 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Language and Vision Ambiguities Together: Joint Segmentation & Prepositional Attachment Resolution in Captioned Scenes
Sep 26, 2016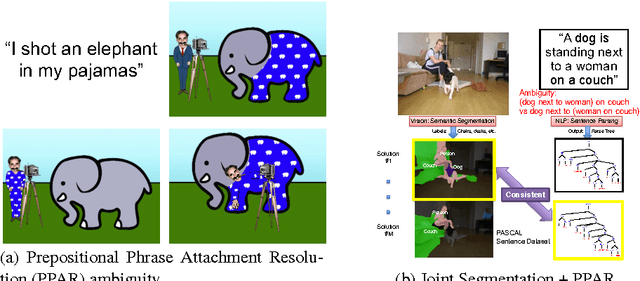
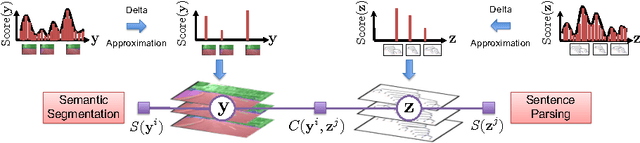
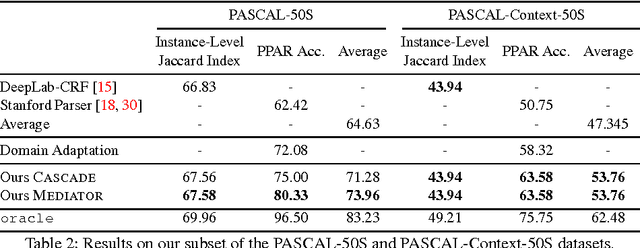
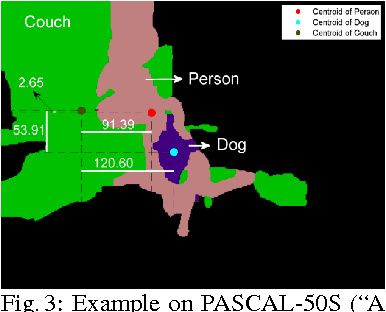
We present an approach to simultaneously perform semantic segmentation and prepositional phrase attachment resolution for captioned images. Some ambiguities in language cannot be resolved without simultaneously reasoning about an associated image. If we consider the sentence "I shot an elephant in my pajamas", looking at language alone (and not using common sense), it is unclear if it is the person or the elephant wearing the pajamas or both. Our approach produces a diverse set of plausible hypotheses for both semantic segmentation and prepositional phrase attachment resolution that are then jointly reranked to select the most consistent pair. We show that our semantic segmentation and prepositional phrase attachment resolution modules have complementary strengths, and that joint reasoning produces more accurate results than any module operating in isolation. Multiple hypotheses are also shown to be crucial to improved multiple-module reasoning. Our vision and language approach significantly outperforms the Stanford Parser (De Marneffe et al., 2006) by 17.91% (28.69% relative) and 12.83% (25.28% relative) in two different experiments. We also make small improvements over DeepLab-CRF (Chen et al., 2015).
Semantics for UGV Registration in GPS-denied Environments
Sep 19, 2016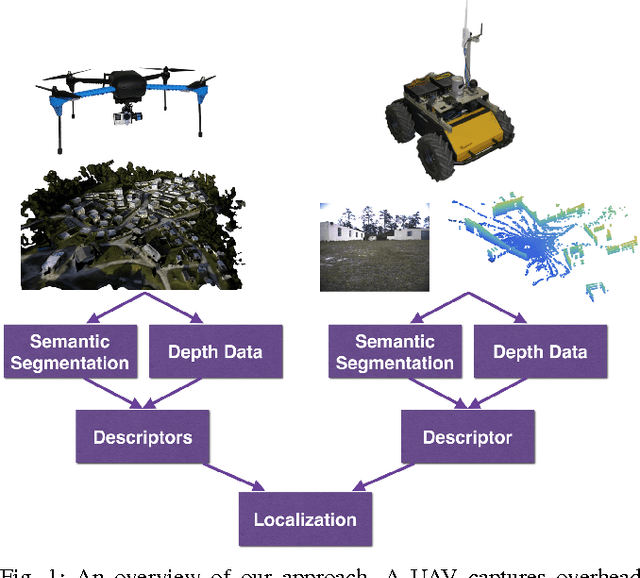

