 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Generalist Approach for Panoptic Segmentation
Aug 29, 2024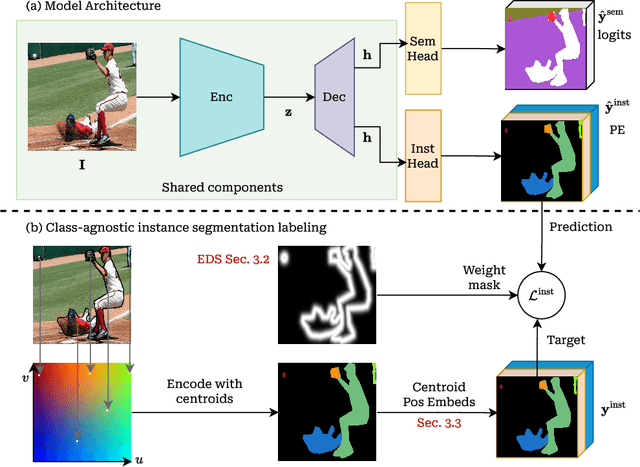
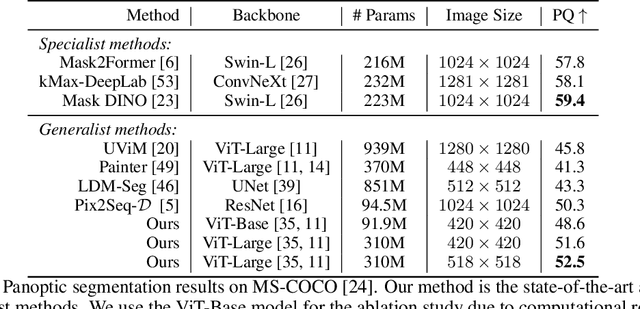
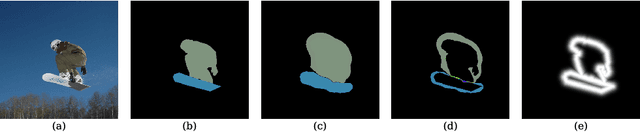

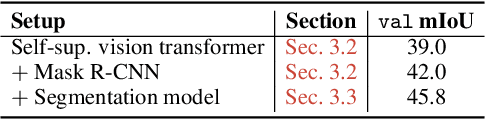
Generalist vision models aim for one and the same architecture for a variety of vision tasks. While such shared architecture may seem attractive, generalist models tend to be outperformed by their bespoken counterparts, especially in the case of panoptic segmentation. We address this problem by introducing two key contributions, without compromising the desirable properties of generalist models. These contributions are: (i) a positional-embedding (PE) based loss for improved centroid regressions; (ii) Edge Distance Sampling (EDS) for the better separation of instance boundaries. The PE-based loss facilitates a better per-pixel regression of the associated instance's centroid, whereas EDS contributes by carefully handling the void regions (caused by missing labels) and smaller instances. These two simple yet effective modifications significantly improve established baselines, while achieving state-of-the-art results among all generalist solutions. More specifically, our method achieves a panoptic quality(PQ) of 52.5 on the COCO dataset, which is an improvement of 10 points over the best model with similar approach (Painter), and is superior by 2 to the best performing diffusion-based method Pix2Seq-$\mathcal{D}$. Furthermore, we provide insights into and an in-depth analysis of our contributions through exhaustive experiments. Our source code and model weights will be made publicly available.
Investigating the Effectiveness of Cross-Attention to Unlock Zero-Shot Editing of Text-to-Video Diffusion Models
Apr 08, 2024



With recent advances in image and video diffusion models for content creation, a plethora of techniques have been proposed for customizing their generated content. In particular, manipulating the cross-attention layers of Text-to-Image (T2I) diffusion models has shown great promise in controlling the shape and location of objects in the scene. Transferring image-editing techniques to the video domain, however, is extremely challenging as object motion and temporal consistency are difficult to capture accurately. In this work, we take a first look at the role of cross-attention in Text-to-Video (T2V) diffusion models for zero-shot video editing. While one-shot models have shown potential in controlling motion and camera movement, we demonstrate zero-shot control over object shape, position and movement in T2V models. We show that despite the limitations of current T2V models, cross-attention guidance can be a promising approach for editing videos.
