 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientQA : a RoBERTa Based Phrase-Indexed Question-Answering System
Jan 30, 2021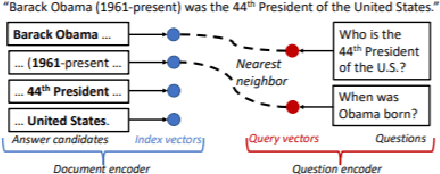
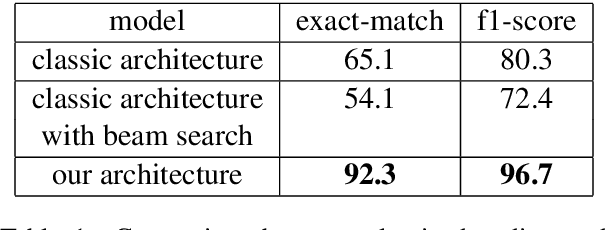
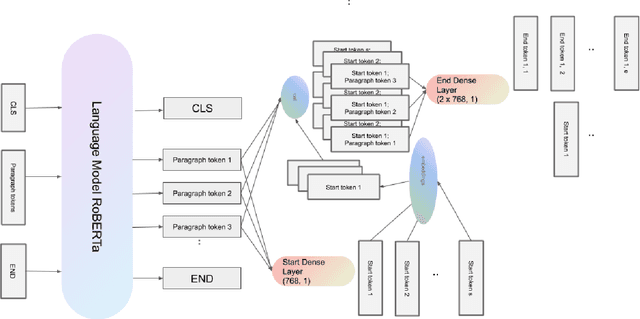
State-of-the-art extractive question answering models achieve superhuman performances on the SQuAD benchmark. Yet, they are unreasonably heavy and need expensive GPU computing to answer questions in a reasonable time. Thus, they cannot be used for real-world queries on hundreds of thousands of documents in the open-domain question answering paradigm. In this paper, we explore the possibility to transfer the natural language understanding of language models into dense vectors representing questions and answer candidates, in order to make the task of question-answering compatible with a simple nearest neighbor search task. This new model, that we call EfficientQA, takes advantage from the pair of sequences kind of input of BERT-based models to build meaningful dense representations of candidate answers. These latter are extracted from the context in a question-agnostic fashion. Our model achieves state-of-the-art results in Phrase-Indexed Question Answering (PIQA) beating the previous state-of-art by 1.3 points in exact-match and 1.4 points in f1-score. These results show that dense vectors are able to embed very rich semantic representations of sequences, although these ones were built from language models not originally trained for the use-case. Thus, in order to build more resource efficient NLP systems in the future, training language models that are better adapted to build dense representations of phrases is one of the possibilities.
MIX : a Multi-task Learning Approach to Solve Open-Domain Question Answering
Dec 17, 2020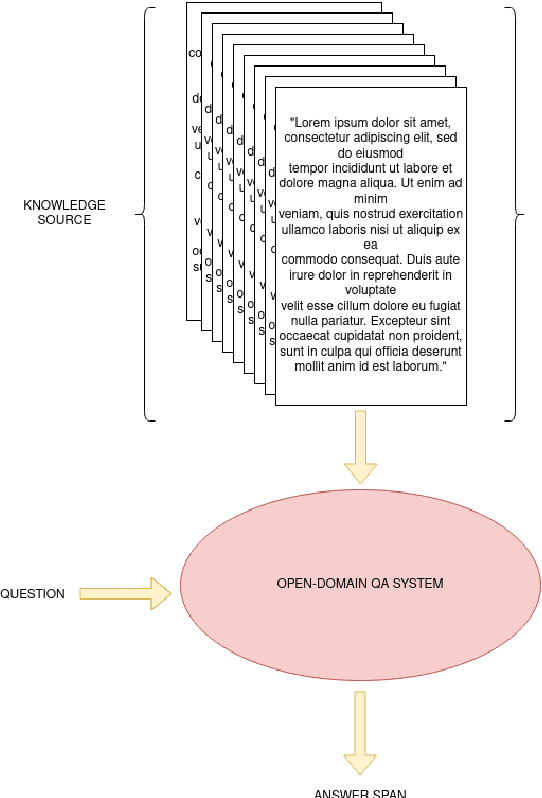
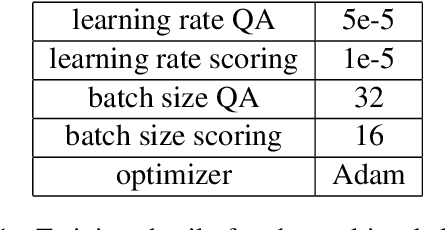
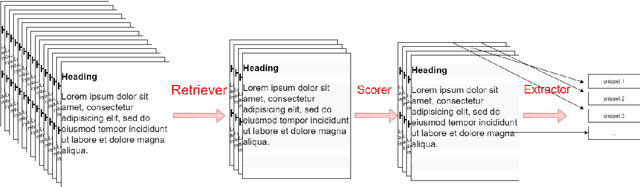
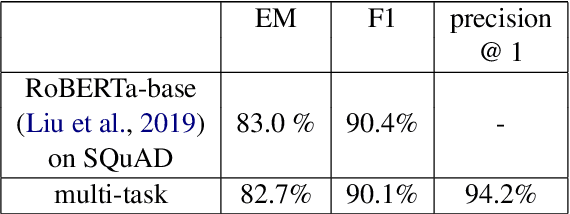
In this paper, we introduce MIX : a multi-task deep learning approach to solve Open-Domain Question Answering. First, we design our system as a multi-stage pipeline made of 3 building blocks : a BM25-based Retriever, to reduce the search space; RoBERTa based Scorer and Extractor, to rank retrieved documents and extract relevant spans of text respectively. Eventually, we further improve computational efficiency of our system to deal with the scalability challenge : thanks to multi-task learning, we parallelize the close tasks solved by the Scorer and the Extractor. Our system outperforms previous state-of-the-art by 12 points in both f1-score and exact-match on the squad-open benchmark.