 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon Perception
Mar 28, 2026Perception-centric systems are typically implemented with a modular encoder-decoder pipeline: a vision backbone for feature extraction and a separate decoder (or late-fusion module) for task prediction. This raises a central question: is this architectural separation essential or can a single early-fusion stack do both perception and task modeling at scale? We introduce Falcon Perception, a unified dense Transformer that processes image patches and text tokens in a shared parameter space from the first layer, using a hybrid attention pattern (bidirectional among image tokens, causal for prediction tokens) to combine global visual context with autoregressive, variable-length instance generation. To keep dense outputs practical, Falcon Perception retains a lightweight token interface and decodes continuous spatial outputs with specialized heads, enabling parallel high-resolution mask prediction. Our design promotes simplicity: we keep a single scalable backbone and shift complexity toward data and training signals, adding only small heads where outputs are continuous and dense. On SA-Co, Falcon Perception improves mask quality to 68.0 Macro-F$_1$ compared to 62.3 of SAM3. We also introduce PBench, a benchmark targeting compositional prompts (OCR, spatial constraints, relations) and dense long-context regimes, where the model shows better gains. Finally, we extend the same early-fusion recipe to Falcon OCR: a compact 300M-parameter model which attains 80.3% on olmOCR and 88.64 on OmniDocBench.
VisRes Bench: On Evaluating the Visual Reasoning Capabilities of VLMs
Dec 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress across tasks such as visual question answering and image captioning. Yet, the extent to which these models perform visual reasoning as opposed to relying on linguistic priors remains unclear. To address this, we introduce VisRes Bench, a benchmark designed to study visual reasoning in naturalistic settings without contextual language supervision. Analyzing model behavior across three levels of complexity, we uncover clear limitations in perceptual and relational visual reasoning capacities. VisRes isolates distinct reasoning abilities across its levels. Level 1 probes perceptual completion and global image matching under perturbations such as blur, texture changes, occlusion, and rotation; Level 2 tests rule-based inference over a single attribute (e.g., color, count, orientation); and Level 3 targets compositional reasoning that requires integrating multiple visual attributes. Across more than 19,000 controlled task images, we find that state-of-the-art VLMs perform near random under subtle perceptual perturbations, revealing limited abstraction beyond pattern recognition. We conclude by discussing how VisRes provides a unified framework for advancing abstract visual reasoning in multimodal research.
AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Dec 23, 2025Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
REVEAL: Relation-based Video Representation Learning for Video-Question-Answering
Apr 07, 2025Video-Question-Answering (VideoQA) comprises the capturing of complex visual relation changes over time, remaining a challenge even for advanced Video Language Models (VLM), i.a., because of the need to represent the visual content to a reasonably sized input for those models. To address this problem, we propose RElation-based Video rEpresentAtion Learning (REVEAL), a framework designed to capture visual relation information by encoding them into structured, decomposed representations. Specifically, inspired by spatiotemporal scene graphs, we propose to encode video sequences as sets of relation triplets in the form of (\textit{subject-predicate-object}) over time via their language embeddings. To this end, we extract explicit relations from video captions and introduce a Many-to-Many Noise Contrastive Estimation (MM-NCE) together with a Q-Former architecture to align an unordered set of video-derived queries with corresponding text-based relation descriptions. At inference, the resulting Q-former produces an efficient token representation that can serve as input to a VLM for VideoQA. We evaluate the proposed framework on five challenging benchmarks: NeXT-QA, Intent-QA, STAR, VLEP, and TVQA. It shows that the resulting query-based video representation is able to outperform global alignment-based CLS or patch token representations and achieves competitive results against state-of-the-art models, particularly on tasks requiring temporal reasoning and relation comprehension. The code and models will be publicly released.
MaskInversion: Localized Embeddings via Optimization of Explainability Maps
Jul 29, 2024Vision-language foundation models such as CLIP have achieved tremendous results in global vision-language alignment, but still show some limitations in creating representations for specific image regions. % To address this problem, we propose MaskInversion, a method that leverages the feature representations of pre-trained foundation models, such as CLIP, to generate a context-aware embedding for a query image region specified by a mask at test time. MaskInversion starts with initializing an embedding token and compares its explainability map, derived from the foundation model, to the query mask. The embedding token is then subsequently refined to approximate the query region by minimizing the discrepancy between its explainability map and the query mask. During this process, only the embedding vector is updated, while the underlying foundation model is kept frozen allowing to use MaskInversion with any pre-trained model. As deriving the explainability map involves computing its gradient, which can be expensive, we propose a gradient decomposition strategy that simplifies this computation. The learned region representation can be used for a broad range of tasks, including open-vocabulary class retrieval, referring expression comprehension, as well as for localized captioning and image generation. We evaluate the proposed method on all those tasks on several datasets such as PascalVOC, MSCOCO, RefCOCO, and OpenImagesV7 and show its capabilities compared to other SOTA approaches.
LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity
Apr 04, 2024



Vision Transformers (ViTs), with their ability to model long-range dependencies through self-attention mechanisms, have become a standard architecture in computer vision. However, the interpretability of these models remains a challenge. To address this, we propose LeGrad, an explainability method specifically designed for ViTs. LeGrad computes the gradient with respect to the attention maps of ViT layers, considering the gradient itself as the explainability signal. We aggregate the signal over all layers, combining the activations of the last as well as intermediate tokens to produce the merged explainability map. This makes LeGrad a conceptually simple and an easy-to-implement tool for enhancing the transparency of ViTs. We evaluate LeGrad in challenging segmentation, perturbation, and open-vocabulary settings, showcasing its versatility compared to other SotA explainability methods demonstrating its superior spatial fidelity and robustness to perturbations. A demo and the code is available at https://github.com/WalBouss/LeGrad.
