 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering
Apr 02, 2026We introduce STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration), a structured reinforcement learning framework for video question answering. While group-based policy optimization methods have shown promise in large multimodal models, they often suffer from low reward variance when responses exhibit similar correctness, leading to weak or unstable advantage estimates. STRIVE addresses this limitation by constructing multiple spatiotemporal variants of each input video and performing joint normalization across both textual generations and visual variants. By expanding group comparisons beyond linguistic diversity to structured visual perturbations, STRIVE enriches reward signals and promotes more stable and informative policy updates. To ensure exploration remains semantically grounded, we introduce an importance-aware sampling mechanism that prioritizes frames most relevant to the input question while preserving temporal coverage. This design encourages robust reasoning across complementary visual perspectives rather than overfitting to a single spatiotemporal configuration. Experiments on six challenging video reasoning benchmarks including VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest demonstrate consistent improvements over strong reinforcement learning baselines across multiple large multimodal models. Our results highlight the role of structured spatiotemporal exploration as a principled mechanism for stabilizing multimodal reinforcement learning and improving video reasoning performance.
Looking into the Unknown: Exploring Action Discovery for Segmentation of Known and Unknown Actions
Aug 07, 2025We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.
Towards Generalizing Temporal Action Segmentation to Unseen Views
Apr 03, 2025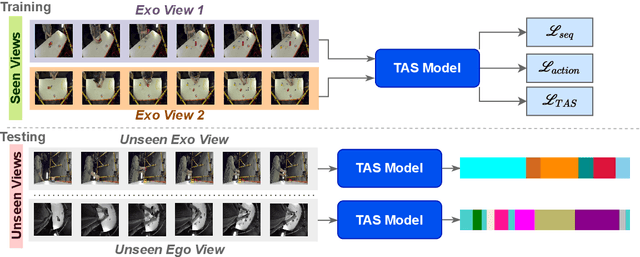
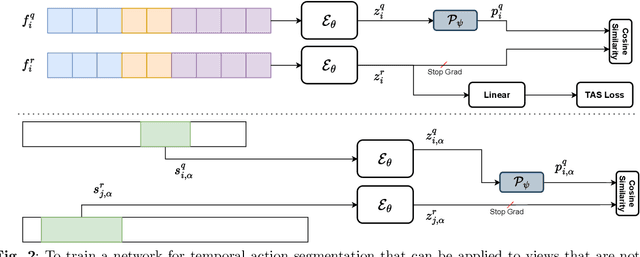
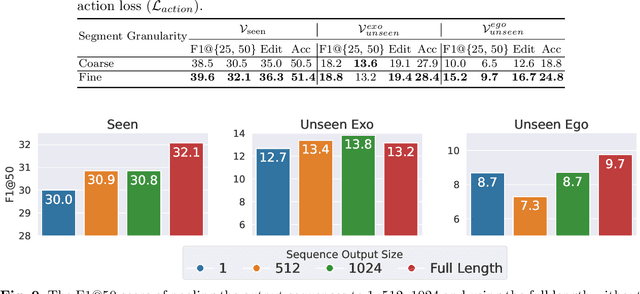

While there has been substantial progress in temporal action segmentation, the challenge to generalize to unseen views remains unaddressed. Hence, we define a protocol for unseen view action segmentation where camera views for evaluating the model are unavailable during training. This includes changing from top-frontal views to a side view or even more challenging from exocentric to egocentric views. Furthermore, we present an approach for temporal action segmentation that tackles this challenge. Our approach leverages a shared representation at both the sequence and segment levels to reduce the impact of view differences during training. We achieve this by introducing a sequence loss and an action loss, which together facilitate consistent video and action representations across different views. The evaluation on the Assembly101, IkeaASM, and EgoExoLearn datasets demonstrate significant improvements, with a 12.8% increase in F1@50 for unseen exocentric views and a substantial 54% improvement for unseen egocentric views.
SyncVP: Joint Diffusion for Synchronous Multi-Modal Video Prediction
Mar 24, 2025Predicting future video frames is essential for decision-making systems, yet RGB frames alone often lack the information needed to fully capture the underlying complexities of the real world. To address this limitation, we propose a multi-modal framework for Synchronous Video Prediction (SyncVP) that incorporates complementary data modalities, enhancing the richness and accuracy of future predictions. SyncVP builds on pre-trained modality-specific diffusion models and introduces an efficient spatio-temporal cross-attention module to enable effective information sharing across modalities. We evaluate SyncVP on standard benchmark datasets, such as Cityscapes and BAIR, using depth as an additional modality. We furthermore demonstrate its generalization to other modalities on SYNTHIA with semantic information and ERA5-Land with climate data. Notably, SyncVP achieves state-of-the-art performance, even in scenarios where only one modality is present, demonstrating its robustness and potential for a wide range of applications.
MANTA: Diffusion Mamba for Efficient and Effective Stochastic Long-Term Dense Anticipation
Jan 15, 2025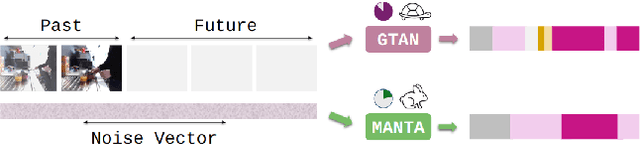