A Simple Latent Diffusion Approach for Panoptic Segmentation and Mask Inpainting
Jan 18, 2024



Panoptic and instance segmentation networks are often trained with specialized object detection modules, complex loss functions, and ad-hoc post-processing steps to handle the permutation-invariance of the instance masks. This work builds upon Stable Diffusion and proposes a latent diffusion approach for panoptic segmentation, resulting in a simple architecture which omits these complexities. Our training process consists of two steps: (1) training a shallow autoencoder to project the segmentation masks to latent space; (2) training a diffusion model to allow image-conditioned sampling in latent space. The use of a generative model unlocks the exploration of mask completion or inpainting, which has applications in interactive segmentation. The experimental validation yields promising results for both panoptic segmentation and mask inpainting. While not setting a new state-of-the-art, our model's simplicity, generality, and mask completion capability are desirable properties.
Discovering Object Masks with Transformers for Unsupervised Semantic Segmentation
Jun 13, 2022
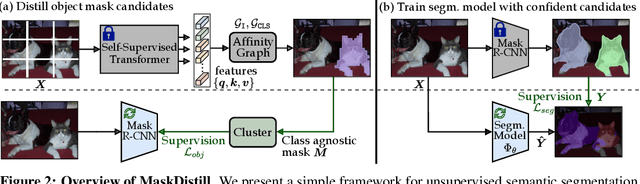
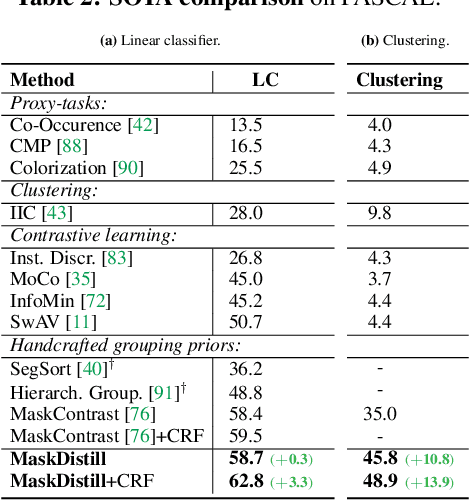
The task of unsupervised semantic segmentation aims to cluster pixels into semantically meaningful groups. Specifically, pixels assigned to the same cluster should share high-level semantic properties like their object or part category. This paper presents MaskDistill: a novel framework for unsupervised semantic segmentation based on three key ideas. First, we advocate a data-driven strategy to generate object masks that serve as a pixel grouping prior for semantic segmentation. This approach omits handcrafted priors, which are often designed for specific scene compositions and limit the applicability of competing frameworks. Second, MaskDistill clusters the object masks to obtain pseudo-ground-truth for training an initial object segmentation model. Third, we leverage this model to filter out low-quality object masks. This strategy mitigates the noise in our pixel grouping prior and results in a clean collection of masks which we use to train a final segmentation model. By combining these components, we can considerably outperform previous works for unsupervised semantic segmentation on PASCAL (+11% mIoU) and COCO (+4% mask AP50). Interestingly, as opposed to existing approaches, our framework does not latch onto low-level image cues and is not limited to object-centric datasets. The code and models will be made available.
