 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocATe: End-to-end Localization of Actions in 3D with Transformers
Mar 21, 2022

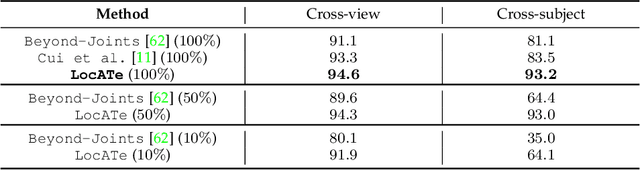
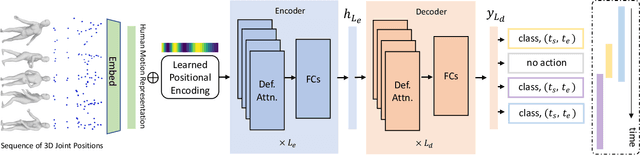
Understanding a person's behavior from their 3D motion is a fundamental problem in computer vision with many applications. An important component of this problem is 3D Temporal Action Localization (3D-TAL), which involves recognizing what actions a person is performing, and when. State-of-the-art 3D-TAL methods employ a two-stage approach in which the action span detection task and the action recognition task are implemented as a cascade. This approach, however, limits the possibility of error-correction. In contrast, we propose LocATe, an end-to-end approach that jointly localizes and recognizes actions in a 3D sequence. Further, unlike existing autoregressive models that focus on modeling the local context in a sequence, LocATe's transformer model is capable of capturing long-term correlations between actions in a sequence. Unlike transformer-based object-detection and classification models which consider image or patch features as input, the input in 3D-TAL is a long sequence of highly correlated frames. To handle the high-dimensional input, we implement an effective input representation, and overcome the diffuse attention across long time horizons by introducing sparse attention in the model. LocATe outperforms previous approaches on the existing PKU-MMD 3D-TAL benchmark (mAP=93.2%). Finally, we argue that benchmark datasets are most useful where there is clear room for performance improvement. To that end, we introduce a new, challenging, and more realistic benchmark dataset, BABEL-TAL-20 (BT20), where the performance of state-of-the-art methods is significantly worse. The dataset and code for the method will be available for research purposes.
How Much Coffee Was Consumed During EMNLP 2019? Fermi Problems: A New Reasoning Challenge for AI
Oct 27, 2021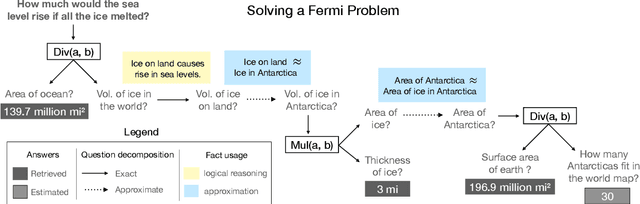



Many real-world problems require the combined application of multiple reasoning abilities employing suitable abstractions, commonsense knowledge, and creative synthesis of problem-solving strategies. To help advance AI systems towards such capabilities, we propose a new reasoning challenge, namely Fermi Problems (FPs), which are questions whose answers can only be approximately estimated because their precise computation is either impractical or impossible. For example, "How much would the sea level rise if all ice in the world melted?" FPs are commonly used in quizzes and interviews to bring out and evaluate the creative reasoning abilities of humans. To do the same for AI systems, we present two datasets: 1) A collection of 1k real-world FPs sourced from quizzes and olympiads; and 2) a bank of 10k synthetic FPs of intermediate complexity to serve as a sandbox for the harder real-world challenge. In addition to question answer pairs, the datasets contain detailed solutions in the form of an executable program and supporting facts, helping in supervision and evaluation of intermediate steps. We demonstrate that even extensively fine-tuned large scale language models perform poorly on these datasets, on average making estimates that are off by two orders of magnitude. Our contribution is thus the crystallization of several unsolved AI problems into a single, new challenge that we hope will spur further advances in building systems that can reason.
BABEL: Bodies, Action and Behavior with English Labels
Jun 23, 2021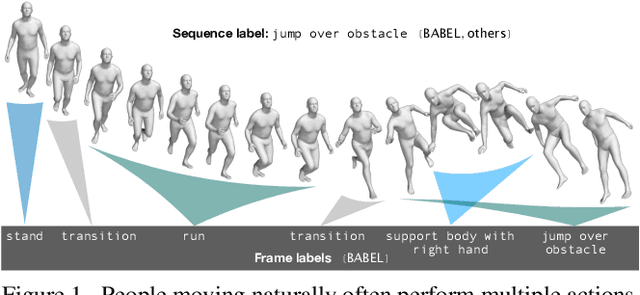
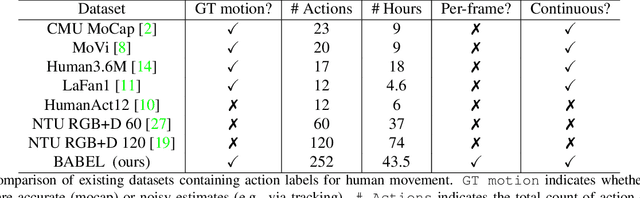


