 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual Formulation for Probabilistic Principal Component Analysis
Jul 19, 2023In this paper, we characterize Probabilistic Principal Component Analysis in Hilbert spaces and demonstrate how the optimal solution admits a representation in dual space. This allows us to develop a generative framework for kernel methods. Furthermore, we show how it englobes Kernel Principal Component Analysis and illustrate its working on a toy and a real dataset.
Unbalanced Optimal Transport: A Unified Framework for Object Detection
Jul 05, 2023During training, supervised object detection tries to correctly match the predicted bounding boxes and associated classification scores to the ground truth. This is essential to determine which predictions are to be pushed towards which solutions, or to be discarded. Popular matching strategies include matching to the closest ground truth box (mostly used in combination with anchors), or matching via the Hungarian algorithm (mostly used in anchor-free methods). Each of these strategies comes with its own properties, underlying losses, and heuristics. We show how Unbalanced Optimal Transport unifies these different approaches and opens a whole continuum of methods in between. This allows for a finer selection of the desired properties. Experimentally, we show that training an object detection model with Unbalanced Optimal Transport is able to reach the state-of-the-art both in terms of Average Precision and Average Recall as well as to provide a faster initial convergence. The approach is well suited for GPU implementation, which proves to be an advantage for large-scale models.
Wasserstein Exponential Kernels
Feb 05, 2020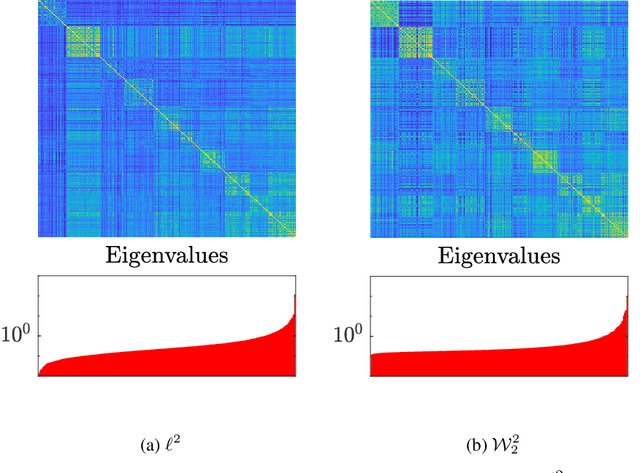



In the context of kernel methods, the similarity between data points is encoded by the kernel function which is often defined thanks to the Euclidean distance, a common example being the squared exponential kernel. Recently, other distances relying on optimal transport theory - such as the Wasserstein distance between probability distributions - have shown their practical relevance for different machine learning techniques. In this paper, we study the use of exponential kernels defined thanks to the regularized Wasserstein distance and discuss their positive definiteness. More specifically, we define Wasserstein feature maps and illustrate their interest for supervised learning problems involving shapes and images. Empirically, Wasserstein squared exponential kernels are shown to yield smaller classification errors on small training sets of shapes, compared to analogous classifiers using Euclidean distances.