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations
Jun 10, 2021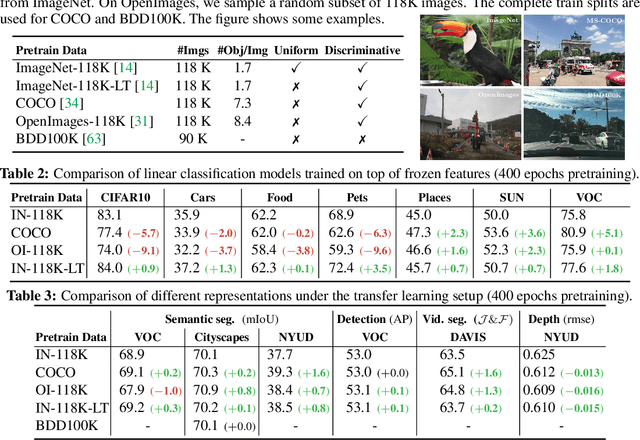
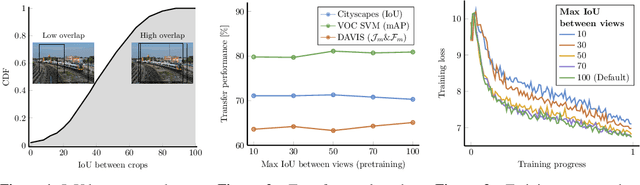
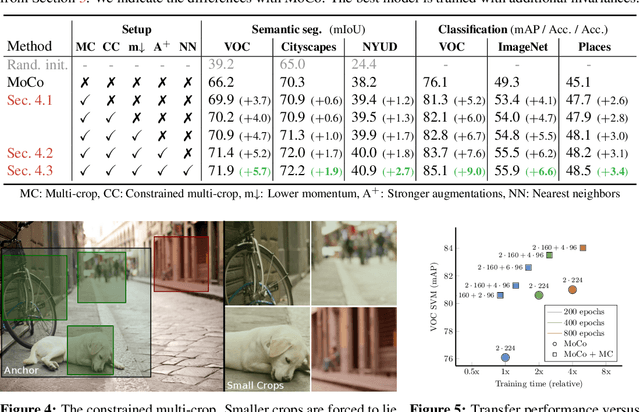
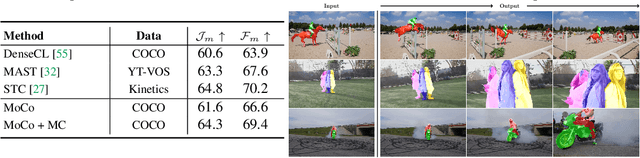
Contrastive self-supervised learning has outperformed supervised pretraining on many downstream tasks like segmentation and object detection. However, current methods are still primarily applied to curated datasets like ImageNet. In this paper, we first study how biases in the dataset affect existing methods. Our results show that current contrastive approaches work surprisingly well across: (i) object- versus scene-centric, (ii) uniform versus long-tailed and (iii) general versus domain-specific datasets. Second, given the generality of the approach, we try to realize further gains with minor modifications. We show that learning additional invariances -- through the use of multi-scale cropping, stronger augmentations and nearest neighbors -- improves the representations. Finally, we observe that MoCo learns spatially structured representations when trained with a multi-crop strategy. The representations can be used for semantic segment retrieval and video instance segmentation without finetuning. Moreover, the results are on par with specialized models. We hope this work will serve as a useful study for other researchers. The code and models will be available at https://github.com/wvangansbeke/Revisiting-Contrastive-SSL.
Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
Feb 11, 2021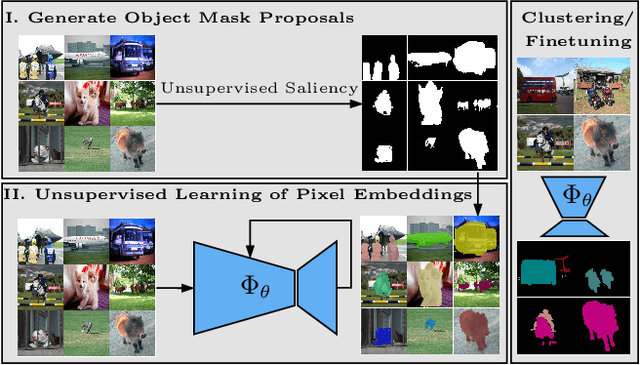
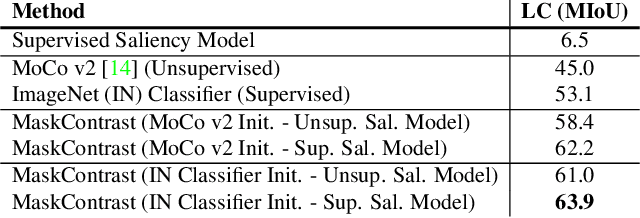
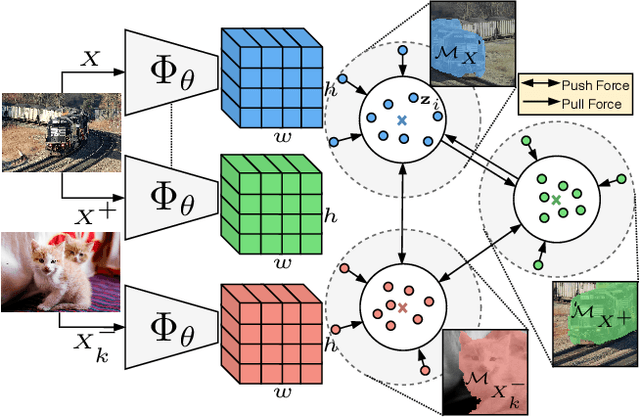

Being able to learn dense semantic representations of images without supervision is an important problem in computer vision. However, despite its significance, this problem remains rather unexplored, with a few exceptions that considered unsupervised semantic segmentation on small-scale datasets with a narrow visual domain. In this paper, we make a first attempt to tackle the problem on datasets that have been traditionally utilized for the supervised case. To achieve this, we introduce a novel two-step framework that adopts a predetermined prior in a contrastive optimization objective to learn pixel embeddings. This marks a large deviation from existing works that relied on proxy tasks or end-to-end clustering. Additionally, we argue about the importance of having a prior that contains information about objects, or their parts, and discuss several possibilities to obtain such a prior in an unsupervised manner. Extensive experimental evaluation shows that the proposed method comes with key advantages over existing works. First, the learned pixel embeddings can be directly clustered in semantic groups using K-Means. Second, the method can serve as an effective unsupervised pre-training for the semantic segmentation task. In particular, when fine-tuning the learned representations using just 1% of labeled examples on PASCAL, we outperform supervised ImageNet pre-training by 7.1% mIoU. The code is available at https://github.com/wvangansbeke/Unsupervised-Semantic-Segmentation.
Learning To Classify Images Without Labels
May 25, 2020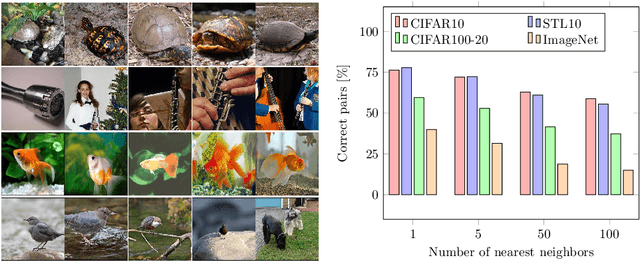
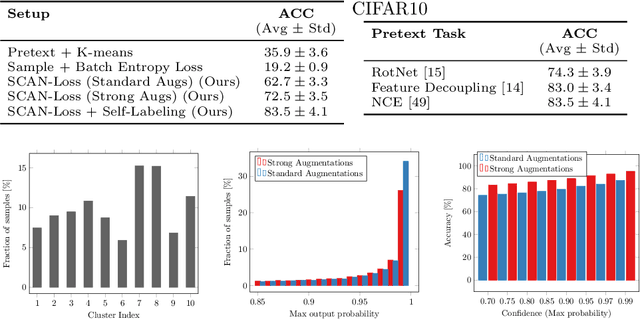
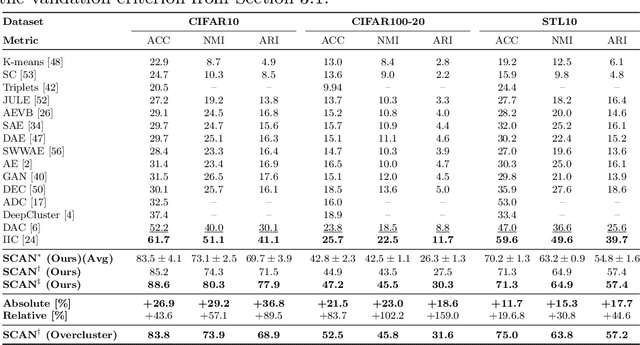
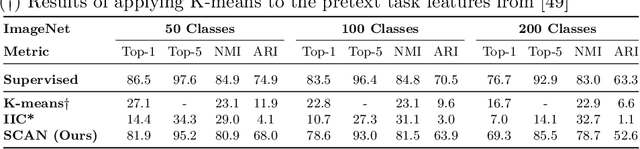
