 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle View Geocentric Pose in the Wild
May 18, 2021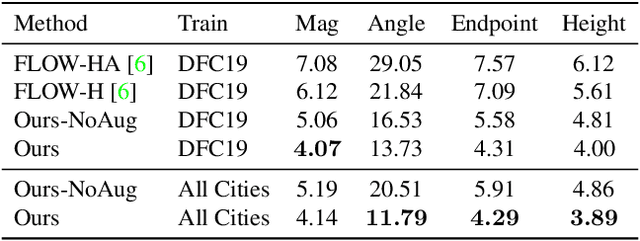
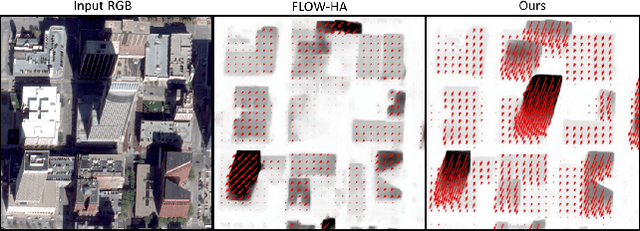
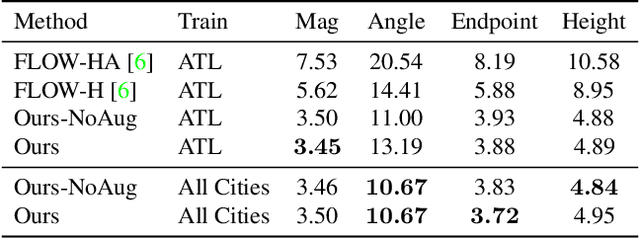
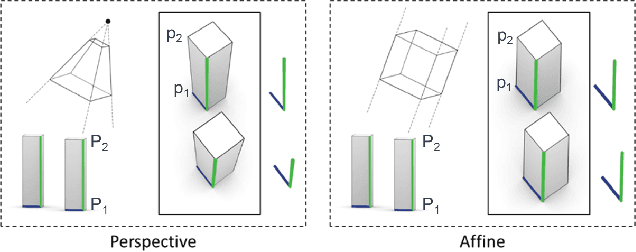
Current methods for Earth observation tasks such as semantic mapping, map alignment, and change detection rely on near-nadir images; however, often the first available images in response to dynamic world events such as natural disasters are oblique. These tasks are much more difficult for oblique images due to observed object parallax. There has been recent success in learning to regress geocentric pose, defined as height above ground and orientation with respect to gravity, by training with airborne lidar registered to satellite images. We present a model for this novel task that exploits affine invariance properties to outperform state of the art performance by a wide margin. We also address practical issues required to deploy this method in the wild for real-world applications. Our data and code are publicly available.
Towards Indirect Top-Down Road Transport Emissions Estimation
Mar 16, 2021