Understanding the semantics of human movement -- the what, how and why of the movement -- is an important problem that requires datasets of human actions with semantic labels. Existing datasets take one of two approaches. Large-scale video datasets contain many action labels but do not contain ground-truth 3D human motion. Alternatively, motion-capture (mocap) datasets have precise body motions but are limited to a small number of actions. To address this, we present BABEL, a large dataset with language labels describing the actions being performed in mocap sequences. BABEL consists of action labels for about 43 hours of mocap sequences from AMASS. Action labels are at two levels of abstraction -- sequence labels describe the overall action in the sequence, and frame labels describe all actions in every frame of the sequence. Each frame label is precisely aligned with the duration of the corresponding action in the mocap sequence, and multiple actions can overlap. There are over 28k sequence labels, and 63k frame labels in BABEL, which belong to over 250 unique action categories. Labels from BABEL can be leveraged for tasks like action recognition, temporal action localization, motion synthesis, etc. To demonstrate the value of BABEL as a benchmark, we evaluate the performance of models on 3D action recognition. We demonstrate that BABEL poses interesting learning challenges that are applicable to real-world scenarios, and can serve as a useful benchmark of progress in 3D action recognition. The dataset, baseline method, and evaluation code is made available, and supported for academic research purposes at https://babel.is.tue.mpg.de/.
Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings
Oct 16, 2020


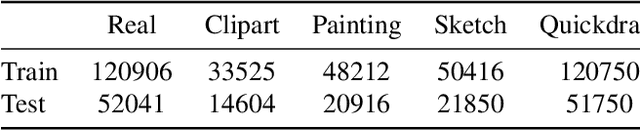
Generalizing deep neural networks to new target domains is critical to their real-world utility. In practice, it may be feasible to get some target data labeled, but to be cost-effective it is desirable to select a maximally-informative subset via active learning (AL). We study this problem of AL under a domain shift. We empirically demonstrate how existing AL approaches based solely on model uncertainty or representative sampling are suboptimal for active domain adaptation. Our algorithm, Active Domain Adaptation via CLustering Uncertainty-weighted Embeddings (ADA-CLUE), i) identifies diverse datapoints for labeling that are both uncertain under the model and representative of unlabeled target data, and ii) leverages the available source and target data for adaptation by optimizing a semi-supervised adversarial entropy loss that is complementary to our active sampling objective. On standard image classification benchmarks for domain adaptation, ADA-CLUE consistently performs as well or better than competing active adaptation, active learning, and domain adaptation methods across shift severities, model initializations, and labeling budgets.
A Computational Model of Early Word Learning from the Infant's Point of View
Jun 04, 2020
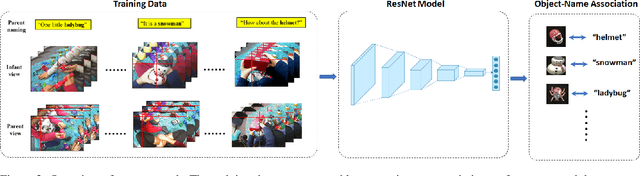


Human infants have the remarkable ability to learn the associations between object names and visual objects from inherently ambiguous experiences. Researchers in cognitive science and developmental psychology have built formal models that implement in-principle learning algorithms, and then used pre-selected and pre-cleaned datasets to test the abilities of the models to find statistical regularities in the input data. In contrast to previous modeling approaches, the present study used egocentric video and gaze data collected from infant learners during natural toy play with their parents. This allowed us to capture the learning environment from the perspective of the learner's own point of view. We then used a Convolutional Neural Network (CNN) model to process sensory data from the infant's point of view and learn name-object associations from scratch. As the first model that takes raw egocentric video to simulate infant word learning, the present study provides a proof of principle that the problem of early word learning can be solved, using actual visual data perceived by infant learners. Moreover, we conducted simulation experiments to systematically determine how visual, perceptual, and attentional properties of infants' sensory experiences may affect word learning.
Do Explanations make VQA Models more Predictable to a Human?
Oct 29, 2018



