 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOFFEE: COdesign Framework for Feature Enriched Embeddings in Ads-Ranking Systems
Jan 06, 2026Diverse and enriched data sources are essential for commercial ads-recommendation models to accurately assess user interest both before and after engagement with content. While extended user-engagement histories can improve the prediction of user interests, it is equally important to embed activity sequences from multiple sources to ensure freshness of user and ad-representations, following scaling law principles. In this paper, we present a novel three-dimensional framework for enhancing user-ad representations without increasing model inference or serving complexity. The first dimension examines the impact of incorporating diverse event sources, the second considers the benefits of longer user histories, and the third focuses on enriching data with additional event attributes and multi-modal embeddings. We assess the return on investment (ROI) of our source enrichment framework by comparing organic user engagement sources, such as content viewing, with ad-impression sources. The proposed method can boost the area under curve (AUC) and the slope of scaling curves for ad-impression sources by 1.56 to 2 times compared to organic usage sources even for short online-sequence lengths of 100 to 10K. Additionally, click-through rate (CTR) prediction improves by 0.56% AUC over the baseline production ad-recommendation system when using enriched ad-impression event sources, leading to improved sequence scaling resolutions for longer and offline user-ad representations.
* 4 pages, 5 figures, 1 table
FiST-Financial Style Transfer with Hallucination and Creativity Control Framework
Aug 09, 2024Financial report generation using general purpose large language models pose two major challenges, including the lack of compound sentences and hallucinations. Advanced prompt engineering and retrieval augmented generation (RAG) techniques are incapable of curing the writing style discrepancies. In this work we propose a novel two-stage fine-tuning process wherein public domain financial reports are processed into prompt-completions and augmented using simple LLM prompts to then enable sectional financial report generation using minimal instructions and tabular data inputs. Our proposed fine-tuning framework results doubles the number of correct questions answers and reduces hallucinations by over 50%. Additionally, the two-stage fine tuned models have lower perplexity, improved ROUGE, TER and BLEU scores, higher creativity and knowledge density with lower uncertainty and cross entropy.
ERATTA: Extreme RAG for Table To Answers with Large Language Models
May 07, 2024



Large language models (LLMs) with residual augmented-generation (RAG) have been the optimal choice for scalable generative AI solutions in the recent past. However, the choice of use-cases that incorporate RAG with LLMs have been either generic or extremely domain specific, thereby questioning the scalability and generalizability of RAG-LLM approaches. In this work, we propose a unique LLM-based system where multiple LLMs can be invoked to enable data authentication, user query routing, data retrieval and custom prompting for question answering capabilities from data tables that are highly varying and large in size. Our system is tuned to extract information from Enterprise-level data products and furnish real time responses under 10 seconds. One prompt manages user-to-data authentication followed by three prompts to route, fetch data and generate a customizable prompt natural language responses. Additionally, we propose a five metric scoring module that detects and reports hallucinations in the LLM responses. Our proposed system and scoring metrics achieve >90% confidence scores across hundreds of user queries in the sustainability, financial health and social media domains. Extensions to the proposed extreme RAG architectures can enable heterogeneous source querying using LLMs.
Journey of Hallucination-minimized Generative AI Solutions for Financial Decision Makers
Nov 18, 2023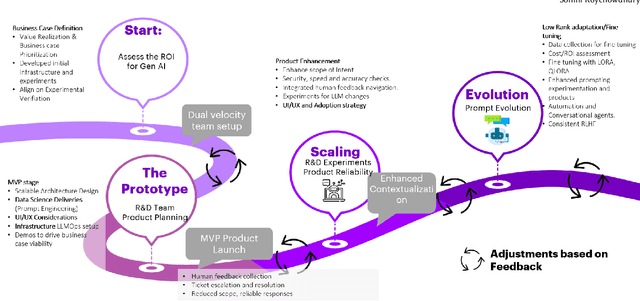
Generative AI has significantly reduced the entry barrier to the domain of AI owing to the ease of use and core capabilities of automation, translation, and intelligent actions in our day to day lives. Currently, Large language models (LLMs) that power such chatbots are being utilized primarily for their automation capabilities for software monitoring, report generation etc. and for specific personalized question answering capabilities, on a limited scope and scale. One major limitation of the currently evolving family of LLMs is 'hallucinations', wherein inaccurate responses are reported as factual. Hallucinations are primarily caused by biased training data, ambiguous prompts and inaccurate LLM parameters, and they majorly occur while combining mathematical facts with language-based context. Thus, monitoring and controlling for hallucinations becomes necessary when designing solutions that are meant for decision makers. In this work we present the three major stages in the journey of designing hallucination-minimized LLM-based solutions that are specialized for the decision makers of the financial domain, namely: prototyping, scaling and LLM evolution using human feedback. These three stages and the novel data to answer generation modules presented in this work are necessary to ensure that the Generative AI chatbots, autonomous reports and alerts are reliable and high-quality to aid key decision-making processes.