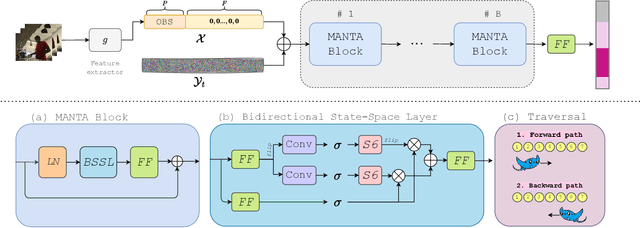

Our work addresses the problem of stochastic long-term dense anticipation. The goal of this task is to predict actions and their durations several minutes into the future based on provided video observations. Anticipation over extended horizons introduces high uncertainty, as a single observation can lead to multiple plausible future outcomes. To address this uncertainty, stochastic models are designed to predict several potential future action sequences. Recent work has further proposed to incorporate uncertainty modelling for observed frames by simultaneously predicting per-frame past and future actions in a unified manner. While such joint modelling of actions is beneficial, it requires long-range temporal capabilities to connect events across distant past and future time points. However, the previous work struggles to achieve such a long-range understanding due to its limited and/or sparse receptive field. To alleviate this issue, we propose a novel MANTA (MAmba for ANTicipation) network. Our model enables effective long-term temporal modelling even for very long sequences while maintaining linear complexity in sequence length. We demonstrate that our approach achieves state-of-the-art results on three datasets - Breakfast, 50Salads, and Assembly101 - while also significantly improving computational and memory efficiency.
Gated Temporal Diffusion for Stochastic Long-Term Dense Anticipation
Jul 16, 2024



Long-term action anticipation has become an important task for many applications such as autonomous driving and human-robot interaction. Unlike short-term anticipation, predicting more actions into the future imposes a real challenge with the increasing uncertainty in longer horizons. While there has been a significant progress in predicting more actions into the future, most of the proposed methods address the task in a deterministic setup and ignore the underlying uncertainty. In this paper, we propose a novel Gated Temporal Diffusion (GTD) network that models the uncertainty of both the observation and the future predictions. As generator, we introduce a Gated Anticipation Network (GTAN) to model both observed and unobserved frames of a video in a mutual representation. On the one hand, using a mutual representation for past and future allows us to jointly model ambiguities in the observation and future, while on the other hand GTAN can by design treat the observed and unobserved parts differently and steer the information flow between them. Our model achieves state-of-the-art results on the Breakfast, Assembly101 and 50Salads datasets in both stochastic and deterministic settings. Code: https://github.com/olga-zats/GTDA .
Action Anticipation with Goal Consistency
Jun 26, 2023In this paper, we address the problem of short-term action anticipation, i.e., we want to predict an upcoming action one second before it happens. We propose to harness high-level intent information to anticipate actions that will take place in the future. To this end, we incorporate an additional goal prediction branch into our model and propose a consistency loss function that encourages the anticipated actions to conform to the high-level goal pursued in the video. In our experiments, we show the effectiveness of the proposed approach and demonstrate that our method achieves state-of-the-art results on two large-scale datasets: Assembly101 and COIN.
Self-supervised Learning for Unintentional Action Prediction
Sep 24, 2022Distinguishing if an action is performed as intended or if an intended action fails is an important skill that not only humans have, but that is also important for intelligent systems that operate in human environments. Recognizing if an action is unintentional or anticipating if an action will fail, however, is not straightforward due to lack of annotated data. While videos of unintentional or failed actions can be found in the Internet in abundance, high annotation costs are a major bottleneck for learning networks for these tasks. In this work, we thus study the problem of self-supervised representation learning for unintentional action prediction. While previous works learn the representation based on a local temporal neighborhood, we show that the global context of a video is needed to learn a good representation for the three downstream tasks: unintentional action classification, localization and anticipation. In the supplementary material, we show that the learned representation can be used for detecting anomalies in videos as well.
Multi-Modal Temporal Convolutional Network for Anticipating Actions in Egocentric Videos
Jul 18, 2021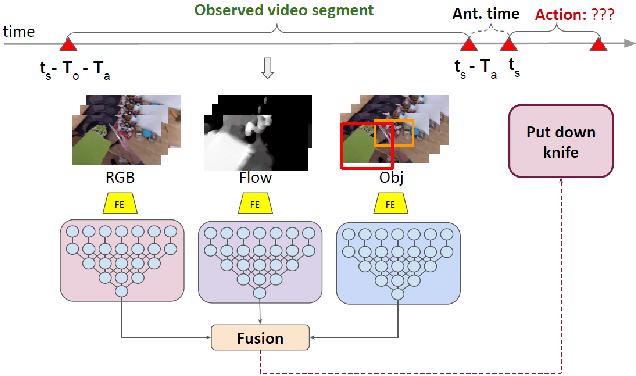
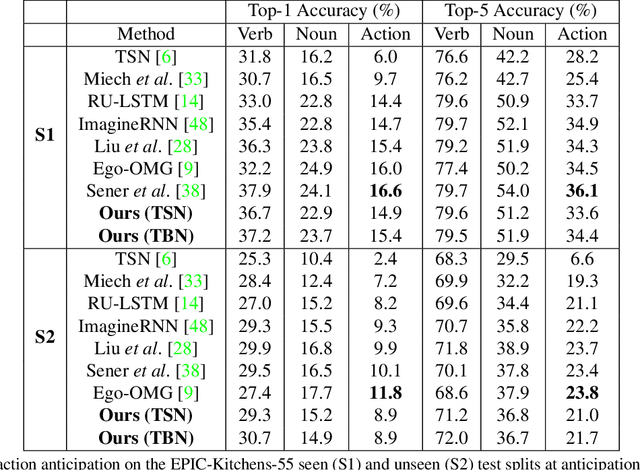