A rich line of research attempts to make deep neural networks more transparent by generating human-interpretable 'explanations' of their decision process, especially for interactive tasks like Visual Question Answering (VQA). In this work, we analyze if existing explanations indeed make a VQA model -- its responses as well as failures -- more predictable to a human. Surprisingly, we find that they do not. On the other hand, we find that human-in-the-loop approaches that treat the model as a black-box do.
Punny Captions: Witty Wordplay in Image Descriptions
May 31, 2018
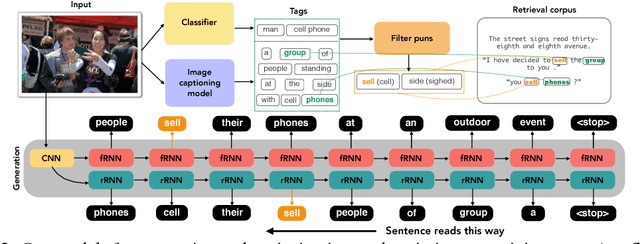
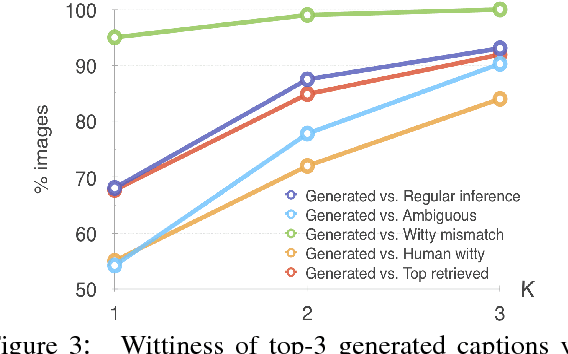

Wit is a form of rich interaction that is often grounded in a specific situation (e.g., a comment in response to an event). In this work, we attempt to build computational models that can produce witty descriptions for a given image. Inspired by a cognitive account of humor appreciation, we employ linguistic wordplay, specifically puns, in image descriptions. We develop two approaches which involve retrieving witty descriptions for a given image from a large corpus of sentences, or generating them via an encoder-decoder neural network architecture. We compare our approach against meaningful baseline approaches via human studies and show substantial improvements. We find that when a human is subject to similar constraints as the model regarding word usage and style, people vote the image descriptions generated by our model to be slightly wittier than human-written witty descriptions. Unsurprisingly, humans are almost always wittier than the model when they are free to choose the vocabulary, style, etc.
It Takes Two to Tango: Towards Theory of AI's Mind
Oct 02, 2017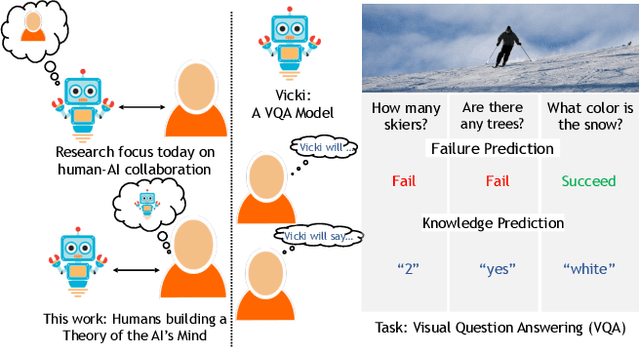


