 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocATe: End-to-end Localization of Actions in 3D with Transformers
Paper and Code


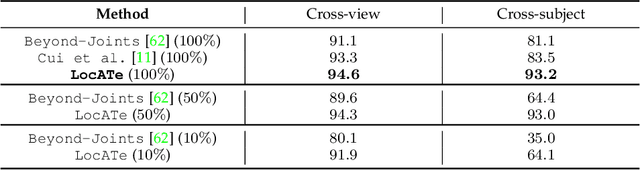
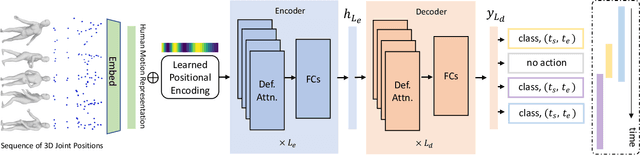
Understanding a person's behavior from their 3D motion is a fundamental problem in computer vision with many applications. An important component of this problem is 3D Temporal Action Localization (3D-TAL), which involves recognizing what actions a person is performing, and when. State-of-the-art 3D-TAL methods employ a two-stage approach in which the action span detection task and the action recognition task are implemented as a cascade. This approach, however, limits the possibility of error-correction. In contrast, we propose LocATe, an end-to-end approach that jointly localizes and recognizes actions in a 3D sequence. Further, unlike existing autoregressive models that focus on modeling the local context in a sequence, LocATe's transformer model is capable of capturing long-term correlations between actions in a sequence. Unlike transformer-based object-detection and classification models which consider image or patch features as input, the input in 3D-TAL is a long sequence of highly correlated frames. To handle the high-dimensional input, we implement an effective input representation, and overcome the diffuse attention across long time horizons by introducing sparse attention in the model. LocATe outperforms previous approaches on the existing PKU-MMD 3D-TAL benchmark (mAP=93.2%). Finally, we argue that benchmark datasets are most useful where there is clear room for performance improvement. To that end, we introduce a new, challenging, and more realistic benchmark dataset, BABEL-TAL-20 (BT20), where the performance of state-of-the-art methods is significantly worse. The dataset and code for the method will be available for research purposes.