 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVDC: Automated Vision Data Cleaning Using Vision-Language Models
Jul 16, 2025Training of autonomous driving systems requires extensive datasets with precise annotations to attain robust performance. Human annotations suffer from imperfections, and multiple iterations are often needed to produce high-quality datasets. However, manually reviewing large datasets is laborious and expensive. In this paper, we introduce AutoVDC (Automated Vision Data Cleaning) framework and investigate the utilization of Vision-Language Models (VLMs) to automatically identify erroneous annotations in vision datasets, thereby enabling users to eliminate these errors and enhance data quality. We validate our approach using the KITTI and nuImages datasets, which contain object detection benchmarks for autonomous driving. To test the effectiveness of AutoVDC, we create dataset variants with intentionally injected erroneous annotations and observe the error detection rate of our approach. Additionally, we compare the detection rates using different VLMs and explore the impact of VLM fine-tuning on our pipeline. The results demonstrate our method's high performance in error detection and data cleaning experiments, indicating its potential to significantly improve the reliability and accuracy of large-scale production datasets in autonomous driving.
AugMapNet: Improving Spatial Latent Structure via BEV Grid Augmentation for Enhanced Vectorized Online HD Map Construction
Mar 17, 2025Autonomous driving requires an understanding of the infrastructure elements, such as lanes and crosswalks. To navigate safely, this understanding must be derived from sensor data in real-time and needs to be represented in vectorized form. Learned Bird's-Eye View (BEV) encoders are commonly used to combine a set of camera images from multiple views into one joint latent BEV grid. Traditionally, from this latent space, an intermediate raster map is predicted, providing dense spatial supervision but requiring post-processing into the desired vectorized form. More recent models directly derive infrastructure elements as polylines using vectorized map decoders, providing instance-level information. Our approach, Augmentation Map Network (AugMapNet), proposes latent BEV grid augmentation, a novel technique that significantly enhances the latent BEV representation. AugMapNet combines vector decoding and dense spatial supervision more effectively than existing architectures while remaining as straightforward to integrate and as generic as auxiliary supervision. Experiments on nuScenes and Argoverse2 datasets demonstrate significant improvements in vectorized map prediction performance up to 13.3% over the StreamMapNet baseline on 60m range and greater improvements on larger ranges. We confirm transferability by applying our method to another baseline and find similar improvements. A detailed analysis of the latent BEV grid confirms a more structured latent space of AugMapNet and shows the value of our novel concept beyond pure performance improvement. The code will be released soon.