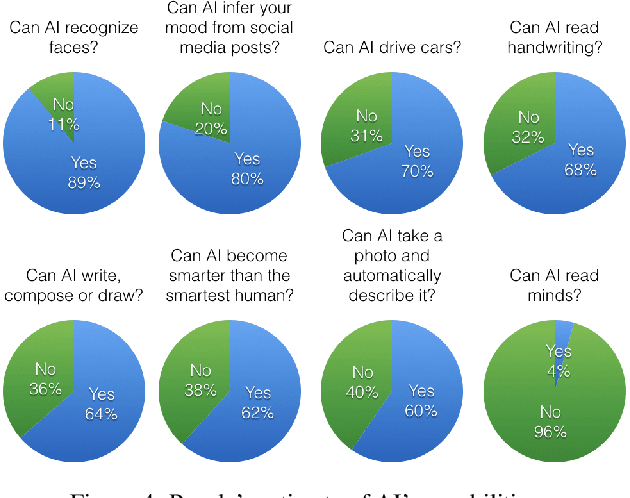
Theory of Mind is the ability to attribute mental states (beliefs, intents, knowledge, perspectives, etc.) to others and recognize that these mental states may differ from one's own. Theory of Mind is critical to effective communication and to teams demonstrating higher collective performance. To effectively leverage the progress in Artificial Intelligence (AI) to make our lives more productive, it is important for humans and AI to work well together in a team. Traditionally, there has been much emphasis on research to make AI more accurate, and (to a lesser extent) on having it better understand human intentions, tendencies, beliefs, and contexts. The latter involves making AI more human-like and having it develop a theory of our minds. In this work, we argue that for human-AI teams to be effective, humans must also develop a theory of AI's mind (ToAIM) - get to know its strengths, weaknesses, beliefs, and quirks. We instantiate these ideas within the domain of Visual Question Answering (VQA). We find that using just a few examples (50), lay people can be trained to better predict responses and oncoming failures of a complex VQA model. We further evaluate the role existing explanation (or interpretability) modalities play in helping humans build ToAIM. Explainable AI has received considerable scientific and popular attention in recent times. Surprisingly, we find that having access to the model's internal states - its confidence in its top-k predictions, explicit or implicit attention maps which highlight regions in the image (and words in the question) the model is looking at (and listening to) while answering a question about an image - do not help people better predict its behavior.
Evaluating Visual Conversational Agents via Cooperative Human-AI Games
Aug 17, 2017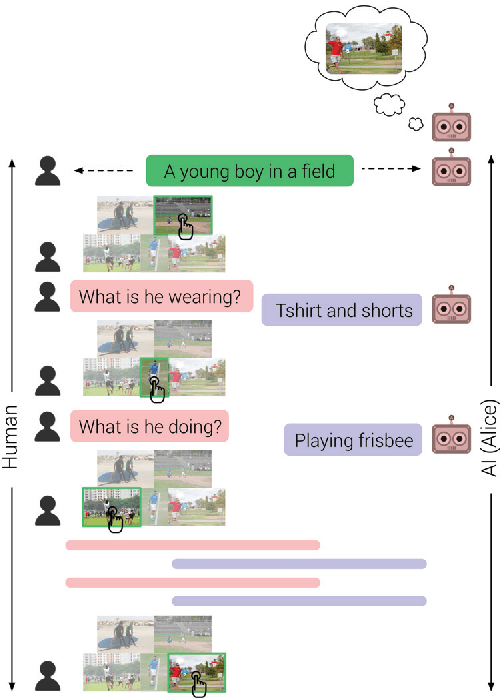


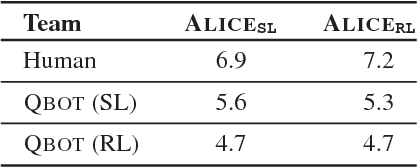
As AI continues to advance, human-AI teams are inevitable. However, progress in AI is routinely measured in isolation, without a human in the loop. It is crucial to benchmark progress in AI, not just in isolation, but also in terms of how it translates to helping humans perform certain tasks, i.e., the performance of human-AI teams. In this work, we design a cooperative game - GuessWhich - to measure human-AI team performance in the specific context of the AI being a visual conversational agent. GuessWhich involves live interaction between the human and the AI. The AI, which we call ALICE, is provided an image which is unseen by the human. Following a brief description of the image, the human questions ALICE about this secret image to identify it from a fixed pool of images. We measure performance of the human-ALICE team by the number of guesses it takes the human to correctly identify the secret image after a fixed number of dialog rounds with ALICE. We compare performance of the human-ALICE teams for two versions of ALICE. Our human studies suggest a counterintuitive trend - that while AI literature shows that one version outperforms the other when paired with an AI questioner bot, we find that this improvement in AI-AI performance does not translate to improved human-AI performance. This suggests a mismatch between benchmarking of AI in isolation and in the context of human-AI teams.
Sort Story: Sorting Jumbled Images and Captions into Stories
Nov 07, 2016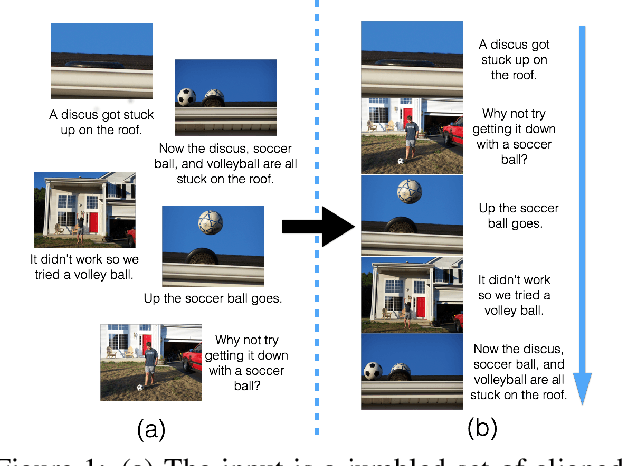


Temporal common sense has applications in AI tasks such as QA, multi-document summarization, and human-AI communication. We propose the task of sequencing -- given a jumbled set of aligned image-caption pairs that belong to a story, the task is to sort them such that the output sequence forms a coherent story. We present multiple approaches, via unary (position) and pairwise (order) predictions, and their ensemble-based combinations, achieving strong results on this task. We use both text-based and image-based features, which depict complementary improvements. Using qualitative examples, we demonstrate that our models have learnt interesting aspects of temporal common sense.