 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming Manufacturing Robots with Imperfect AI: LLMs as Tuning Experts for FDM Print Configuration Selection
Mar 23, 2026We use fused deposition modeling (FDM) 3D printing as a case study of how manufacturing robots can use imperfect AI to acquire process expertise. In FDM, print configuration strongly affects output quality. Yet, novice users typically rely on default configurations, trial-and-error, or recommendations from generic AI models (e.g., ChatGPT). These strategies can produce complete prints, but they do not reliably meet specific objectives. Experts iteratively tune print configurations using evidence from prior prints. We present a modular closed-loop approach that treats an LLM as a source of tuning expertise. We embed this source of expertise within a Bayesian optimization loop. An approximate evaluator scores each print configuration and returns structured diagnostics, which the LLM uses to propose natural-language adjustments that are compiled into machine-actionable guidance for optimization. On 100 Thingi10k parts, our LLM-guided loop achieves the best configuration on 78% objects with 0% likely-to-fail cases, while single-shot AI model recommendations are rarely best and exhibit 15% likely-to-fail cases. These results suggest that LLMs provide more value as constrained decision modules in evidence-driven optimization loops than as end-to-end oracles for print configuration selection. We expect this result to extend to broader LLM-based robot programming.
THOR2: Leveraging Topological Soft Clustering of Color Space for Human-Inspired Object Recognition in Unseen Environments
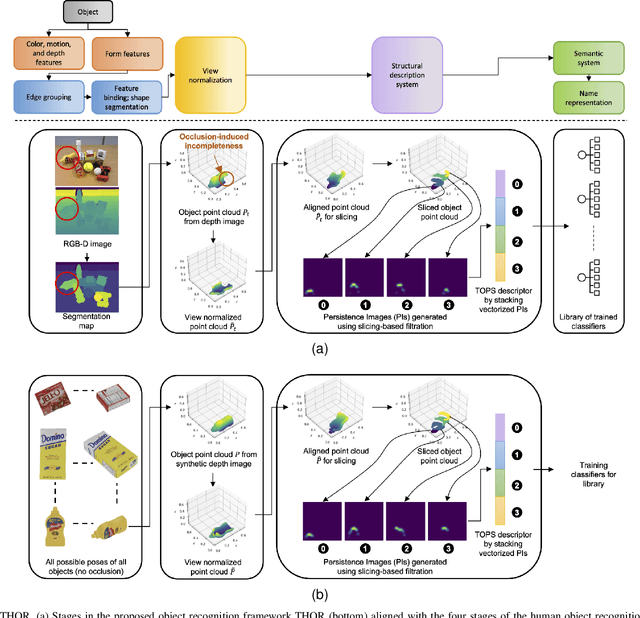
Aug 02, 2024Visual object recognition in unseen and cluttered indoor environments is a challenging problem for mobile robots. This study presents a 3D shape and color-based descriptor, TOPS2, for point clouds generated from RGB-D images and an accompanying recognition framework, THOR2. The TOPS2 descriptor embodies object unity, a human cognition mechanism, by retaining the slicing-based topological representation of 3D shape from the TOPS descriptor while capturing object color information through slicing-based color embeddings computed using a network of coarse color regions. These color regions, analogous to the MacAdam ellipses identified in human color perception, are obtained using the Mapper algorithm, a topological soft-clustering technique. THOR2, trained using synthetic data, demonstrates markedly improved recognition accuracy compared to THOR, its 3D shape-based predecessor, on two benchmark real-world datasets: the OCID dataset capturing cluttered scenes from different viewpoints and the UW-IS Occluded dataset reflecting different environmental conditions and degrees of object occlusion recorded using commodity hardware. THOR2 also outperforms baseline deep learning networks, and a widely-used ViT adapted for RGB-D inputs on both the datasets. Therefore, THOR2 is a promising step toward achieving robust recognition in low-cost robots.