Is it possible to automatically classify images without the use of ground-truth annotations? Or when even the classes themselves, are not a priori known? These remain important, and open questions in computer vision. Several approaches have tried to tackle this problem in an end-to-end fashion. In this paper, we deviate from recent works, and advocate a two-step approach where feature learning and clustering are decoupled. First, a self-supervised task from representation learning is employed to obtain semantically meaningful features. Second, we use the obtained features as a prior in a learnable clustering approach. In doing so, we remove the ability for cluster learning to depend on low-level features, which is present in current end-to-end learning approaches. Experimental evaluation shows that we outperform state-of-the-art methods by huge margins, in particular +26.9% on CIFAR10, +21.5% on CIFAR100-20 and +11.7% on STL10 in terms of classification accuracy. Furthermore, results on ImageNet show that our approach is the first to scale well up to 200 randomly selected classes, obtaining 69.3% top-1 and 85.5% top-5 accuracy, and marking a difference of less than 7.5% with fully-supervised methods. Finally, we applied our approach to all 1000 classes on ImageNet, and found the results to be very encouraging. The code will be made publicly available.
Don't Forget The Past: Recurrent Depth Estimation from Monocular Video
Jan 08, 2020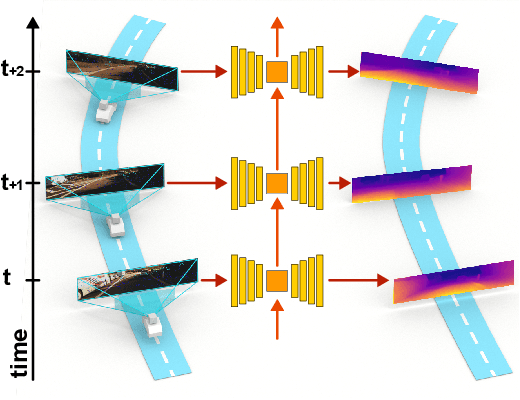
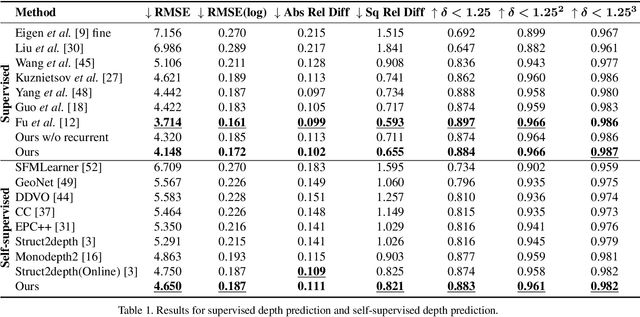
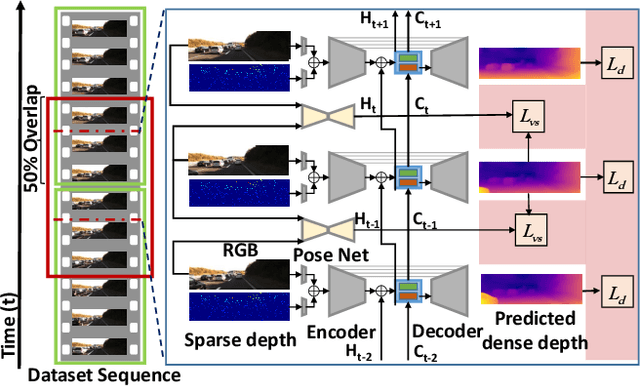
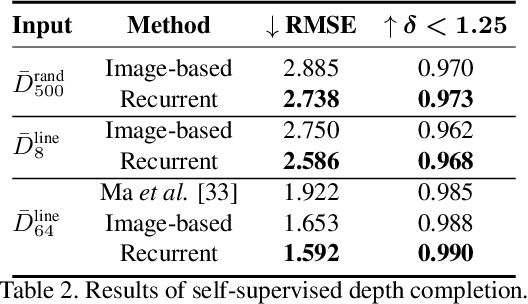
Autonomous cars need continuously updated depth information. Thus far, the depth is mostly estimated independently for a single frame at a time, even if the method starts from video input. Our method produces a time series of depth maps, which makes it an ideal candidate for online learning approaches. In particular, we put three different types of depth estimation (supervised depth prediction, self-supervised depth prediction, and self-supervised depth completion) into a common framework. We integrate the corresponding networks with a convolutional LSTM such that the spatiotemporal structures of depth across frames can be exploited to yield a more accurate depth estimation. Our method is flexible. It can be applied to monocular videos only or be