VQA: Visual Question Answering
Oct 27, 2016

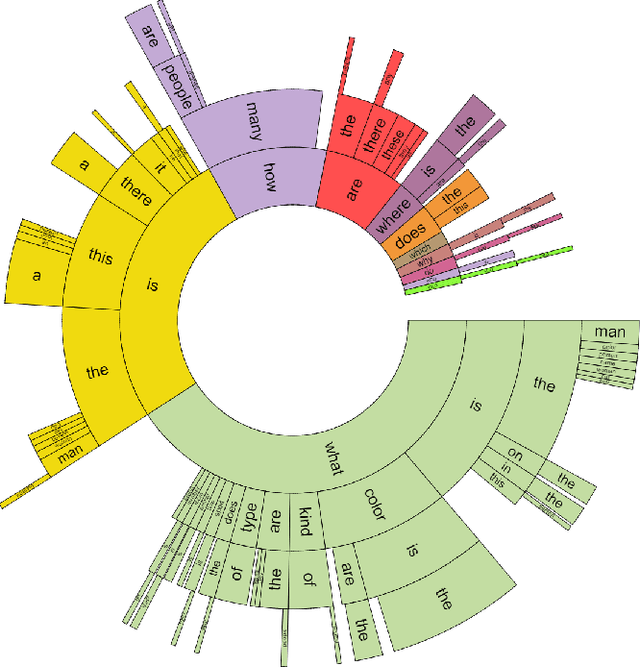
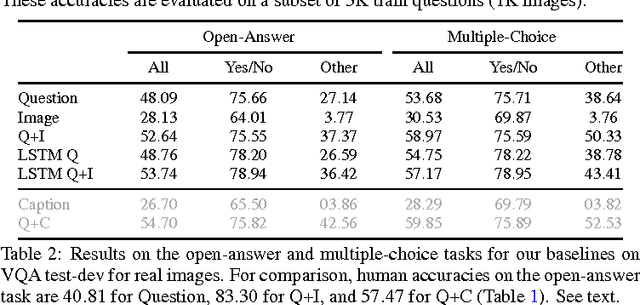
We propose the task of free-form and open-ended Visual Question Answering (VQA). Given an image and a natural language question about the image, the task is to provide an accurate natural language answer. Mirroring real-world scenarios, such as helping the visually impaired, both the questions and answers are open-ended. Visual questions selectively target different areas of an image, including background details and underlying context. As a result, a system that succeeds at VQA typically needs a more detailed understanding of the image and complex reasoning than a system producing generic image captions. Moreover, VQA is amenable to automatic evaluation, since many open-ended answers contain only a few words or a closed set of answers that can be provided in a multiple-choice format. We provide a dataset containing ~0.25M images, ~0.76M questions, and ~10M answers (www.visualqa.org), and discuss the information it provides. Numerous baselines and methods for VQA are provided and compared with human performance. Our VQA demo is available on CloudCV (http://cloudcv.org/vqa).
Resolving Language and Vision Ambiguities Together: Joint Segmentation & Prepositional Attachment Resolution in Captioned Scenes
Sep 26, 2016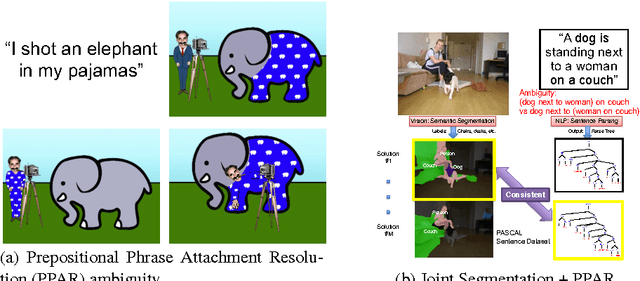
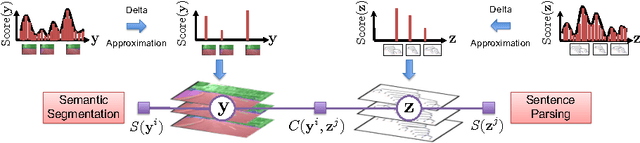
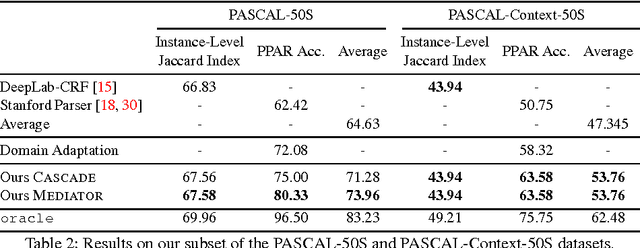
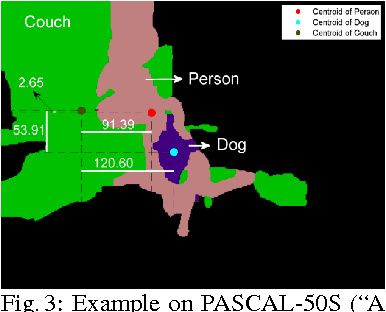
We present an approach to simultaneously perform semantic segmentation and prepositional phrase attachment resolution for captioned images. Some ambiguities in language cannot be resolved without simultaneously reasoning about an associated image. If we consider the sentence "I shot an elephant in my pajamas", looking at language alone (and not using common sense), it is unclear if it is the person or the elephant wearing the pajamas or both. Our approach produces a diverse set of plausible hypotheses for both semantic segmentation and prepositional phrase attachment resolution that are then jointly reranked to select the most consistent pair. We show that our semantic segmentation and prepositional phrase attachment resolution modules have complementary strengths, and that joint reasoning produces more accurate results than any module operating in isolation. Multiple hypotheses are also shown to be crucial to improved multiple-module reasoning. Our vision and language approach significantly outperforms the Stanford Parser (De Marneffe et al., 2006) by 17.91% (28.69% relative) and 12.83% (25.28% relative) in two different experiments. We also make small improvements over DeepLab-CRF (Chen et al., 2015).