Human-Inspired Topological Representations for Visual Object Recognition in Unseen Environments
Sep 15, 2023Visual object recognition in unseen and cluttered indoor environments is a challenging problem for mobile robots. Toward this goal, we extend our previous work to propose the TOPS2 descriptor, and an accompanying recognition framework, THOR2, inspired by a human reasoning mechanism known as object unity. We interleave color embeddings obtained using the Mapper algorithm for topological soft clustering with the shape-based TOPS descriptor to obtain the TOPS2 descriptor. THOR2, trained using synthetic data, achieves substantially higher recognition accuracy than the shape-based THOR framework and outperforms RGB-D ViT on two real-world datasets: the benchmark OCID dataset and the UW-IS Occluded dataset. Therefore, THOR2 is a promising step toward achieving robust recognition in low-cost robots.
Persistent Homology Meets Object Unity: Object Recognition in Clutter
May 05, 2023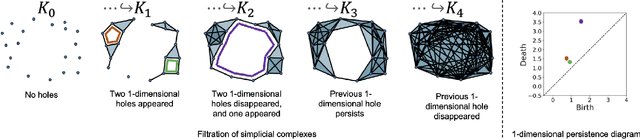

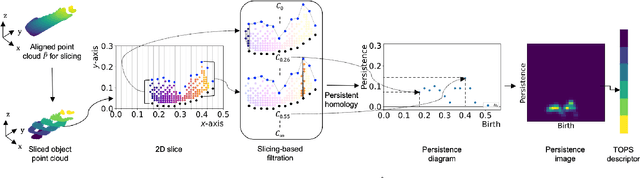
Recognition of occluded objects in unseen and unstructured indoor environments is a challenging problem for mobile robots. To address this challenge, we propose a new descriptor, TOPS, for point clouds generated from depth images and an accompanying recognition framework, THOR, inspired by human reasoning. The descriptor employs a novel slicing-based approach to compute topological features from filtrations of simplicial complexes using persistent homology, and facilitates reasoning-based recognition using object unity. Apart from a benchmark dataset, we report performance on a new dataset, the UW Indoor Scenes (UW-IS) Occluded dataset, curated using commodity hardware to reflect real-world scenarios with different environmental conditions and degrees of object occlusion. THOR outperforms state-of-the-art methods on both the datasets and achieves substantially higher recognition accuracy for all the scenarios of the UW-IS Occluded dataset. Therefore, THOR, is a promising step toward robust recognition in low-cost robots, meant for everyday use in indoor settings.
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023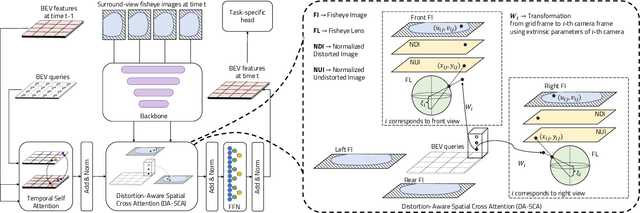



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
Topologically Persistent Features-based Object Recognition in Cluttered Indoor Environments
May 16, 2022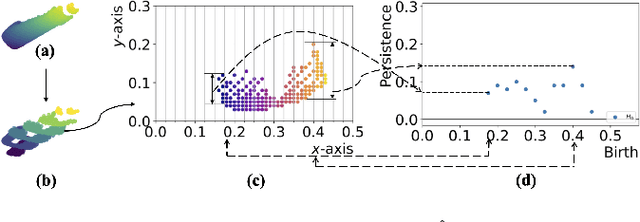
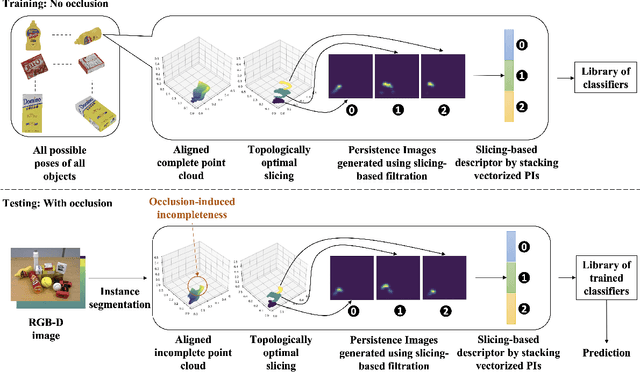

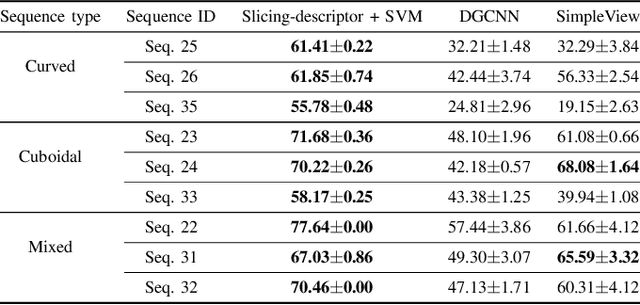