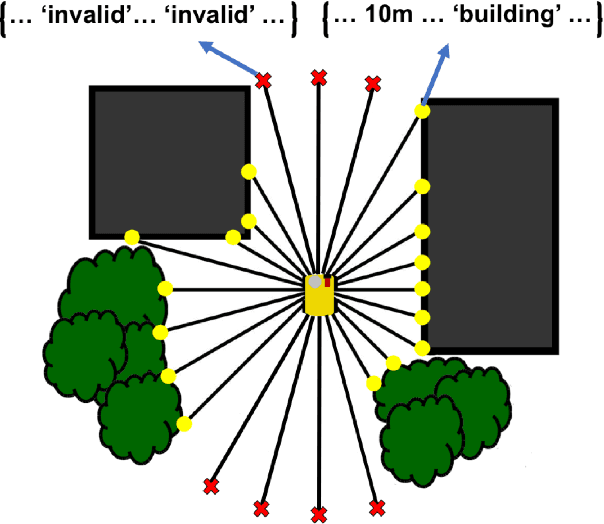

Localization in a global map is critical to success in many autonomous robot missions. This is particularly challenging for multi-robot operations in unknown and adverse environments. Here, we are concerned with providing a small unmanned ground vehicle (UGV) the ability to localize itself within a 2.5D aerial map generated from imagery captured by a low-flying unmanned aerial vehicle (UAV). We consider the scenario where GPS is unavailable and appearance-based scene changes may have occurred between the UAV's flight and the start of the UGV's mission. We present a GPS-free solution to this localization problem that is robust to appearance shifts by exploiting high-level, semantic representations of image and depth data. Using data gathered at an urban test site, we empirically demonstrate that our technique yields results within five meters of a GPS-based approach.
Radiation Search Operations using Scene Understanding with Autonomous UAV and UGV
Aug 31, 2016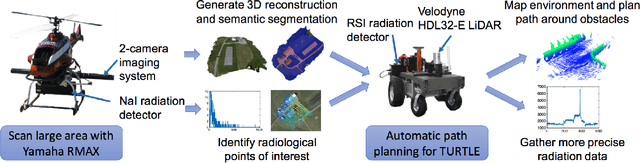


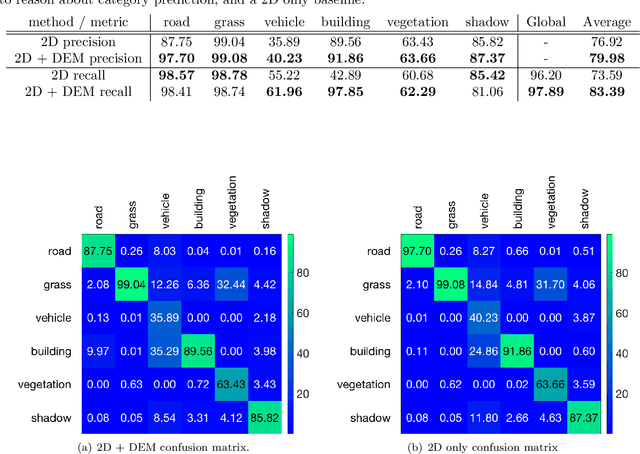
Autonomously searching for hazardous radiation sources requires the ability of the aerial and ground systems to understand the scene they are scouting. In this paper, we present systems, algorithms, and experiments to perform radiation search using unmanned aerial vehicles (UAV) and unmanned ground vehicles (UGV) by employing semantic scene segmentation. The aerial data is used to identify radiological points of interest, generate an orthophoto along with a digital elevation model (DEM) of the scene, and perform semantic segmentation to assign a category (e.g. road, grass) to each pixel in the orthophoto. We perform semantic segmentation by training a model on a dataset of images we collected and annotated, using the model to perform inference on images of the test area unseen to the model, and then refining the results with the DEM to better reason about category predictions at each pixel. We then use all of these outputs to plan a path for a UGV carrying a LiDAR to map the environment and avoid obstacles not present during the flight, and a radiation detector to collect more precise radiation measurements from the ground. Results of the analysis for each scenario tested favorably. We also note that our approach is general and has the potential to work for a variety of different sensing tasks.