 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle View Geocentric Pose in the Wild
May 18, 2021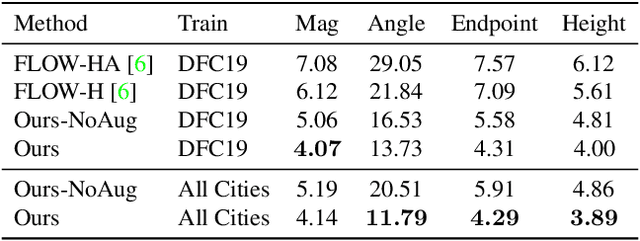
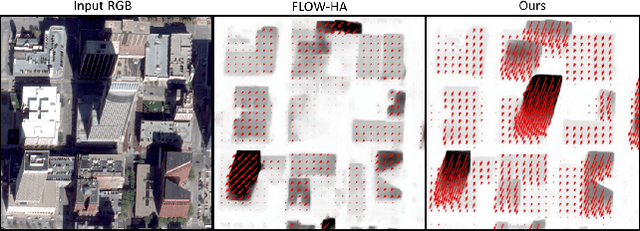
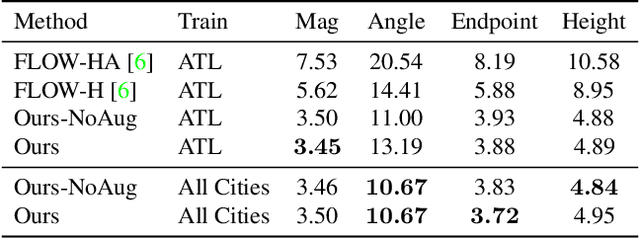
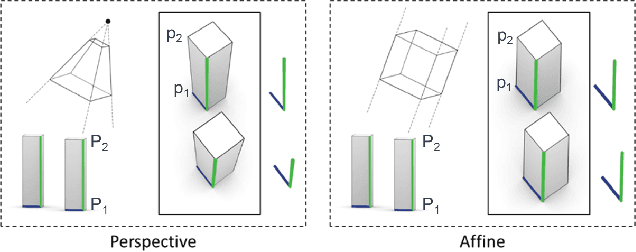
Current methods for Earth observation tasks such as semantic mapping, map alignment, and change detection rely on near-nadir images; however, often the first available images in response to dynamic world events such as natural disasters are oblique. These tasks are much more difficult for oblique images due to observed object parallax. There has been recent success in learning to regress geocentric pose, defined as height above ground and orientation with respect to gravity, by training with airborne lidar registered to satellite images. We present a model for this novel task that exploits affine invariance properties to outperform state of the art performance by a wide margin. We also address practical issues required to deploy this method in the wild for real-world applications. Our data and code are publicly available.
Learning Geocentric Object Pose in Oblique Monocular Images
Jul 01, 2020
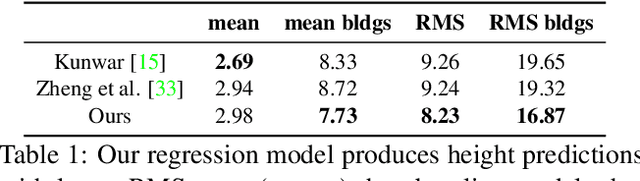
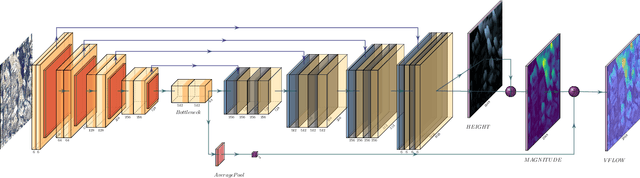

An object's geocentric pose, defined as the height above ground and orientation with respect to gravity, is a powerful representation of real-world structure for object detection, segmentation, and localization tasks using RGBD images. For close-range vision tasks, height and orientation have been derived directly from stereo-computed depth and more recently from monocular depth predicted by deep networks. For long-range vision tasks such as Earth observation, depth cannot be reliably estimated with monocular images. Inspired by recent work in monocular height above ground prediction and optical flow prediction from static images, we develop an encoding of geocentric pose to address this challenge and train a deep network to compute the representation densely, supervised by publicly available airborne lidar. We exploit these attributes to rectify oblique images and remove observed object parallax to dramatically improve the accuracy of localization and to enable accurate alignment of multiple images taken from very different oblique viewpoints. We demonstrate the value of our approach by extending two large-scale public datasets for semantic segmentation in oblique satellite images. All of our data and code are publicly available.
Semantic Stereo for Incidental Satellite Images
Nov 21, 2018
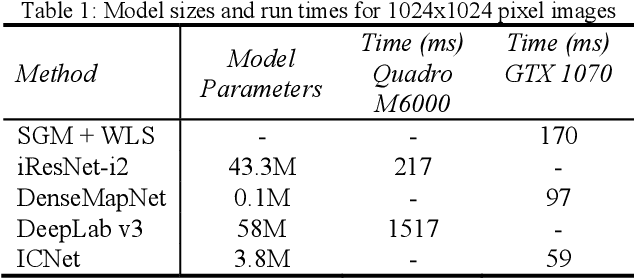
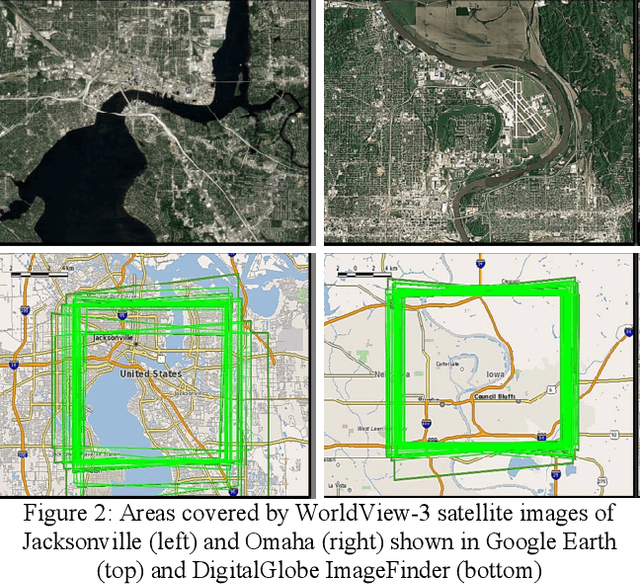

The increasingly common use of incidental satellite images for stereo reconstruction versus rigidly tasked binocular or trinocular coincident collection is helping to enable timely global-scale 3D mapping; however, reliable stereo correspondence from multi-date image pairs remains very challenging due to seasonal appearance differences and scene change. Promising recent work suggests that semantic scene segmentation can provide a robust regularizing prior for resolving ambiguities in stereo correspondence and reconstruction problems. To enable research for pairwise semantic stereo and multi-view semantic 3D reconstruction with incidental satellite images, we have established a large-scale public dataset including multi-view, multi-band satellite images and ground truth geometric and semantic labels for two large cities. To demonstrate the complementary nature of the stereo and segmentation tasks, we present lightweight public baselines adapted from recent state of the art convolutional neural network models and assess their performance.