Recognition of occluded objects in unseen indoor environments is a challenging problem for mobile robots. This work proposes a new slicing-based topological descriptor that captures the 3D shape of object point clouds to address this challenge. It yields similarities between the descriptors of the occluded and the corresponding unoccluded objects, enabling object unity-based recognition using a library of trained models. The descriptor is obtained by partitioning an object's point cloud into multiple 2D slices and constructing filtrations (nested sequences of simplicial complexes) on the slices to mimic further slicing of the slices, thereby capturing detailed shapes through persistent homology-generated features. We use nine different sequences of cluttered scenes from a benchmark dataset for performance evaluation. Our method outperforms two state-of-the-art deep learning-based point cloud classification methods, namely, DGCNN and SimpleView.
Vision-Based Object Recognition in Indoor Environments Using Topologically Persistent Features
Oct 17, 2020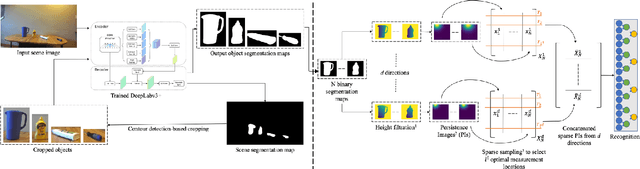



Object recognition in unseen indoor environments remains a challenging problem for visual perception of mobile robots. In this letter, we propose the use of topologically persistent features, which rely on the shape information of the objects, to address this challenge. In particular, we extract two kinds of features, namely, sparse persistence image (PI) and amplitude, by applying persistent homology to multi-directional height function-based filtrations of the cubical complexes representing the object segmentation maps. The features are then used to train a fully connected network for recognition. For performance evaluation, in addition to a widely-used shape dataset, we collect a new dataset comprising scene images from two different environments, namely, a living room and a mock warehouse. The scenes in both the environments include up to five different objects that are chosen from a given set of fourteen objects. The objects have varying poses and arrangements, and are imaged under different illumination conditions and camera poses. The recognition performance of our methods, which are trained using the living room images, remains relatively unaffected on the unseen warehouse images. In contrast, the performance of the state-of-the-art Faster R-CNN method decreases significantly. In fact, the use of sparse PI features yields higher overall recall and accuracy; and, better F1 scores on many of the individual object classes. We also implement the proposed method on a real-world robot to demonstrate its usefulness.
Deep Learning-Based Semantic Segmentation of Microscale Objects
Jul 03, 2019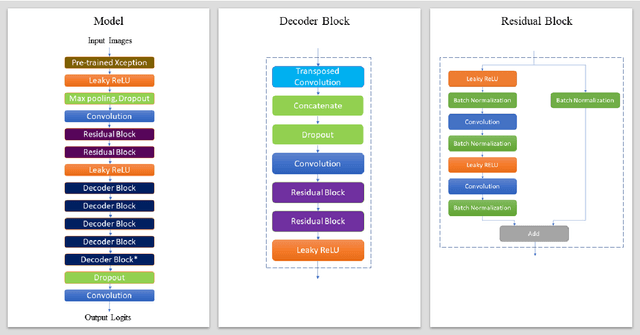



Accurate estimation of the positions and shapes of microscale objects is crucial for automated imaging-guided manipulation using a non-contact technique such as optical tweezers. Perception methods that use traditional computer vision algorithms tend to fail when the manipulation environments are crowded. In this paper, we present a deep learning model for semantic segmentation of the images representing such environments. Our model successfully performs segmentation with a high mean Intersection Over Union score of 0.91.
