 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Representation Learning for Diverse Deformable Shape Collections
Oct 27, 2023


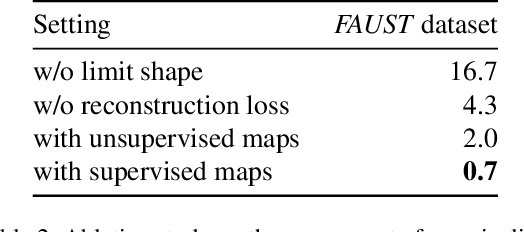
We introduce a novel learning-based method for encoding and manipulating 3D surface meshes. Our method is specifically designed to create an interpretable embedding space for deformable shape collections. Unlike previous 3D mesh autoencoders that require meshes to be in a 1-to-1 correspondence, our approach is trained on diverse meshes in an unsupervised manner. Central to our method is a spectral pooling technique that establishes a universal latent space, breaking free from traditional constraints of mesh connectivity and shape categories. The entire process consists of two stages. In the first stage, we employ the functional map paradigm to extract point-to-point (p2p) maps between a collection of shapes in an unsupervised manner. These p2p maps are then utilized to construct a common latent space, which ensures straightforward interpretation and independence from mesh connectivity and shape category. Through extensive experiments, we demonstrate that our method achieves excellent reconstructions and produces more realistic and smoother interpolations than baseline approaches.
Transfer Learning using Spectral Convolutional Autoencoders on Semi-Regular Surface Meshes
Dec 12, 2022



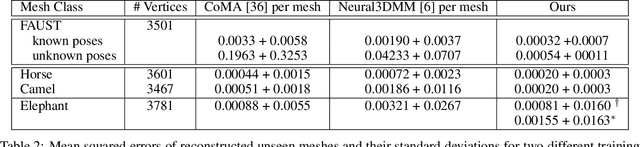
The underlying dynamics and patterns of 3D surface meshes deforming over time can be discovered by unsupervised learning, especially autoencoders, which calculate low-dimensional embeddings of the surfaces. To study the deformation patterns of unseen shapes by transfer learning, we want to train an autoencoder that can analyze new surface meshes without training a new network. Here, most state-of-the-art autoencoders cannot handle meshes of different connectivity and therefore have limited to no generalization capacities to new meshes. Also, reconstruction errors strongly increase in comparison to the errors for the training shapes. To address this, we propose a novel spectral CoSMA (Convolutional Semi-Regular Mesh Autoencoder) network. This patch-based approach is combined with a surface-aware training. It reconstructs surfaces not presented during training and generalizes the deformation behavior of the surfaces' patches. The novel approach reconstructs unseen meshes from different datasets in superior quality compared to state-of-the-art autoencoders that have been trained on these shapes. Our transfer learning errors on unseen shapes are 40% lower than those from models learned directly on the data. Furthermore, baseline autoencoders detect deformation patterns of unseen mesh sequences only for the whole shape. In contrast, due to the employed regional patches and stable reconstruction quality, we can localize where on the surfaces these deformation patterns manifest.
Mesh Convolutional Autoencoder for Semi-Regular Meshes of Different Sizes
Oct 20, 2021
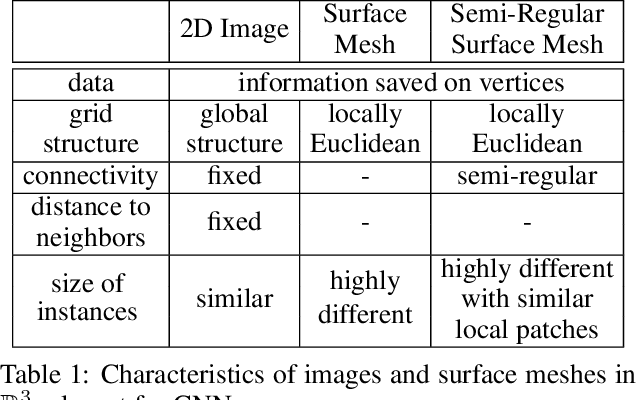
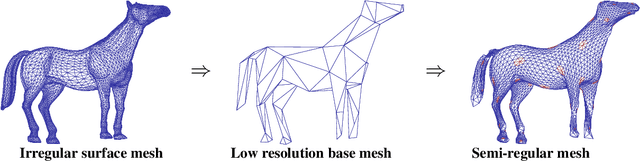
The analysis of deforming 3D surface meshes is accelerated by autoencoders since the low-dimensional embeddings can be used to visualize underlying dynamics. But, state-of-the-art mesh convolutional autoencoders require a fixed connectivity of all input meshes handled by the autoencoder. This is due to either the use of spectral convolutional layers or mesh dependent pooling operations. Therefore, the types of datasets that one can study are limited and the learned knowledge cannot be transferred to other datasets that exhibit similar behavior. To address this, we transform the discretization of the surfaces to semi-regular meshes that have a locally regular connectivity and whose meshing is hierarchical. This allows us to apply the same spatial convolutional filters to the local neighborhoods and to define a pooling operator that can be applied to every semi-regular mesh. We apply the same mesh autoencoder to different datasets and our reconstruction error is more than 50% lower than the error from state-of-the-art models, which have to be trained for every mesh separately. Additionally, we visualize the underlying dynamics of unseen mesh sequences with an autoencoder trained on different classes of meshes.
