 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamContextI2V: Context-aware Controllable Video Generation
Apr 08, 2025Recently, image-to-video (I2V) diffusion models have demonstrated impressive scene understanding and generative quality, incorporating image conditions to guide generation. However, these models primarily animate static images without extending beyond their provided context. Introducing additional constraints, such as camera trajectories, can enhance diversity but often degrades visual quality, limiting their applicability for tasks requiring faithful scene representation. We propose CamContextI2V, an I2V model that integrates multiple image conditions with 3D constraints alongside camera control to enrich both global semantics and fine-grained visual details. This enables more coherent and context-aware video generation. Moreover, we motivate the necessity of temporal awareness for an effective context representation. Our comprehensive study on the RealEstate10K dataset demonstrates improvements in visual quality and camera controllability. We make our code and models publicly available at: https://github.com/LDenninger/CamContextI2V.
SyncVP: Joint Diffusion for Synchronous Multi-Modal Video Prediction
Mar 24, 2025Predicting future video frames is essential for decision-making systems, yet RGB frames alone often lack the information needed to fully capture the underlying complexities of the real world. To address this limitation, we propose a multi-modal framework for Synchronous Video Prediction (SyncVP) that incorporates complementary data modalities, enhancing the richness and accuracy of future predictions. SyncVP builds on pre-trained modality-specific diffusion models and introduces an efficient spatio-temporal cross-attention module to enable effective information sharing across modalities. We evaluate SyncVP on standard benchmark datasets, such as Cityscapes and BAIR, using depth as an additional modality. We furthermore demonstrate its generalization to other modalities on SYNTHIA with semantic information and ERA5-Land with climate data. Notably, SyncVP achieves state-of-the-art performance, even in scenarios where only one modality is present, demonstrating its robustness and potential for a wide range of applications.
Convolutional Relational Machine for Group Activity Recognition
Apr 05, 2019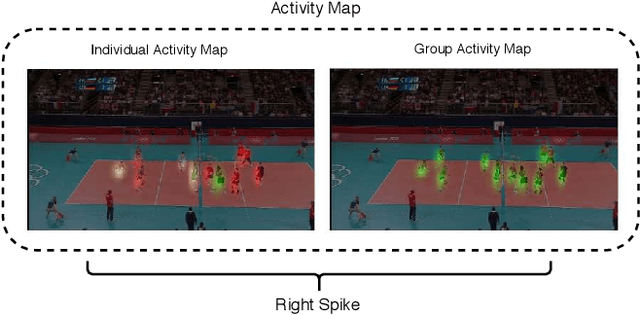
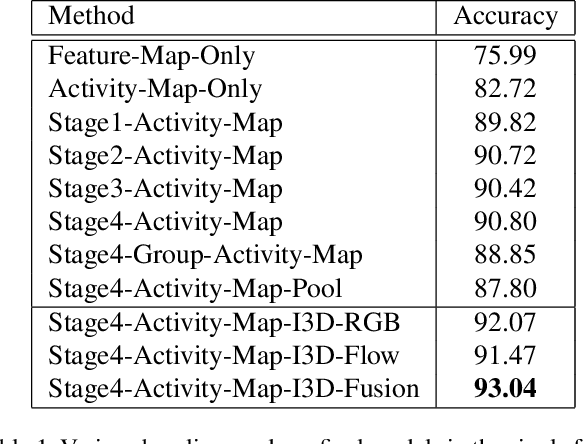
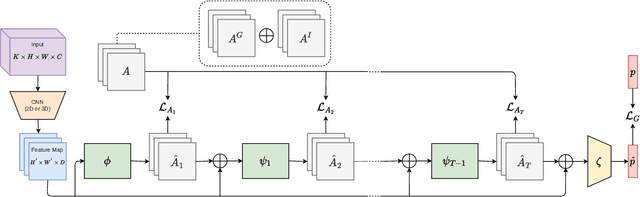
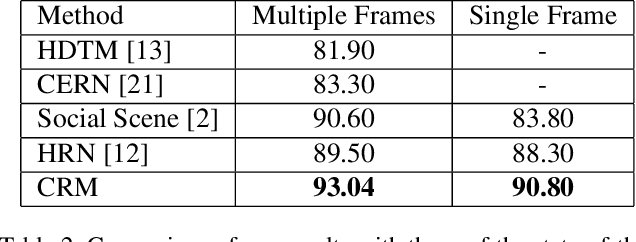
We present an end-to-end deep Convolutional Neural Network called Convolutional Relational Machine (CRM) for recognizing group activities that utilizes the information in spatial relations between individual persons in image or video. It learns to produce an intermediate spatial representation (activity map) based on individual and group activities. A multi-stage refinement component is responsible for decreasing the incorrect predictions in the activity map. Finally, an aggregation component uses the refined information to recognize group activities. Experimental results demonstrate the constructive contribution of the information extracted and represented in the form of the activity map. CRM shows advantages over state-of-the-art models on Volleyball and Collective Activity datasets.
