 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQDT: Pseudo-Query Dual Transformer for Robust Point Cloud Restoration
May 24, 2026Point clouds are a fundamental 3D representation in computer vision, enabling a wide range of perception tasks. However, real-world point clouds often suffer from degradations such as incompleteness, noise, outliers, and irregular density, caused by sensor limitations or occlusions. Recovering clean and detailed shapes from such degraded data is crucial for downstream applications. While existing learning-based methods achieve progress on individual tasks like completion or denoising, they typically rely on global bottleneck features, which lose fine-grained geometry and remain sensitive to varying input quality. We propose a unified 3D restoration network that directly takes point clouds as input and adaptively reconstructs high-quality geometry under diverse degradation scenarios. At the core of our approach is a Pseudo-Query module, implemented within a Transformer backbone, which reformulates geometric translation into two cooperative stages to enhance structural clarity, robustness, and local detail preservation. Extensive experiments on curated benchmarks demonstrate that our approach surpasses state-of-the-art performance in general 3D restoration. It effectively handles complex combinations of completion, deformation, and denoising degradations. With this work, we provide a novel unified, point-only backbone for robust 3D restoration, enabling more versatile 3D perception.
Density-Aware Farthest Point Sampling
Sep 16, 2025

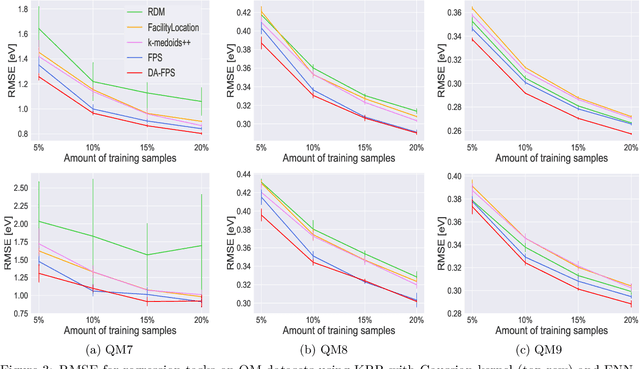

We focus on training machine learning regression models in scenarios where the availability of labeled training data is limited due to computational constraints or high labeling costs. Thus, selecting suitable training sets from unlabeled data is essential for balancing performance and efficiency. For the selection of the training data, we focus on passive and model-agnostic sampling methods that only consider the data feature representations. We derive an upper bound for the expected prediction error of Lipschitz continuous regression models that linearly depends on the weighted fill distance of the training set, a quantity we can estimate simply by considering the data features. We introduce "Density-Aware Farthest Point Sampling" (DA-FPS), a novel sampling method. We prove that DA-FPS provides approximate minimizers for a data-driven estimation of the weighted fill distance, thereby aiming at minimizing our derived bound. We conduct experiments using two regression models across three datasets. The results demonstrate that DA-FPS significantly reduces the mean absolute prediction error compared to other sampling strategies.
Learning Crowd Behaviors in Navigation with Attention-based Spatial-Temporal Graphs
Jan 11, 2024Safe and efficient navigation in dynamic environments shared with humans remains an open and challenging task for mobile robots. Previous works have shown the efficacy of using reinforcement learning frameworks to train policies for efficient navigation. However, their performance deteriorates when crowd configurations change, i.e. become larger or more complex. Thus, it is crucial to fully understand the complex, dynamic, and sophisticated interactions of the crowd resulting in proactive and foresighted behaviors for robot navigation. In this paper, a novel deep graph learning architecture based on attention mechanisms is proposed, which leverages the spatial-temporal graph to enhance robot navigation. We employ spatial graphs to capture the current spatial interactions, and through the integration with RNN, the temporal graphs utilize past trajectory information to infer the future intentions of each agent. The spatial-temporal graph reasoning ability allows the robot to better understand and interpret the relationships between agents over time and space, thereby making more informed decisions. Compared to previous state-of-the-art methods, our method demonstrates superior robustness in terms of safety, efficiency, and generalization in various challenging scenarios.
Unsupervised Representation Learning for Diverse Deformable Shape Collections
Oct 27, 2023


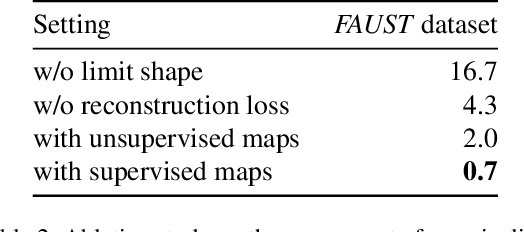
We introduce a novel learning-based method for encoding and manipulating 3D surface meshes. Our method is specifically designed to create an interpretable embedding space for deformable shape collections. Unlike previous 3D mesh autoencoders that require meshes to be in a 1-to-1 correspondence, our approach is trained on diverse meshes in an unsupervised manner. Central to our method is a spectral pooling technique that establishes a universal latent space, breaking free from traditional constraints of mesh connectivity and shape categories. The entire process consists of two stages. In the first stage, we employ the functional map paradigm to extract point-to-point (p2p) maps between a collection of shapes in an unsupervised manner. These p2p maps are then utilized to construct a common latent space, which ensures straightforward interpretation and independence from mesh connectivity and shape category. Through extensive experiments, we demonstrate that our method achieves excellent reconstructions and produces more realistic and smoother interpolations than baseline approaches.
Investigating minimizing the training set fill distance in machine learning regression
Jul 20, 2023Many machine learning regression methods leverage large datasets for training predictive models. However, using large datasets may not be feasible due to computational limitations or high labelling costs. Therefore, sampling small training sets from large pools of unlabelled data points is essential to maximize model performance while maintaining computational efficiency. In this work, we study a sampling approach aimed to minimize the fill distance of the selected set. We derive an upper bound for the maximum expected prediction error that linearly depends on the training set fill distance, conditional to the knowledge of data features. For empirical validation, we perform experiments using two regression models on two datasets. We empirically show that selecting a training set by aiming to minimize the fill distance, thereby minimizing the bound, significantly reduces the maximum prediction error of various regression models, outperforming existing sampling approaches by a large margin.
Graph Extraction for Assisting Crash Simulation Data Analysis
Jun 15, 2023