Analysis and Prediction of Deforming 3D Shapes using Oriented Bounding Boxes and LSTM Autoencoders
Aug 31, 2020
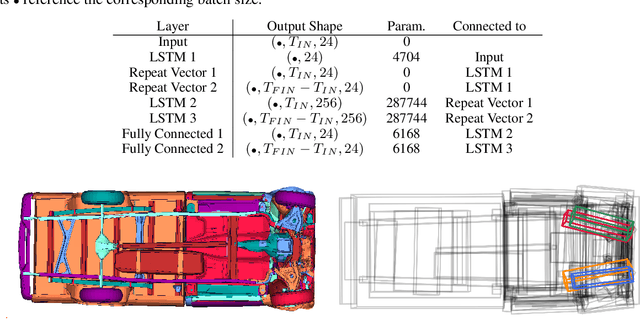
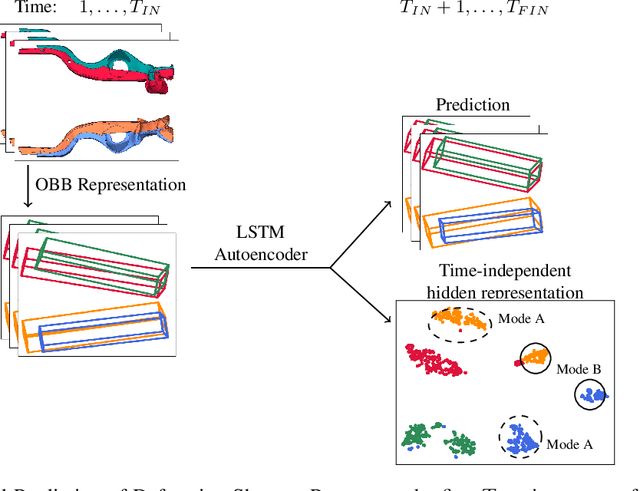
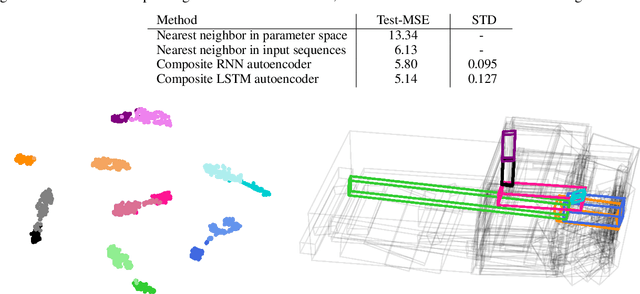
For sequences of complex 3D shapes in time we present a general approach to detect patterns for their analysis and to predict the deformation by making use of structural components of the complex shape. We incorporate long short-term memory (LSTM) layers into an autoencoder to create low dimensional representations that allow the detection of patterns in the data and additionally detect the temporal dynamics in the deformation behavior. This is achieved with two decoders, one for reconstruction and one for prediction of future time steps of the sequence. In a preprocessing step the components of the studied object are converted to oriented bounding boxes which capture the impact of plastic deformation and allow reducing the dimensionality of the data describing the structure. The architecture is tested on the results of 196 car crash simulations of a model with 133 different components, where material properties are varied. In the latent representation we can detect patterns in the plastic deformation for the different components. The predicted bounding boxes give an estimate of the final simulation result and their quality is improved in comparison to different baselines.