 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Domain Adaptation via Clustering Uncertainty-weighted Embeddings
Paper and Code



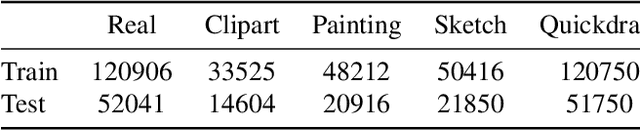
Generalizing deep neural networks to new target domains is critical to their real-world utility. In practice, it may be feasible to get some target data labeled, but to be cost-effective it is desirable to select a maximally-informative subset via active learning (AL). We study this problem of AL under a domain shift. We empirically demonstrate how existing AL approaches based solely on model uncertainty or representative sampling are suboptimal for active domain adaptation. Our algorithm, Active Domain Adaptation via CLustering Uncertainty-weighted Embeddings (ADA-CLUE), i) identifies diverse datapoints for labeling that are both uncertain under the model and representative of unlabeled target data, and ii) leverages the available source and target data for adaptation by optimizing a semi-supervised adversarial entropy loss that is complementary to our active sampling objective. On standard image classification benchmarks for domain adaptation, ADA-CLUE consistently performs as well or better than competing active adaptation, active learning, and domain adaptation methods across shift severities, model initializations, and labeling budgets.