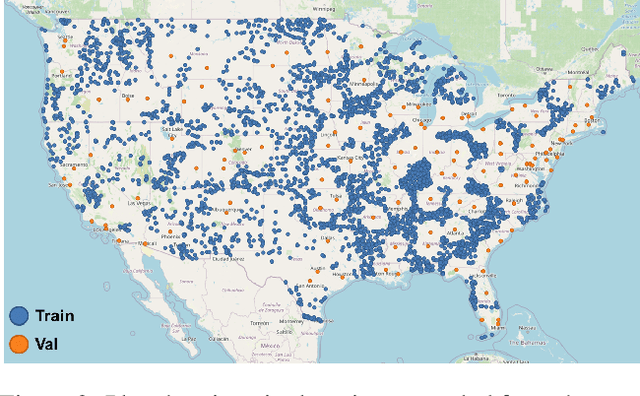

Road transportation is one of the largest sectors of greenhouse gas (GHG) emissions affecting climate change. Tackling climate change as a global community will require new capabilities to measure and inventory road transport emissions. However, the large scale and distributed nature of vehicle emissions make this sector especially challenging for existing inventory methods. In this work, we develop machine learning models that use satellite imagery to perform indirect top-down estimation of road transport emissions. Our initial experiments focus on the United States, where a bottom-up inventory was available for training our models. We achieved a mean absolute error (MAE) of 39.5 kg CO$_{2}$ of annual road transport emissions, calculated on a pixel-by-pixel (100 m$^{2}$) basis in Sentinel-2 imagery. We also discuss key model assumptions and challenges that need to be addressed to develop models capable of generalizing to global geography. We believe this work is the first published approach for automated indirect top-down estimation of road transport sector emissions using visual imagery and represents a critical step towards scalable, global, near-real-time road transportation emissions inventories that are measured both independently and objectively.
Learning Geocentric Object Pose in Oblique Monocular Images
Jul 01, 2020
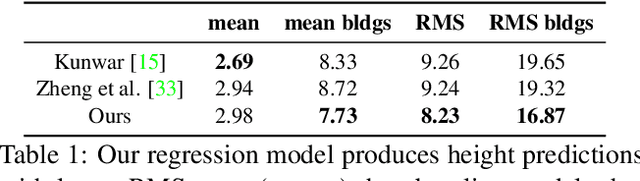
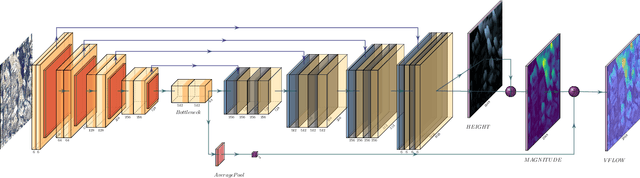

An object's geocentric pose, defined as the height above ground and orientation with respect to gravity, is a powerful representation of real-world structure for object detection, segmentation, and localization tasks using RGBD images. For close-range vision tasks, height and orientation have been derived directly from stereo-computed depth and more recently from monocular depth predicted by deep networks. For long-range vision tasks such as Earth observation, depth cannot be reliably estimated with monocular images. Inspired by recent work in monocular height above ground prediction and optical flow prediction from static images, we develop an encoding of geocentric pose to address this challenge and train a deep network to compute the representation densely, supervised by publicly available airborne lidar. We exploit these attributes to rectify oblique images and remove observed object parallax to dramatically improve the accuracy of localization and to enable accurate alignment of multiple images taken from very different oblique viewpoints. We demonstrate the value of our approach by extending two large-scale public datasets for semantic segmentation in oblique satellite images. All of our data and code are publicly available.
Estimating Displaced Populations from Overhead
Jun 25, 2020



We introduce a deep learning approach to perform fine-grained population estimation for displacement camps using high-resolution overhead imagery. We train and evaluate our approach on drone imagery cross-referenced with population data for refugee camps in Cox's Bazar, Bangladesh in 2018 and 2019. Our proposed approach achieves 7.41% mean absolute percent error on sequestered camp imagery. We believe our experiments with real-world displacement camp data constitute an important step towards the development of tools that enable the humanitarian community to effectively and rapidly respond to the global displacement crisis.
Semantic Stereo for Incidental Satellite Images
Nov 21, 2018
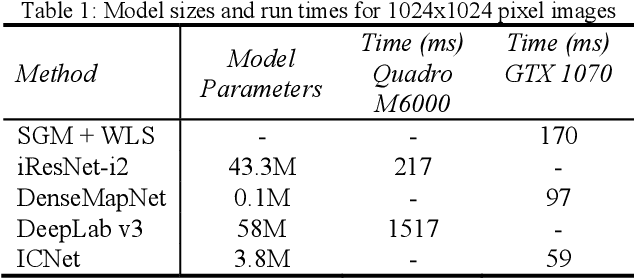

