 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Instance Segmentation with a Discriminative Loss Function
Paper and Code
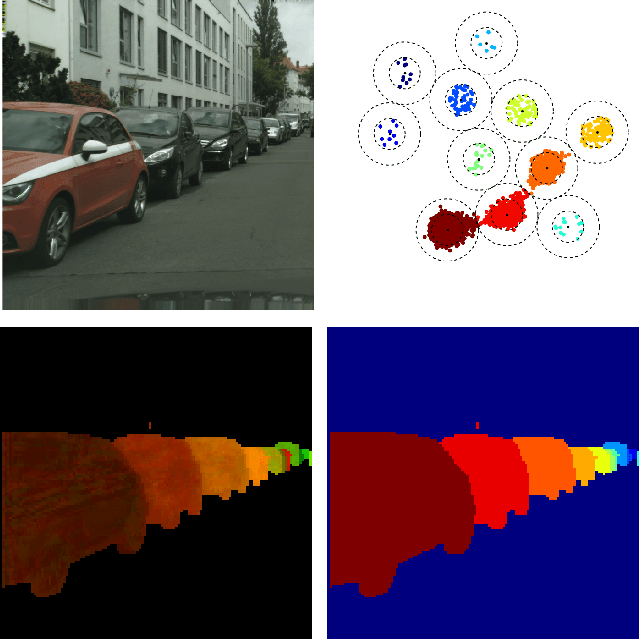



Semantic instance segmentation remains a challenging task. In this work we propose to tackle the problem with a discriminative loss function, operating at the pixel level, that encourages a convolutional network to produce a representation of the image that can easily be clustered into instances with a simple post-processing step. The loss function encourages the network to map each pixel to a point in feature space so that pixels belonging to the same instance lie close together while different instances are separated by a wide margin. Our approach of combining an off-the-shelf network with a principled loss function inspired by a metric learning objective is conceptually simple and distinct from recent efforts in instance segmentation. In contrast to previous works, our method does not rely on object proposals or recurrent mechanisms. A key contribution of our work is to demonstrate that such a simple setup without bells and whistles is effective and can perform on par with more complex methods. Moreover, we show that it does not suffer from some of the limitations of the popular detect-and-segment approaches. We achieve competitive performance on the Cityscapes and CVPPP leaf segmentation benchmarks.