In this work, we establish a method for abstracting information from Computer Aided Engineering (CAE) into graphs. Such graph representations of CAE data can improve design guidelines and support recommendation systems by enabling the comparison of simulations, highlighting unexplored experimental designs, and correlating different designs. We focus on the load-path in crashworthiness analysis, a complex sub-discipline in vehicle design. The load-path is the sequence of parts that absorb most of the energy caused by the impact. To detect the load-path, we generate a directed weighted graph from the CAE data. The vertices represent the vehicle's parts, and the edges are an abstraction of the connectivity of the parts. The edge direction follows the temporal occurrence of the collision, where the edge weights reflect aspects of the energy absorption. We introduce and assess three methods for graph extraction and an additional method for further updating each graph with the sequences of absorption. Based on longest-path calculations, we introduce an automated detection of the load-path, which we analyse for the different graph extraction methods and weights. Finally, we show how our method for the detection of load-paths helps in the classification and labelling of CAE simulations.
On the Interplay of Subset Selection and Informed Graph Neural Networks
Jun 15, 2023



Machine learning techniques paired with the availability of massive datasets dramatically enhance our ability to explore the chemical compound space by providing fast and accurate predictions of molecular properties. However, learning on large datasets is strongly limited by the availability of computational resources and can be infeasible in some scenarios. Moreover, the instances in the datasets may not yet be labelled and generating the labels can be costly, as in the case of quantum chemistry computations. Thus, there is a need to select small training subsets from large pools of unlabelled data points and to develop reliable ML methods that can effectively learn from small training sets. This work focuses on predicting the molecules atomization energy in the QM9 dataset. We investigate the advantages of employing domain knowledge-based data sampling methods for an efficient training set selection combined with informed ML techniques. In particular, we show how maximizing molecular diversity in the training set selection process increases the robustness of linear and nonlinear regression techniques such as kernel methods and graph neural networks. We also check the reliability of the predictions made by the graph neural network with a model-agnostic explainer based on the rate distortion explanation framework.
Evolutionary Solution Adaption for Multi-Objective Metal Cutting Process Optimization
May 31, 2023



Optimizing manufacturing process parameters is typically a multi-objective problem with often contradictory objectives such as production quality and production time. If production requirements change, process parameters have to be optimized again. Since optimization usually requires costly simulations based on, for example, the Finite Element method, it is of great interest to have means to reduce the number of evaluations needed for optimization. To this end, we consider optimizing for different production requirements from the viewpoint of a framework for system flexibility that allows us to study the ability of an algorithm to transfer solutions from previous optimization tasks, which also relates to dynamic evolutionary optimization. Based on the extended Oxley model for orthogonal metal cutting, we introduce a multi-objective optimization benchmark where different materials define related optimization tasks, and use it to study the flexibility of NSGA-II, which we extend by two variants: 1) varying goals, that optimizes solutions for two tasks simultaneously to obtain in-between source solutions expected to be more adaptable, and 2) active-inactive genotype, that accommodates different possibilities that can be activated or deactivated. Results show that adaption with standard NSGA-II greatly reduces the number of evaluations required for optimization to a target goal, while the proposed variants further improve the adaption costs, although further work is needed towards making the methods advantageous for real applications.
Transfer Learning using Spectral Convolutional Autoencoders on Semi-Regular Surface Meshes
Dec 12, 2022



The underlying dynamics and patterns of 3D surface meshes deforming over time can be discovered by unsupervised learning, especially autoencoders, which calculate low-dimensional embeddings of the surfaces. To study the deformation patterns of unseen shapes by transfer learning, we want to train an autoencoder that can analyze new surface meshes without training a new network. Here, most state-of-the-art autoencoders cannot handle meshes of different connectivity and therefore have limited to no generalization capacities to new meshes. Also, reconstruction errors strongly increase in comparison to the errors for the training shapes. To address this, we propose a novel spectral CoSMA (Convolutional Semi-Regular Mesh Autoencoder) network. This patch-based approach is combined with a surface-aware training. It reconstructs surfaces not presented during training and generalizes the deformation behavior of the surfaces' patches. The novel approach reconstructs unseen meshes from different datasets in superior quality compared to state-of-the-art autoencoders that have been trained on these shapes. Our transfer learning errors on unseen shapes are 40% lower than those from models learned directly on the data. Furthermore, baseline autoencoders detect deformation patterns of unseen mesh sequences only for the whole shape. In contrast, due to the employed regional patches and stable reconstruction quality, we can localize where on the surfaces these deformation patterns manifest.
Graph Modeling in Computer Assisted Automotive Development
Sep 29, 2022
We consider graph modeling for a knowledge graph for vehicle development, with a focus on crash safety. An organized schema that incorporates information from various structured and unstructured data sources is provided, which includes relevant concepts within the domain. In particular, we propose semantics for crash computer aided engineering (CAE) data, which enables searchability, filtering, recommendation, and prediction for crash CAE data during the development process. This graph modeling considers the CAE data in the context of the R\&D development process and vehicle safety. Consequently, we connect CAE data to the protocols that are used to assess vehicle safety performances. The R\&D process includes CAD engineering and safety attributes, with a focus on multidisciplinary problem-solving. We describe previous efforts in graph modeling in comparison to our proposal, discuss its strengths and limitations, and identify areas for future work.
* ICKG 2022