The increasingly common use of incidental satellite images for stereo reconstruction versus rigidly tasked binocular or trinocular coincident collection is helping to enable timely global-scale 3D mapping; however, reliable stereo correspondence from multi-date image pairs remains very challenging due to seasonal appearance differences and scene change. Promising recent work suggests that semantic scene segmentation can provide a robust regularizing prior for resolving ambiguities in stereo correspondence and reconstruction problems. To enable research for pairwise semantic stereo and multi-view semantic 3D reconstruction with incidental satellite images, we have established a large-scale public dataset including multi-view, multi-band satellite images and ground truth geometric and semantic labels for two large cities. To demonstrate the complementary nature of the stereo and segmentation tasks, we present lightweight public baselines adapted from recent state of the art convolutional neural network models and assess their performance.
Functional Map of the World
Apr 13, 2018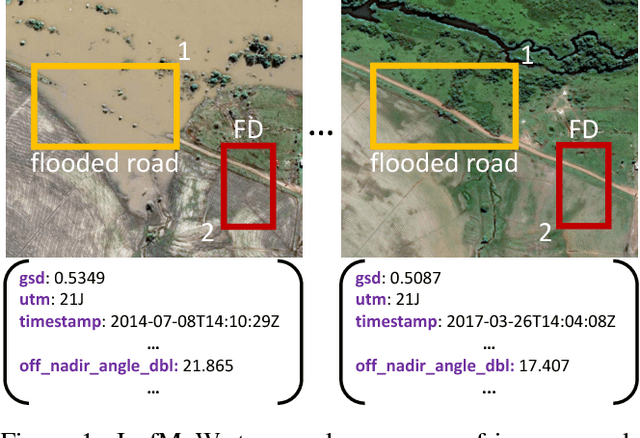
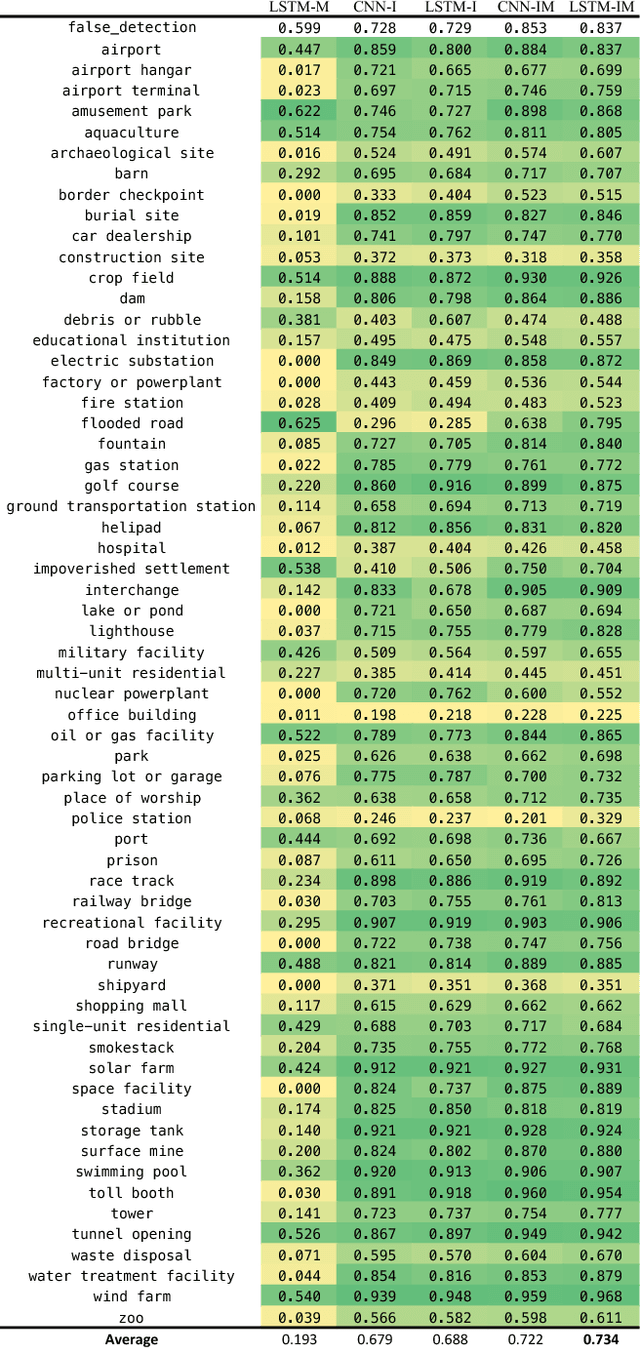


We present a new dataset, Functional Map of the World (fMoW), which aims to inspire the development of machine learning models capable of predicting the functional purpose of buildings and land use from temporal sequences of satellite images and a rich set of metadata features. The metadata provided with each image enables reasoning about location, time, sun angles, physical sizes, and other features when making predictions about objects in the image. Our dataset consists of over 1 million images from over 200 countries. For each image, we provide at least one bounding box annotation containing one of 63 categories, including a "false detection" category. We present an analysis of the dataset along with baseline approaches that reason about metadata and temporal views. Our data, code, and pretrained models have been made publicly available.
Question Relevance in VQA: Identifying Non-Visual And False-Premise Questions
Sep 26, 2016



