 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
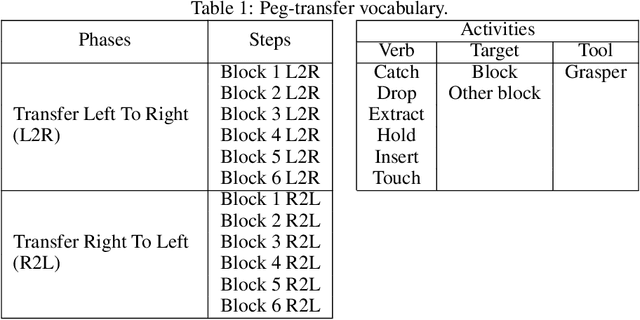
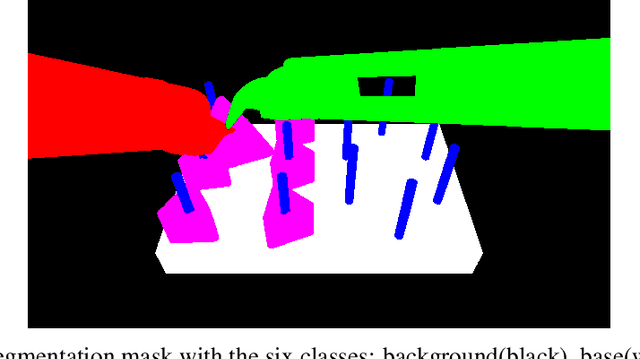
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.
MIcro-Surgical Anastomose Workflow recognition challenge report
Mar 24, 2021



The "MIcro-Surgical Anastomose Workflow recognition on training sessions" (MISAW) challenge provided a data set of 27 sequences of micro-surgical anastomosis on artificial blood vessels. This data set was composed of videos, kinematics, and workflow annotations described at three different granularity levels: phase, step, and activity. The participants were given the option to use kinematic data and videos to develop workflow recognition models. Four tasks were proposed to the participants: three of them were related to the recognition of surgical workflow at three different granularity levels, while the last one addressed the recognition of all granularity levels in the same model. One ranking was made for each task. We used the average application-dependent balanced accuracy (AD-Accuracy) as the evaluation metric. This takes unbalanced classes into account and it is more clinically relevant than a frame-by-frame score. Six teams, including a non-competing team, participated in at least one task. All models employed deep learning models, such as CNN or RNN. The best models achieved more than 95% AD-Accuracy for phase recognition, 80% for step recognition, 60% for activity recognition, and 75% for all granularity levels. For high levels of granularity (i.e., phases and steps), the best models had a recognition rate that may be sufficient for applications such as prediction of remaining surgical time or resource management. However, for activities, the recognition rate was still low for applications that can be employed clinically. The MISAW data set is publicly available to encourage further research in surgical workflow recognition. It can be found at www.synapse.org/MISAW
Offline identification of surgical deviations in laparoscopic rectopexy
Sep 24, 2019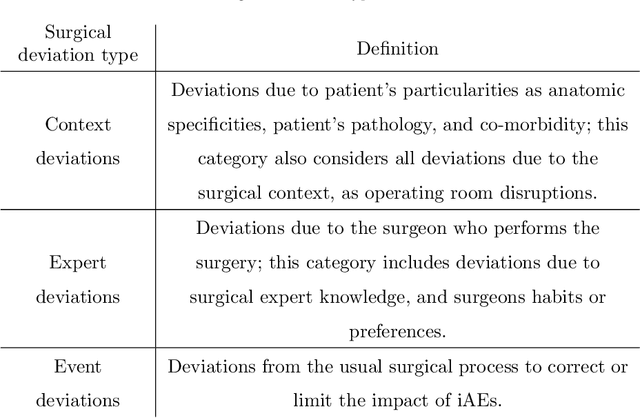
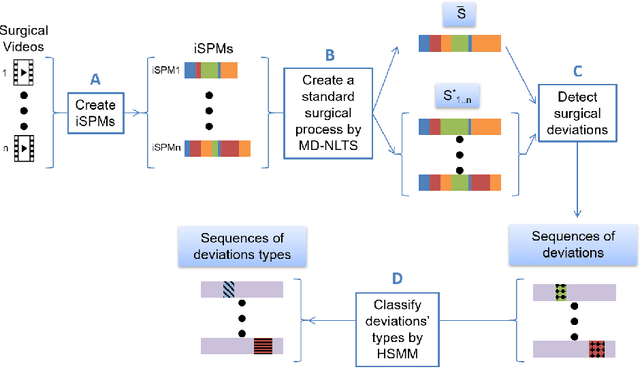
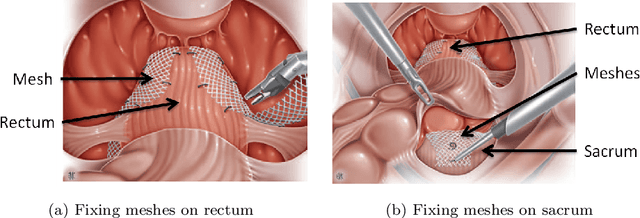
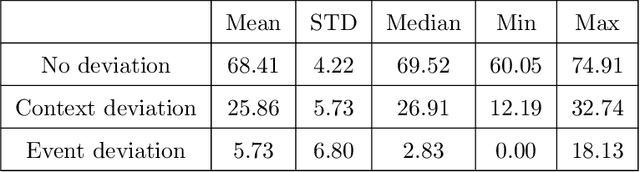
Objective: A median of 14.4% of patient undergone at least one adverse event during surgery and a third of them are preventable. The occurrence of adverse events forces surgeons to implement corrective strategies and, thus, deviate from the standard surgical process. Therefore, it is clear that the automatic identification of adverse events is a major challenge for patient safety. In this paper, we have proposed a method enabling us to identify such deviations. We have focused on identifying surgeons' deviations from standard surgical processes due to surgical events rather than anatomic specificities. This is particularly challenging, given the high variability in typical surgical procedure workflows. Methods: We have introduced a new approach designed to automatically detect and distinguish surgical process deviations based on multi-dimensional non-linear temporal scaling with a hidden semi-Markov model using manual annotation of surgical processes. The approach was then evaluated using cross-validation. Results: The best results have over 90% accuracy. Recall and precision were superior at 70%. We have provided a detailed analysis of the incorrectly-detected observations. Conclusion: Multi-dimensional non-linear temporal scaling with a hidden semi-Markov model provides promising results for detecting deviations. Our error analysis of the incorrectly-detected observations offers different leads in order to further improve our method. Significance: Our method demonstrated the feasibility of automatically detecting surgical deviations that could be implemented for both skill analysis and developing situation awareness-based computer-assisted surgical systems.