 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Aware Farthest Point Sampling
Sep 16, 2025

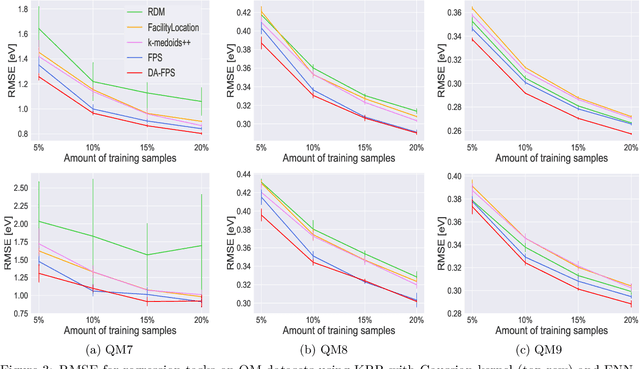

We focus on training machine learning regression models in scenarios where the availability of labeled training data is limited due to computational constraints or high labeling costs. Thus, selecting suitable training sets from unlabeled data is essential for balancing performance and efficiency. For the selection of the training data, we focus on passive and model-agnostic sampling methods that only consider the data feature representations. We derive an upper bound for the expected prediction error of Lipschitz continuous regression models that linearly depends on the weighted fill distance of the training set, a quantity we can estimate simply by considering the data features. We introduce "Density-Aware Farthest Point Sampling" (DA-FPS), a novel sampling method. We prove that DA-FPS provides approximate minimizers for a data-driven estimation of the weighted fill distance, thereby aiming at minimizing our derived bound. We conduct experiments using two regression models across three datasets. The results demonstrate that DA-FPS significantly reduces the mean absolute prediction error compared to other sampling strategies.
Investigating minimizing the training set fill distance in machine learning regression
Jul 20, 2023Many machine learning regression methods leverage large datasets for training predictive models. However, using large datasets may not be feasible due to computational limitations or high labelling costs. Therefore, sampling small training sets from large pools of unlabelled data points is essential to maximize model performance while maintaining computational efficiency. In this work, we study a sampling approach aimed to minimize the fill distance of the selected set. We derive an upper bound for the maximum expected prediction error that linearly depends on the training set fill distance, conditional to the knowledge of data features. For empirical validation, we perform experiments using two regression models on two datasets. We empirically show that selecting a training set by aiming to minimize the fill distance, thereby minimizing the bound, significantly reduces the maximum prediction error of various regression models, outperforming existing sampling approaches by a large margin.
On the Interplay of Subset Selection and Informed Graph Neural Networks
Jun 15, 2023



Machine learning techniques paired with the availability of massive datasets dramatically enhance our ability to explore the chemical compound space by providing fast and accurate predictions of molecular properties. However, learning on large datasets is strongly limited by the availability of computational resources and can be infeasible in some scenarios. Moreover, the instances in the datasets may not yet be labelled and generating the labels can be costly, as in the case of quantum chemistry computations. Thus, there is a need to select small training subsets from large pools of unlabelled data points and to develop reliable ML methods that can effectively learn from small training sets. This work focuses on predicting the molecules atomization energy in the QM9 dataset. We investigate the advantages of employing domain knowledge-based data sampling methods for an efficient training set selection combined with informed ML techniques. In particular, we show how maximizing molecular diversity in the training set selection process increases the robustness of linear and nonlinear regression techniques such as kernel methods and graph neural networks. We also check the reliability of the predictions made by the graph neural network with a model-agnostic explainer based on the rate distortion explanation framework.
Multi-resolution Dynamic Mode Decomposition for Early Damage Detection in Wind Turbine Gearboxes
Oct 08, 2021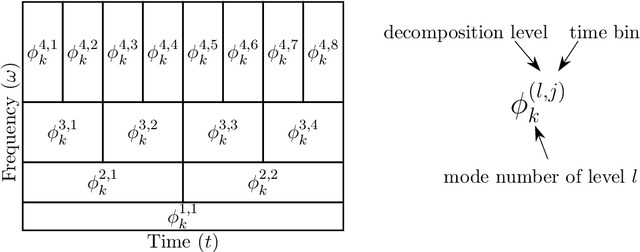

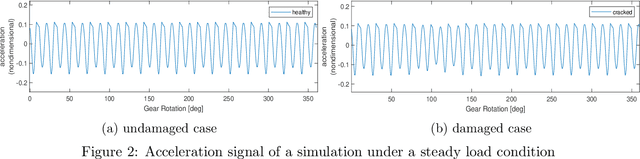
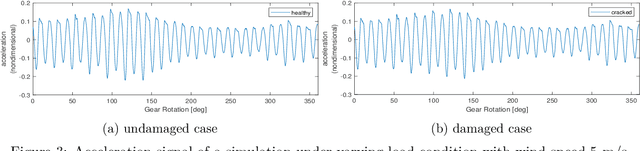
We introduce an approach for damage detection in gearboxes based on the analysis of sensor data with the multi-resolution dynamic mode decomposition (mrDMD). The application focus is the condition monitoring of wind turbine gearboxes under varying load conditions, in particular irregular and stochastic wind fluctuations. We analyze data stemming from a simulated vibration response of a simple nonlinear gearbox model in a healthy and damaged scenario and under different wind conditions. With mrDMD applied on time-delay snapshots of the sensor data, we can extract components in these vibration signals that highlight features related to damage and enable its identification. A comparison with Fourier analysis and Empirical Mode Decomposition shows the advantages of the proposed mrDMD-based data analysis approach for early damage detection.