 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperfect Vision Encoders: Efficient and Robust Tuning for Vision-Language Models
Jul 23, 2024



Vision language models (VLMs) demonstrate impressive capabilities in visual question answering and image captioning, acting as a crucial link between visual and language models. However, existing open-source VLMs heavily rely on pretrained and frozen vision encoders (such as CLIP). Despite CLIP's robustness across diverse domains, it still exhibits non-negligible image understanding errors. These errors propagate to the VLM responses, resulting in sub-optimal performance. In our work, we propose an efficient and robust method for updating vision encoders within VLMs. Our approach selectively and locally updates encoders, leading to substantial performance improvements on data where previous mistakes occurred, while maintaining overall robustness. Furthermore, we demonstrate the effectiveness of our method during continual few-shot updates. Theoretical grounding, generality, and computational efficiency characterize our approach.
On the Efficacy of Differentially Private Few-shot Image Classification
Feb 02, 2023There has been significant recent progress in training differentially private (DP) models which achieve accuracy that approaches the best non-private models. These DP models are typically pretrained on large public datasets and then fine-tuned on downstream datasets that are (i) relatively large, and (ii) similar in distribution to the pretraining data. However, in many applications including personalization, it is crucial to perform well in the few-shot setting, as obtaining large amounts of labeled data may be problematic; and on images from a wide variety of domains for use in various specialist settings. To understand under which conditions few-shot DP can be effective, we perform an exhaustive set of experiments that reveals how the accuracy and vulnerability to attack of few-shot DP image classification models are affected as the number of shots per class, privacy level, model architecture, dataset, and subset of learnable parameters in the model vary. We show that to achieve DP accuracy on par with non-private models, the shots per class must be increased as the privacy level increases by as much as 32$\times$ for CIFAR-100 at $\epsilon=1$. We also find that few-shot non-private models are highly susceptible to membership inference attacks. DP provides clear mitigation against the attacks, but a small $\epsilon$ is required to effectively prevent them. Finally, we evaluate DP federated learning systems and establish state-of-the-art performance on the challenging FLAIR federated learning benchmark.
FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification
Jun 17, 2022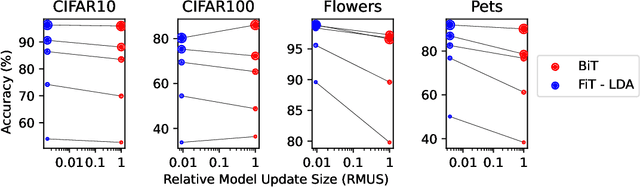
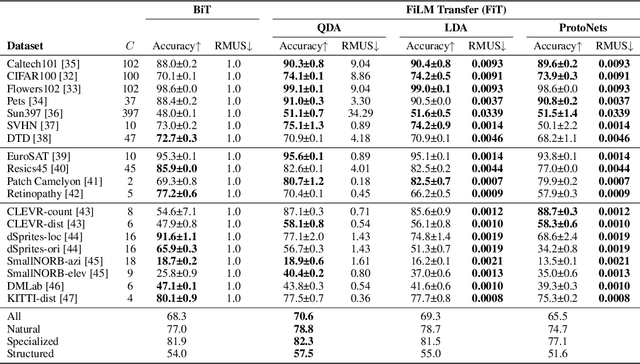

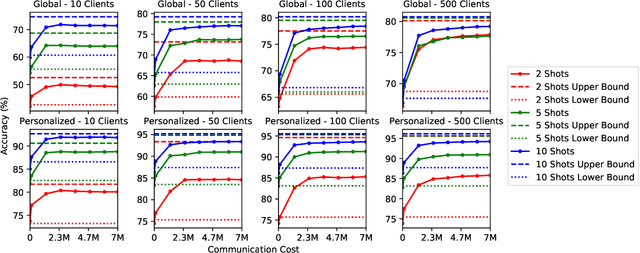
Modern deep learning systems are increasingly deployed in situations such as personalization and federated learning where it is necessary to support i) learning on small amounts of data, and ii) communication efficient distributed training protocols. In this work we develop FiLM Transfer (FiT) which fulfills these requirements in the image classification setting. FiT uses an automatically configured Naive Bayes classifier on top of a fixed backbone that has been pretrained on large image datasets. Parameter efficient FiLM layers are used to modulate the backbone, shaping the representation for the downstream task. The network is trained via an episodic fine-tuning protocol. The approach is parameter efficient which is key for enabling few-shot learning, inexpensive model updates for personalization, and communication efficient federated learning. We experiment with FiT on a wide range of downstream datasets and show that it achieves better classification accuracy than the state-of-the-art Big Transfer (BiT) algorithm at low-shot and on the challenging VTAB-1k benchmark, with fewer than 1% of the updateable parameters. Finally, we demonstrate the parameter efficiency of FiT in distributed low-shot applications including model personalization and federated learning where model update size is an important performance metric.
Conditional Density Estimation with Bayesian Normalising Flows
Feb 14, 2018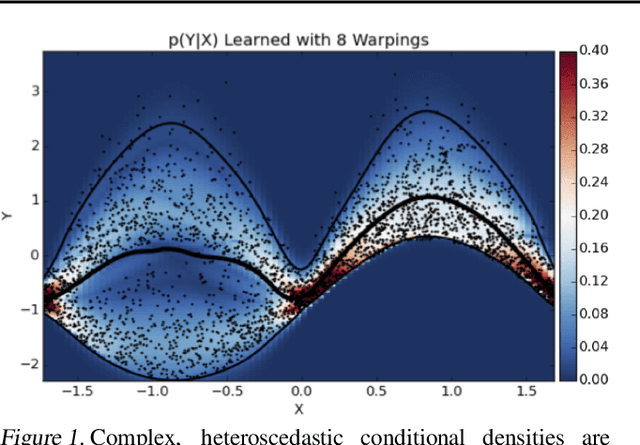

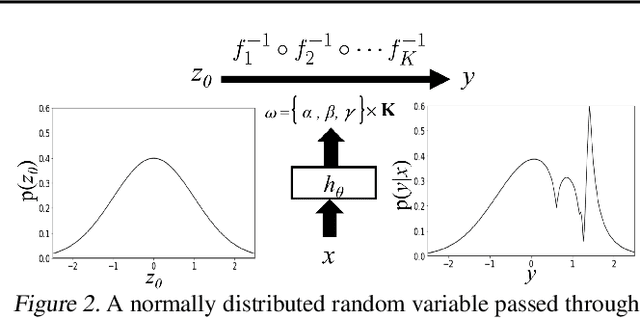

Modeling complex conditional distributions is critical in a variety of settings. Despite a long tradition of research into conditional density estimation, current methods employ either simple parametric forms or are difficult to learn in practice. This paper employs normalising flows as a flexible likelihood model and presents an efficient method for fitting them to complex densities. These estimators must trade-off between modeling distributional complexity, functional complexity and heteroscedasticity without overfitting. We recognize these trade-offs as modeling decisions and develop a Bayesian framework for placing priors over these conditional density estimators using variational Bayesian neural networks. We evaluate this method on several small benchmark regression datasets, on some of which it obtains state of the art performance. Finally, we apply the method to two spatial density modeling tasks with over 1 million datapoints using the New York City yellow taxi dataset and the Chicago crime dataset.