 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Latent Classes for Semi-Supervised Semantic Segmentation
Dec 30, 2019

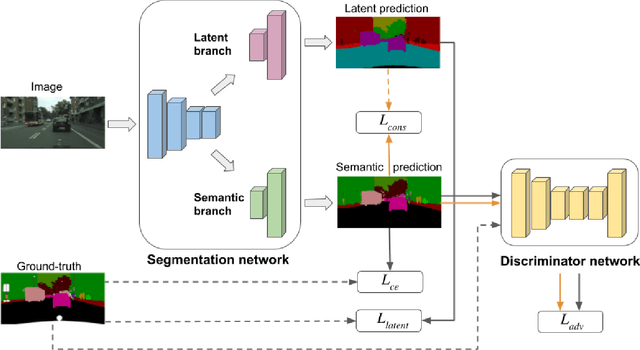
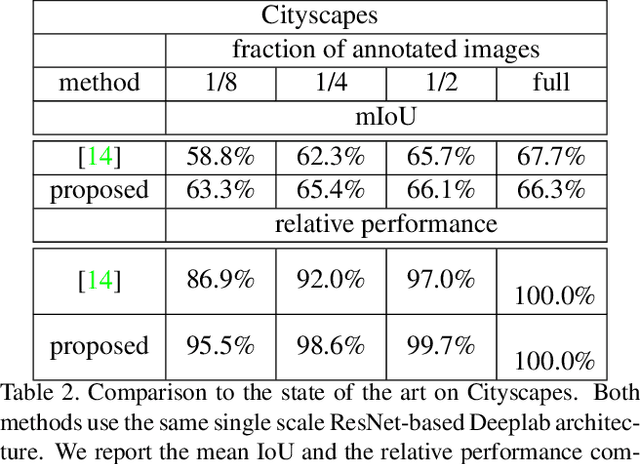
High annotation costs are a major bottleneck for the training of semantic segmentation systems. Therefore, methods working with less annotation effort are of special interest. This paper studies the problem of semi-supervised semantic segmentation. This means that only a small subset of the training images is annotated while the other training images do not contain any annotation. In order to leverage the information present in the unlabeled images, we propose to learn a second task that is related to semantic segmentation but easier. On labeled images, we learn latent classes consistent with semantic classes so that the variety of semantic classes assigned to a latent class is as low as possible. On unlabeled images, we predict a probability map for latent classes and use it as a supervision signal to learn semantic segmentation. The latent classes, as well as the semantic classes, are simultaneously predicted by a two-branch network. In our experiments on Pascal VOC and Cityscapes, we show that the latent classes learned this way have an intuitive meaning and that the proposed method achieves state of the art results for semi-supervised semantic segmentation.
Harvesting Information from Captions for Weakly Supervised Semantic Segmentation
May 16, 2019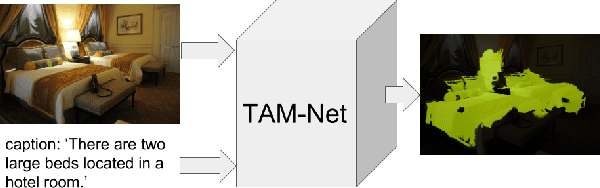
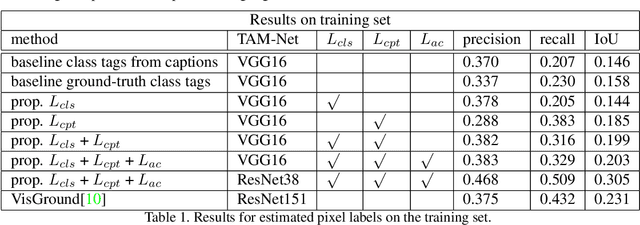


