Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIX : a Multi-task Learning Approach to Solve Open-Domain Question Answering
Paper and Code
Dec 17, 2020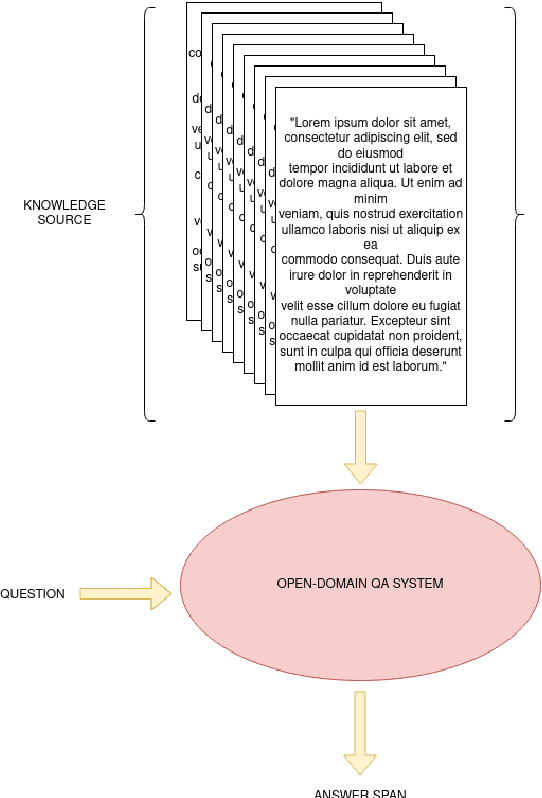
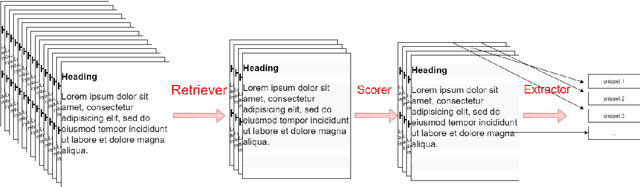
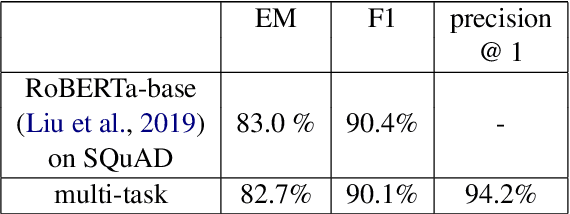
In this paper, we introduce MIX : a multi-task deep learning approach to solve Open-Domain Question Answering. First, we design our system as a multi-stage pipeline made of 3 building blocks : a BM25-based Retriever, to reduce the search space; RoBERTa based Scorer and Extractor, to rank retrieved documents and extract relevant spans of text respectively. Eventually, we further improve computational efficiency of our system to deal with the scalability challenge : thanks to multi-task learning, we parallelize the close tasks solved by the Scorer and the Extractor. Our system outperforms previous state-of-the-art by 12 points in both f1-score and exact-match on the squad-open benchmark.
* 7 pages, 6 figures, 4 tables
View paper on