combined with different types of sparse depth patterns. We carefully study the architecture of the recurrent network and its training strategy. We are first to successfully exploit recurrent networks for real-time self-supervised monocular depth estimation and completion. Extensive experiments show that our recurrent method outperforms its image-based counterpart consistently and significantly in both self-supervised scenarios. It also outperforms previous depth estimation methods of the three popular groups.
Sparse and noisy LiDAR completion with RGB guidance and uncertainty
Feb 14, 2019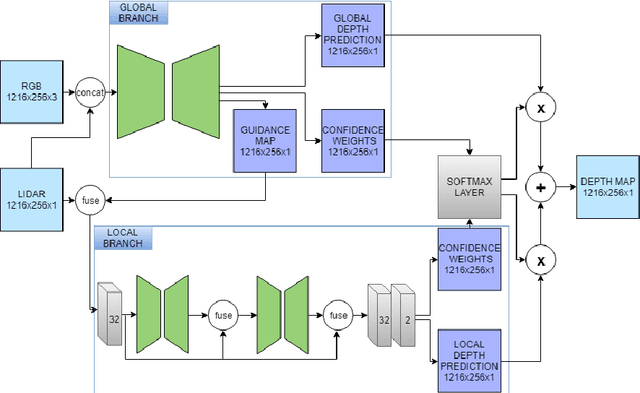
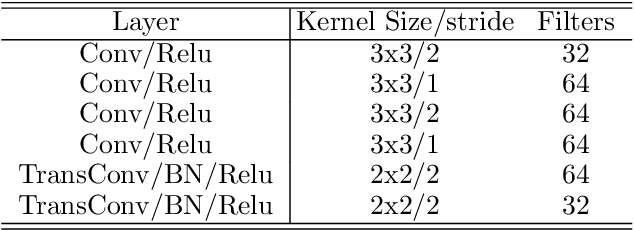
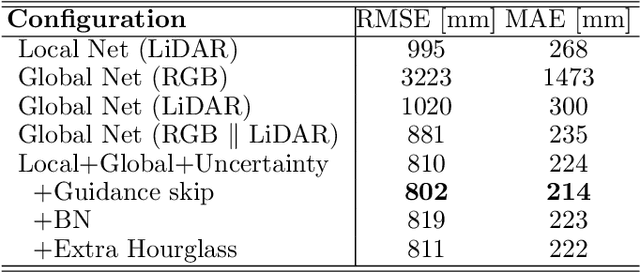
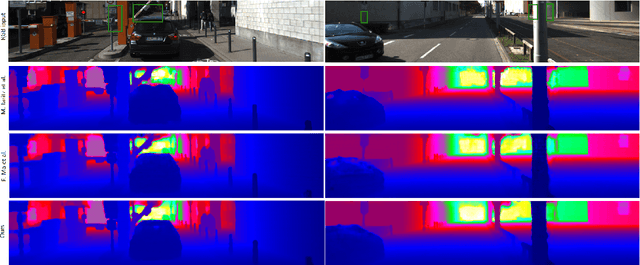
This work proposes a new method to accurately complete sparse LiDAR maps guided by RGB images. For autonomous vehicles and robotics the use of LiDAR is indispensable in order to achieve precise depth predictions. A multitude of applications depend on the awareness of their surroundings, and use depth cues to reason and react accordingly. On the one hand, monocular depth prediction methods fail to generate absolute and precise depth maps. On the other hand, stereoscopic approaches are still significantly outperformed by LiDAR based approaches. The goal of the depth completion task is to generate dense depth predictions from sparse and irregular point clouds which are mapped to a 2D plane. We propose a new framework which extracts both global and local information in order to produce proper depth maps. We argue that simple depth completion does not require a deep network. However, we additionally propose a fusion method with RGB guidance from a monocular camera in order to leverage object information and to correct mistakes in the sparse input. This improves the accuracy significantly. Moreover, confidence masks are exploited in order to take into account the uncertainty in the depth predictions from each modality. This fusion method outperforms the state-of-the-art and ranks first on the KITTI depth completion benchmark. Our code with visualizations is available.
