 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Machine Intelligence Through Visual Question Answering
Paper and Code
Aug 31, 2016


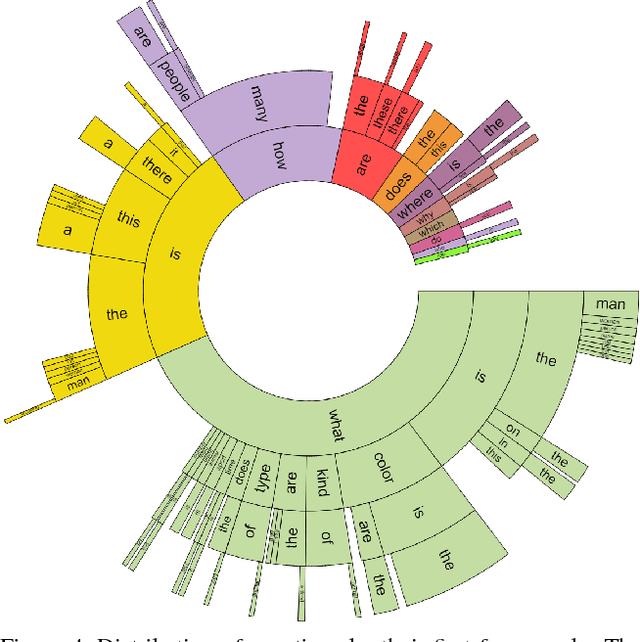
As machines have become more intelligent, there has been a renewed interest in methods for measuring their intelligence. A common approach is to propose tasks for which a human excels, but one which machines find difficult. However, an ideal task should also be easy to evaluate and not be easily gameable. We begin with a case study exploring the recently popular task of image captioning and its limitations as a task for measuring machine intelligence. An alternative and more promising task is Visual Question Answering that tests a machine's ability to reason about language and vision. We describe a dataset unprecedented in size created for the task that contains over 760,000 human generated questions about images. Using around 10 million human generated answers, machines may be easily evaluated.