Visual Question Answering (VQA) is the task of answering natural-language questions about images. We introduce the novel problem of determining the relevance of questions to images in VQA. Current VQA models do not reason about whether a question is even related to the given image (e.g. What is the capital of Argentina?) or if it requires information from external resources to answer correctly. This can break the continuity of a dialogue in human-machine interaction. Our approaches for determining relevance are composed of two stages. Given an image and a question, (1) we first determine whether the question is visual or not, (2) if visual, we determine whether the question is relevant to the given image or not. Our approaches, based on LSTM-RNNs, VQA model uncertainty, and caption-question similarity, are able to outperform strong baselines on both relevance tasks. We also present human studies showing that VQA models augmented with such question relevance reasoning are perceived as more intelligent, reasonable, and human-like.
Resolving Language and Vision Ambiguities Together: Joint Segmentation & Prepositional Attachment Resolution in Captioned Scenes
Sep 26, 2016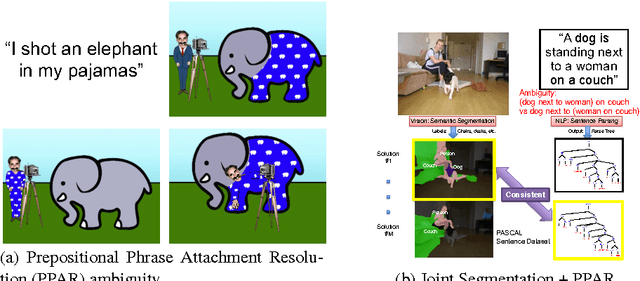
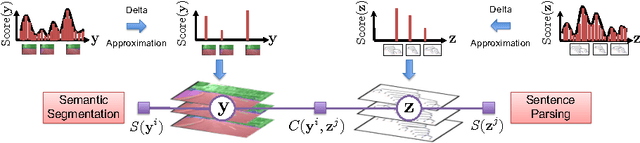
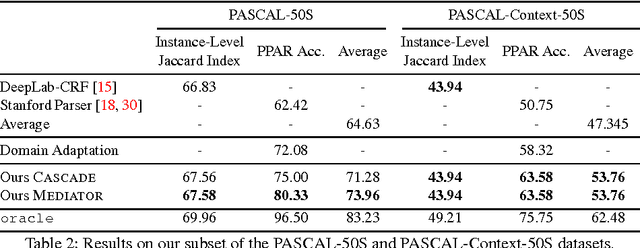
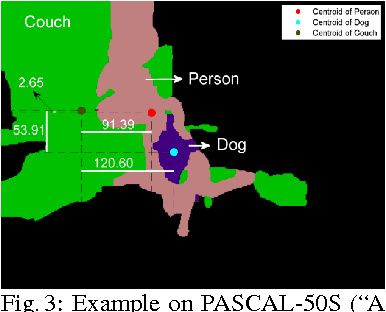
We present an approach to simultaneously perform semantic segmentation and prepositional phrase attachment resolution for captioned images. Some ambiguities in language cannot be resolved without simultaneously reasoning about an associated image. If we consider the sentence "I shot an elephant in my pajamas", looking at language alone (and not using common sense), it is unclear if it is the person or the elephant wearing the pajamas or both. Our approach produces a diverse set of plausible hypotheses for both semantic segmentation and prepositional phrase attachment resolution that are then jointly reranked to select the most consistent pair. We show that our semantic segmentation and prepositional phrase attachment resolution modules have complementary strengths, and that joint reasoning produces more accurate results than any module operating in isolation. Multiple hypotheses are also shown to be crucial to improved multiple-module reasoning. Our vision and language approach significantly outperforms the Stanford Parser (De Marneffe et al., 2006) by 17.91% (28.69% relative) and 12.83% (25.28% relative) in two different experiments. We also make small improvements over DeepLab-CRF (Chen et al., 2015).
Semantics for UGV Registration in GPS-denied Environments
Sep 19, 2016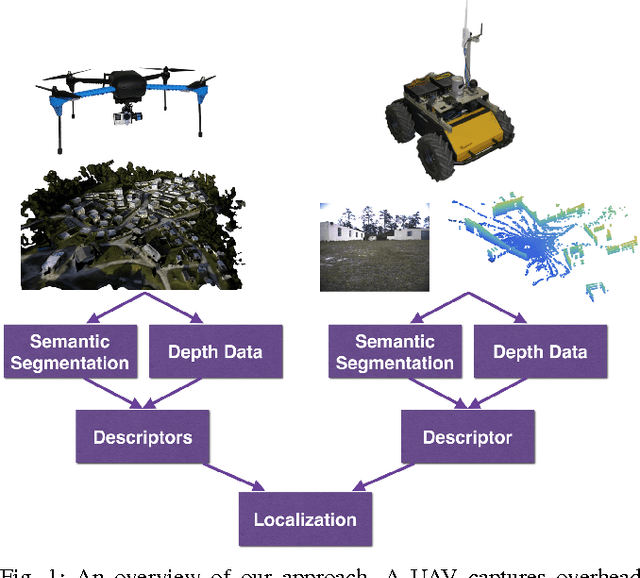