Measuring Machine Intelligence Through Visual Question Answering
Aug 31, 2016


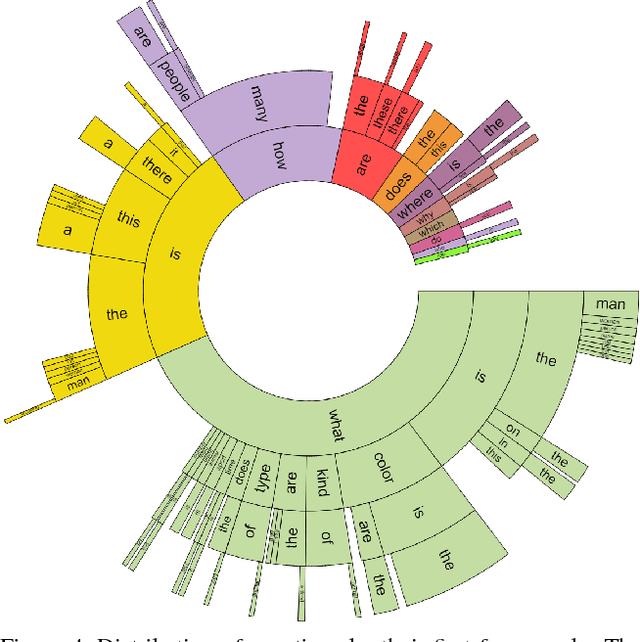
As machines have become more intelligent, there has been a renewed interest in methods for measuring their intelligence. A common approach is to propose tasks for which a human excels, but one which machines find difficult. However, an ideal task should also be easy to evaluate and not be easily gameable. We begin with a case study exploring the recently popular task of image captioning and its limitations as a task for measuring machine intelligence. An alternative and more promising task is Visual Question Answering that tests a machine's ability to reason about language and vision. We describe a dataset unprecedented in size created for the task that contains over 760,000 human generated questions about images. Using around 10 million human generated answers, machines may be easily evaluated.
We Are Humor Beings: Understanding and Predicting Visual Humor
May 05, 2016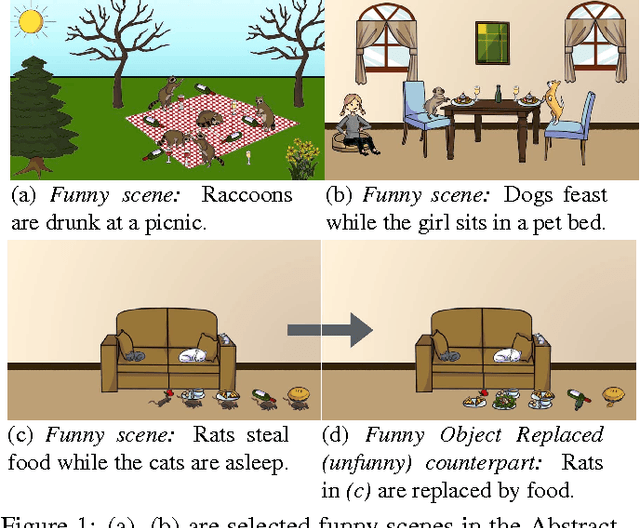



Humor is an integral part of human lives. Despite being tremendously impactful, it is perhaps surprising that we do not have a detailed understanding of humor yet. As interactions between humans and AI systems increase, it is imperative that these systems are taught to understand subtleties of human expressions such as humor. In this work, we are interested in the question - what content in a scene causes it to be funny? As a first step towards understanding visual humor, we analyze the humor manifested in abstract scenes and design computational models for them. We collect two datasets of abstract scenes that facilitate the study of humor at both the scene-level and the object-level. We analyze the funny scenes and explore the different types of humor depicted in them via human studies. We model two tasks that we believe demonstrate an understanding of some aspects of visual humor. The tasks involve predicting the funniness of a scene and altering the funniness of a scene. We show that our models perform well quantitatively, and qualitatively through human studies. Our datasets are publicly available.