A Multi-Stream Convolutional Neural Network Framework for Group Activity Recognition
Dec 26, 2018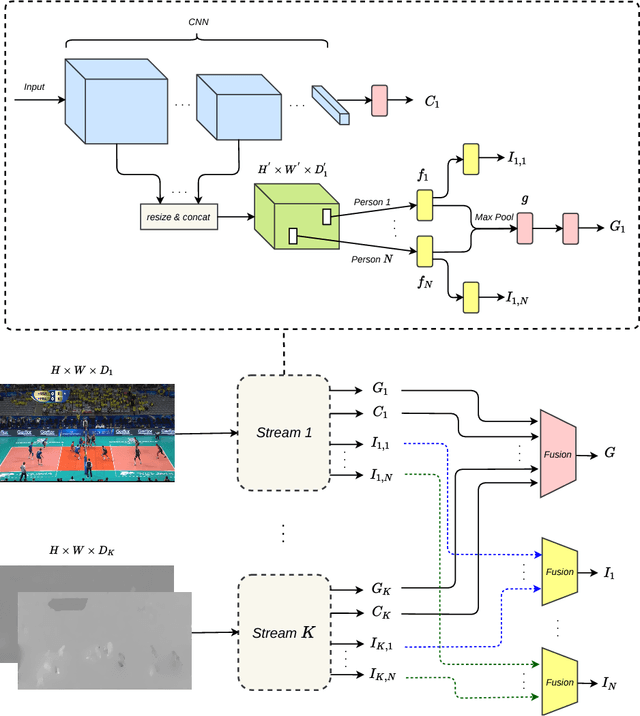
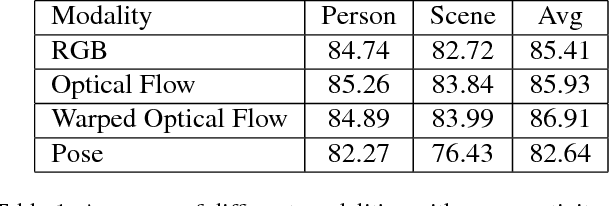

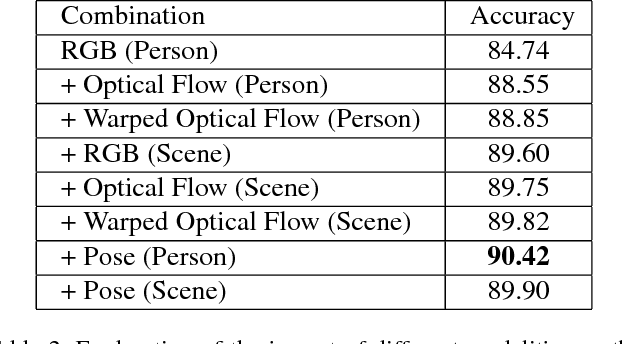
In this work, we present a framework based on multi-stream convolutional neural networks (CNNs) for group activity recognition. Streams of CNNs are separately trained on different modalities and their predictions are fused at the end. Each stream has two branches to predict the group activity based on person and scene level representations. A new modality based on the human pose estimation is presented to add extra information to the model. We evaluate our method on the Volleyball and Collective Activity datasets. Experimental results show that the proposed framework is able to achieve state-of-the-art results when multiple or single frames are given as input to the model with 90.50% and 86.61% accuracy on Volleyball dataset, respectively, and 87.01% accuracy of multiple frames group activity on Collective Activity dataset.
Zoom-RNN: A Novel Method for Person Recognition Using Recurrent Neural Networks
Sep 26, 2018The overwhelming popularity of social media has resulted in bulk amounts of personal photos being uploaded to the internet every day. Since these photos are taken in unconstrained settings, recognizing the identities of people among the photos remains a challenge. Studies have indicated that utilizing evidence other than face appearance improves the performance of person recognition systems. In this work, we aim to take advantage of additional cues obtained from different body regions in a zooming in fashion for person recognition. Hence, we present Zoom-RNN, a novel method based on recurrent neural networks for combining evidence extracted from the whole body, upper body, and head regions. Our model is evaluated on a challenging dataset, namely People In Photo Albums (PIPA), and we demonstrate that employing our system improves the performance of conventional fusion methods by a noticeable margin.