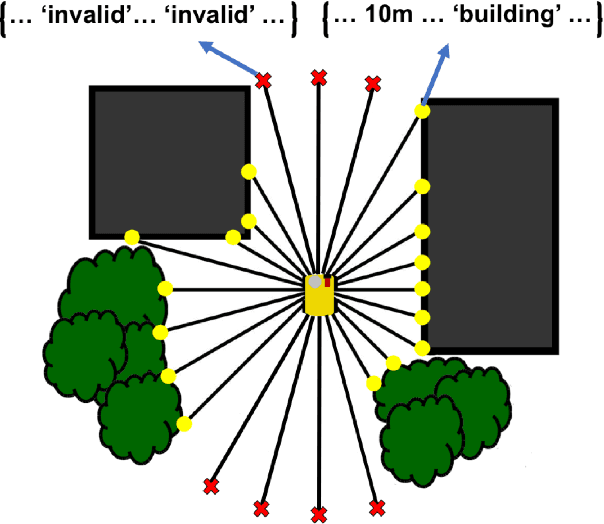

Localization in a global map is critical to success in many autonomous robot missions. This is particularly challenging for multi-robot operations in unknown and adverse environments. Here, we are concerned with providing a small unmanned ground vehicle (UGV) the ability to localize itself within a 2.5D aerial map generated from imagery captured by a low-flying unmanned aerial vehicle (UAV). We consider the scenario where GPS is unavailable and appearance-based scene changes may have occurred between the UAV's flight and the start of the UGV's mission. We present a GPS-free solution to this localization problem that is robust to appearance shifts by exploiting high-level, semantic representations of image and depth data. Using data gathered at an urban test site, we empirically demonstrate that our technique yields results within five meters of a GPS-based approach.
Radiation Search Operations using Scene Understanding with Autonomous UAV and UGV
Aug 31, 2016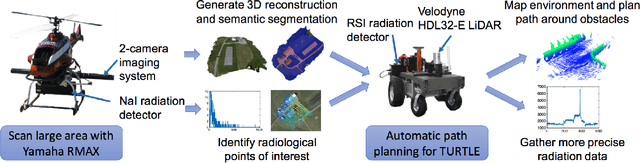


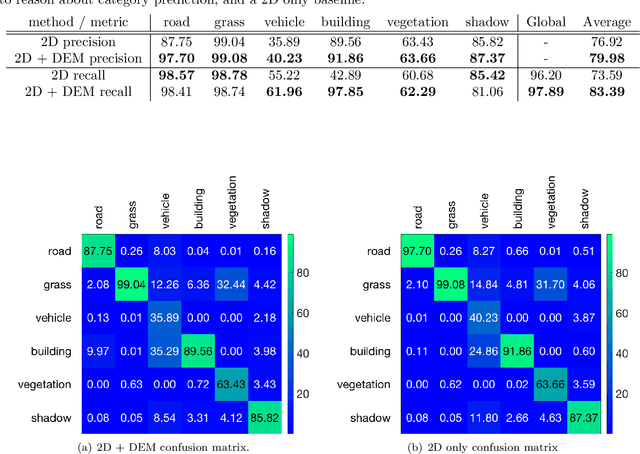
Autonomously searching for hazardous radiation sources requires the ability of the aerial and ground systems to understand the scene they are scouting. In this paper, we present systems, algorithms, and experiments to perform radiation search using unmanned aerial vehicles (UAV) and unmanned ground vehicles (UGV) by employing semantic scene segmentation. The aerial data is used to identify radiological points of interest, generate an orthophoto along with a digital elevation model (DEM) of the scene, and perform semantic segmentation to assign a category (e.g. road, grass) to each pixel in the orthophoto. We perform semantic segmentation by training a model on a dataset of images we collected and annotated, using the model to perform inference on images of the test area unseen to the model, and then refining the results with the DEM to better reason about category predictions at each pixel. We then use all of these outputs to plan a path for a UGV carrying a LiDAR to map the environment and avoid obstacles not present during the flight, and a radiation detector to collect more precise radiation measurements from the ground. Results of the analysis for each scenario tested favorably. We also note that our approach is general and has the potential to work for a variety of different sensing tasks.