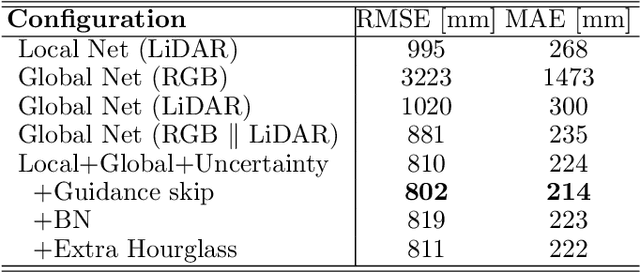
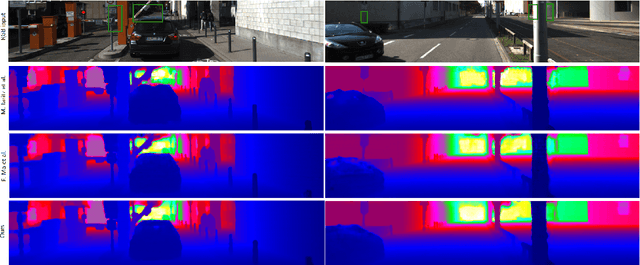
This work proposes a new method to accurately complete sparse LiDAR maps guided by RGB images. For autonomous vehicles and robotics the use of LiDAR is indispensable in order to achieve precise depth predictions. A multitude of applications depend on the awareness of their surroundings, and use depth cues to reason and react accordingly. On the one hand, monocular depth prediction methods fail to generate absolute and precise depth maps. On the other hand, stereoscopic approaches are still significantly outperformed by LiDAR based approaches. The goal of the depth completion task is to generate dense depth predictions from sparse and irregular point clouds which are mapped to a 2D plane. We propose a new framework which extracts both global and local information in order to produce proper depth maps. We argue that simple depth completion does not require a deep network. However, we additionally propose a fusion method with RGB guidance from a monocular camera in order to leverage object information and to correct mistakes in the sparse input. This improves the accuracy significantly. Moreover, confidence masks are exploited in order to take into account the uncertainty in the depth predictions from each modality. This fusion method outperforms the state-of-the-art and ranks first on the KITTI depth completion benchmark. Our code with visualizations is available.