Predicting Ergonomic Risks During Indoor Object Manipulation Using Spatiotemporal Convolutional Networks
Feb 14, 2019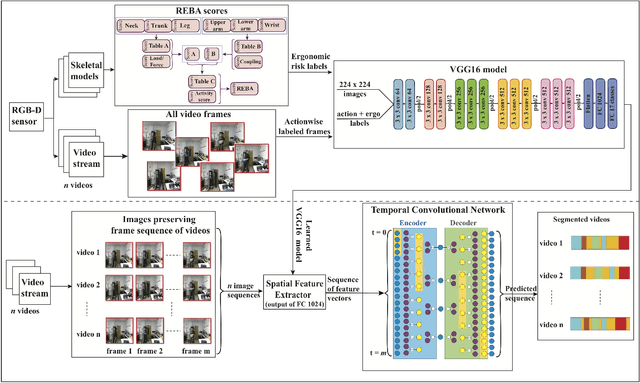

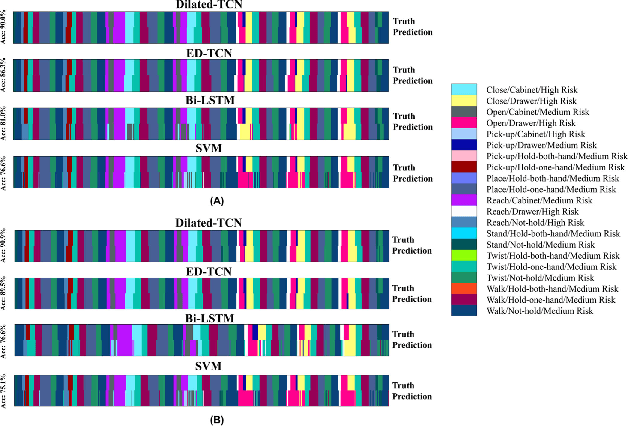
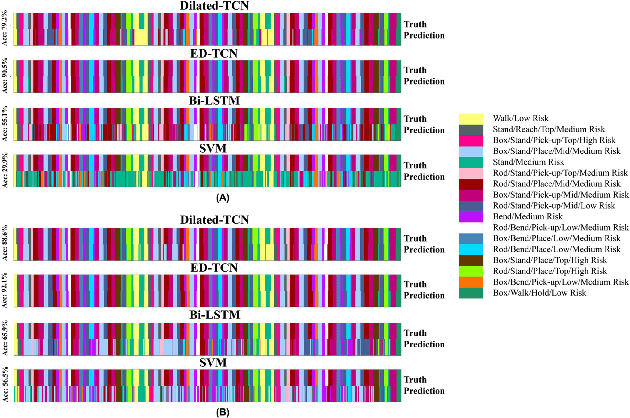
Automated real-time prediction of the ergonomic risks of manipulating objects is a key unsolved challenge in developing effective human-robot collaboration systems for logistics and manufacturing applications. We present a foundational paradigm to address this challenge by formulating the problem as one of action segmentation from RGB-D camera videos. Spatial features are first learned using a deep convolutional model from the video frames, which are then fed sequentially to temporal convolutional networks to semantically segment the frames into a hierarchy of actions, which are either ergonomically safe, require monitoring, or need immediate attention. For performance evaluation, in addition to an open-source kitchen dataset, we collected a new dataset comprising twenty individuals picking up and placing objects of varying weights to and from cabinet and table locations at various heights. Results show very high (87-94)% F1 overlap scores among the ground truth and predicted frame labels for videos lasting over two minutes and comprising a large number of actions.