End-to-end Lane Detection through Differentiable Least-Squares Fitting
Feb 01, 2019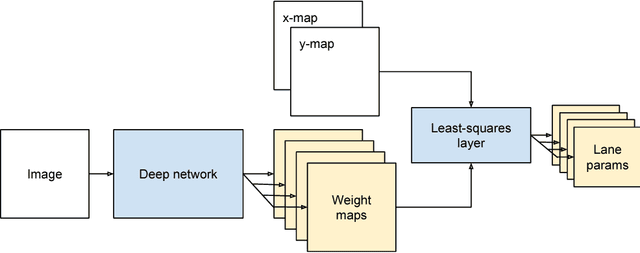
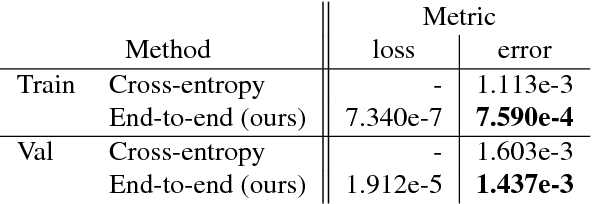
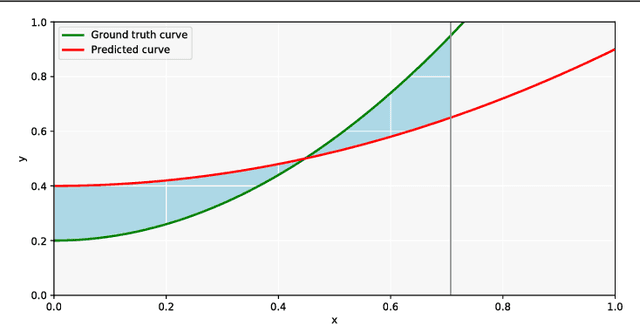
Lane detection is typically tackled with a two-step pipeline in which a segmentation mask of the lane markings is predicted first, and a lane line model (like a parabola or spline) is fitted to the post-processed mask next. The problem with such a two-step approach is that the parameters of the network are not optimized for the true task of interest (estimating the lane curvature parameters) but for a proxy task (segmenting the lane markings), resulting in sub-optimal performance. In this work, we propose a method to train a lane detector in an end-to-end manner, directly regressing the lane parameters. The architecture consists of two components: a deep network that predicts a segmentation-like weight map for each lane line, and a differentiable least-squares fitting module that returns for each map the parameters of the best-fitting curve in the weighted least-squares sense. These parameters can subsequently be supervised with a loss function of choice. Our method relies on the observation that it is possible to backpropagate through a least-squares fitting procedure. This leads to an end-to-end method where the features are optimized for the true task of interest: the network implicitly learns to generate features that prevent instabilities during the model fitting step, as opposed to two-step pipelines that need to handle outliers with heuristics. Additionally, the system is not just a black box but offers a degree of interpretability because the intermediately generated segmentation-like weight maps can be inspected and visualized. Code and a video is available at github.com/wvangansbeke/LaneDetection_End2End.