Since acquiring pixel-wise annotations for training convolutional neural networks for semantic image segmentation is time-consuming, weakly supervised approaches that only require class tags have been proposed. In this work, we propose another form of supervision, namely image captions as they can be found on the Internet. These captions have two advantages. They do not require additional curation as it is the case for the clean class tags used by current weakly supervised approaches and they provide textual context for the classes present in an image. To leverage such textual context, we deploy a multi-modal network that learns a joint embedding of the visual representation of the image and the textual representation of the caption. The network estimates text activation maps (TAMs) for class names as well as compound concepts, i.e. combinations of nouns and their attributes. The TAMs of compound concepts describing classes of interest substantially improve the quality of the estimated class activation maps which are then used to train a network for semantic segmentation. We evaluate our method on the COCO dataset where it achieves state of the art results for weakly supervised image segmentation.
What Object Should I Use? - Task Driven Object Detection
Apr 05, 2019


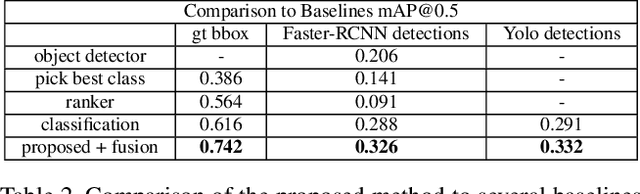
When humans have to solve everyday tasks, they simply pick the objects that are most suitable. While the question which object should one use for a specific task sounds trivial for humans, it is very difficult to answer for robots or other autonomous systems. This issue, however, is not addressed by current benchmarks for object detection that focus on detecting object categories. We therefore introduce the COCO-Tasks dataset which comprises about 40,000 images where the most suitable objects for 14 tasks have been annotated. We furthermore propose an approach that detects the most suitable objects for a given task. The approach builds on a Gated Graph Neural Network to exploit the appearance of each object as well as the global context of all present objects in the scene. In our experiments, we show that the proposed approach outperforms other approaches that are evaluated on the dataset like classification or ranking approaches.
Two Stream 3D Semantic Scene Completion
Jul 16, 2018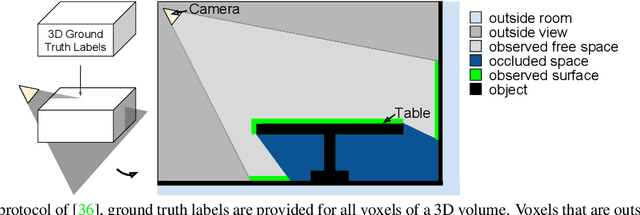


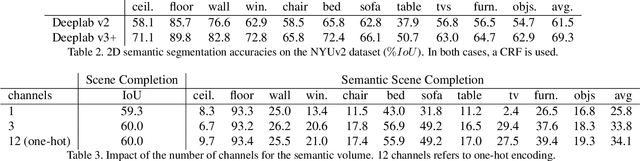
Inferring the 3D geometry and the semantic meaning of surfaces, which are occluded, is a very challenging task. Recently, a first end-to-end learning approach has been proposed that completes a scene from a single depth image. The approach voxelizes the scene and predicts for each voxel if it is occupied and, if it is occupied, the semantic class label. In this work, we propose a two stream approach that leverages depth information and semantic information, which is inferred from the RGB image, for this task. The approach constructs an incomplete 3D semantic tensor, which uses a compact three-channel encoding for the inferred semantic information, and uses a 3D CNN to infer the complete 3D semantic tensor. In our experimental evaluation, we show that the proposed two stream approach substantially outperforms the state-of-the-art for semantic scene completion.
Adaptive Binarization for Weakly Supervised Affordance Segmentation
Jul 10, 2017



The concept of affordance is important to understand the relevance of object parts for a certain functional interaction. Affordance types generalize across object categories and are not mutually exclusive. This makes the segmentation of affordance regions of objects in images a difficult task. In this work, we build on an iterative approach that learns a convolutional neural network for affordance segmentation from sparse keypoints. During this process, the predictions of the network need to be binarized. In this work, we propose an adaptive approach for binarization and estimate the parameters for initialization by approximated cross validation. We evaluate our approach on two affordance datasets where our approach outperforms the state-of-the-art for weakly supervised affordance segmentation.