EfficientQA : a RoBERTa Based Phrase-Indexed Question-Answering System
Jan 30, 2021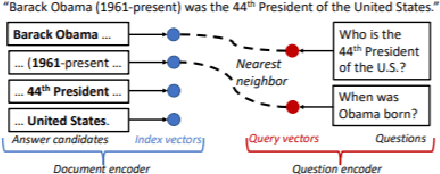
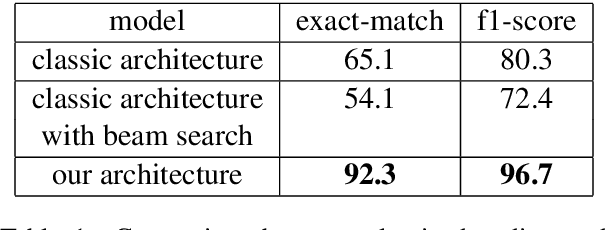
State-of-the-art extractive question answering models achieve superhuman performances on the SQuAD benchmark. Yet, they are unreasonably heavy and need expensive GPU computing to answer questions in a reasonable time. Thus, they cannot be used for real-world queries on hundreds of thousands of documents in the open-domain question answering paradigm. In this paper, we explore the possibility to transfer the natural language understanding of language models into dense vectors representing questions and answer candidates, in order to make the task of question-answering compatible with a simple nearest neighbor search task. This new model, that we call EfficientQA, takes advantage from the pair of sequences kind of input of BERT-based models to build meaningful dense representations of candidate answers. These latter are extracted from the context in a question-agnostic fashion. Our model achieves state-of-the-art results in Phrase-Indexed Question Answering (PIQA) beating the previous state-of-art by 1.3 points in exact-match and 1.4 points in f1-score. These results show that dense vectors are able to embed very rich semantic representations of sequences, although these ones were built from language models not originally trained for the use-case. Thus, in order to build more resource efficient NLP systems in the future, training language models that are better adapted to build dense representations of phrases is one of the possibilities.
MIX : a Multi-task Learning Approach to Solve Open-Domain Question Answering
Dec 17, 2020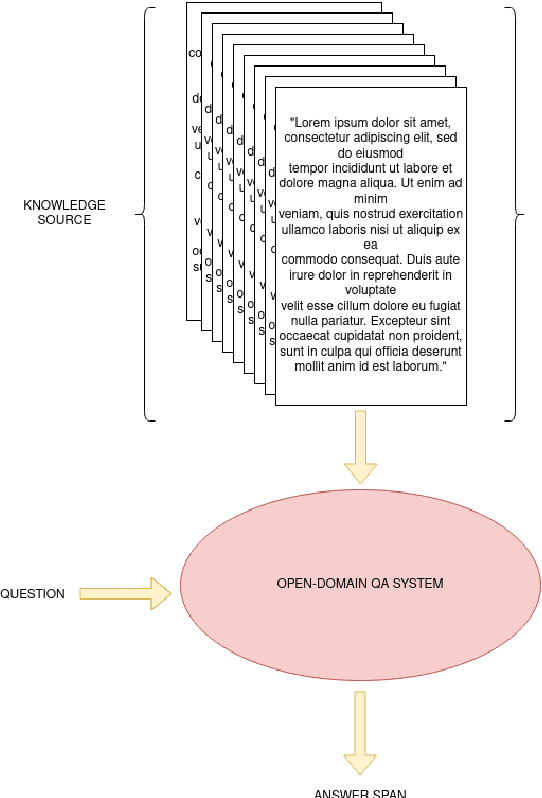
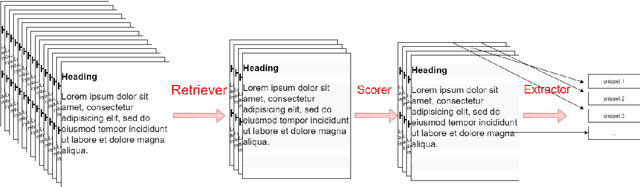
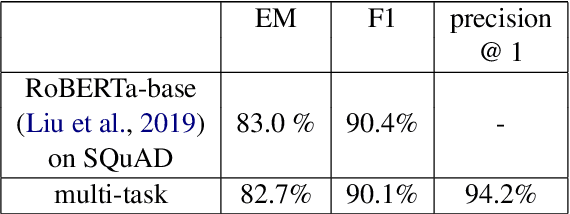
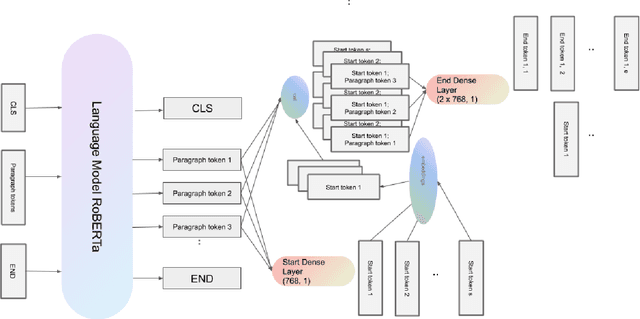
In this paper, we introduce MIX : a multi-task deep learning approach to solve Open-Domain Question Answering. First, we design our system as a multi-stage pipeline made of 3 building blocks : a BM25-based Retriever, to reduce the search space; RoBERTa based Scorer and Extractor, to rank retrieved documents and extract relevant spans of text respectively. Eventually, we further improve computational efficiency of our system to deal with the scalability challenge : thanks to multi-task learning, we parallelize the close tasks solved by the Scorer and the Extractor. Our system outperforms previous state-of-the-art by 12 points in both f1-score and exact-match on the squad-open benchmark.