Anticipating human actions is an important task that needs to be addressed for the development of reliable intelligent agents, such as self-driving cars or robot assistants. While the ability to make future predictions with high accuracy is crucial for designing the anticipation approaches, the speed at which the inference is performed is not less important. Methods that are accurate but not sufficiently fast would introduce a high latency into the decision process. Thus, this will increase the reaction time of the underlying system. This poses a problem for domains such as autonomous driving, where the reaction time is crucial. In this work, we propose a simple and effective multi-modal architecture based on temporal convolutions. Our approach stacks a hierarchy of temporal convolutional layers and does not rely on recurrent layers to ensure a fast prediction. We further introduce a multi-modal fusion mechanism that captures the pairwise interactions between RGB, flow, and object modalities. Results on two large-scale datasets of egocentric videos, EPIC-Kitchens-55 and EPIC-Kitchens-100, show that our approach achieves comparable performance to the state-of-the-art approaches while being significantly faster.
Discovering Latent Classes for Semi-Supervised Semantic Segmentation
Dec 30, 2019

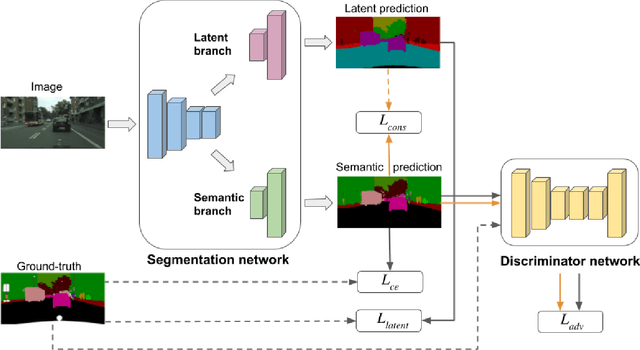
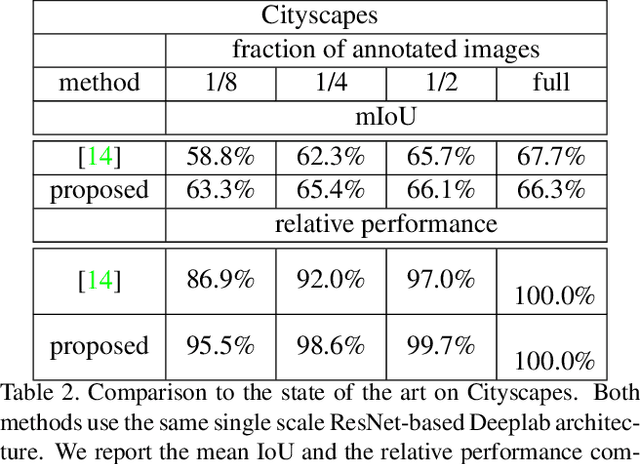
High annotation costs are a major bottleneck for the training of semantic segmentation systems. Therefore, methods working with less annotation effort are of special interest. This paper studies the problem of semi-supervised semantic segmentation. This means that only a small subset of the training images is annotated while the other training images do not contain any annotation. In order to leverage the information present in the unlabeled images, we propose to learn a second task that is related to semantic segmentation but easier. On labeled images, we learn latent classes consistent with semantic classes so that the variety of semantic classes assigned to a latent class is as low as possible. On unlabeled images, we predict a probability map for latent classes and use it as a supervision signal to learn semantic segmentation. The latent classes, as well as the semantic classes, are simultaneously predicted by a two-branch network. In our experiments on Pascal VOC and Cityscapes, we show that the latent classes learned this way have an intuitive meaning and that the proposed method achieves state of the art results for semi-supervised semantic segmentation.