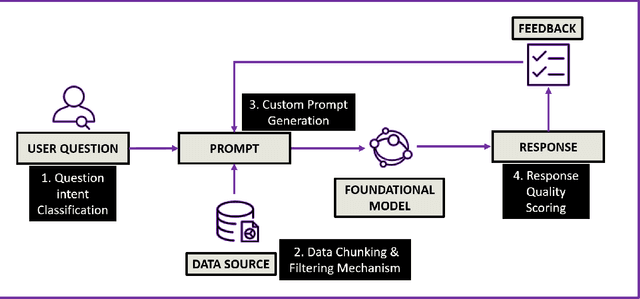
Hallucination-minimized Data-to-answer Framework for Financial Decision-makers
Nov 09, 2023Large Language Models (LLMs) have been applied to build several automation and personalized question-answering prototypes so far. However, scaling such prototypes to robust products with minimized hallucinations or fake responses still remains an open challenge, especially in niche data-table heavy domains such as financial decision making. In this work, we present a novel Langchain-based framework that transforms data tables into hierarchical textual data chunks to enable a wide variety of actionable question answering. First, the user-queries are classified by intention followed by automated retrieval of the most relevant data chunks to generate customized LLM prompts per query. Next, the custom prompts and their responses undergo multi-metric scoring to assess for hallucinations and response confidence. The proposed system is optimized with user-query intention classification, advanced prompting, data scaling capabilities and it achieves over 90% confidence scores for a variety of user-queries responses ranging from {What, Where, Why, How, predict, trend, anomalies, exceptions} that are crucial for financial decision making applications. The proposed data to answers framework can be extended to other analytical domains such as sales and payroll to ensure optimal hallucination control guardrails.
NUMSnet: Nested-U Multi-class Segmentation network for 3D Medical Image Stacks
Apr 05, 2023Semantic segmentation for medical 3D image stacks enables accurate volumetric reconstructions, computer-aided diagnostics and follow up treatment planning. In this work, we present a novel variant of the Unet model called the NUMSnet that transmits pixel neighborhood features across scans through nested layers to achieve accurate multi-class semantic segmentations with minimal training data. We analyze the semantic segmentation performance of the NUMSnet model in comparison with several Unet model variants to segment 3-7 regions of interest using only 10% of images for training per Lung-CT and Heart-CT volumetric image stacks. The proposed NUMSnet model achieves up to 20% improvement in segmentation recall with 4-9% improvement in Dice scores for Lung-CT stacks and 2.5-10% improvement in Dice scores for Heart-CT stacks when compared to the Unet++ model. The NUMSnet model needs to be trained by ordered images around the central scan of each volumetric stack. Propagation of image feature information from the 6 nested layers of the Unet++ model are found to have better computation and segmentation performances than propagation of all up-sampling layers in a Unet++ model. The NUMSnet model achieves comparable segmentation performances to existing works, while being trained on as low as 5\% of the training images. Also, transfer learning allows faster convergence of the NUMSnet model for multi-class semantic segmentation from pathology in Lung-CT images to cardiac segmentations in Heart-CT stacks. Thus, the proposed model can standardize multi-class semantic segmentation on a variety of volumetric image stacks with minimal training dataset. This can significantly reduce the cost, time and inter-observer variabilities associated with computer-aided detections and treatment.
Semi-supervised and Deep learning Frameworks for Video Classification and Key-frame Identification
Mar 25, 2022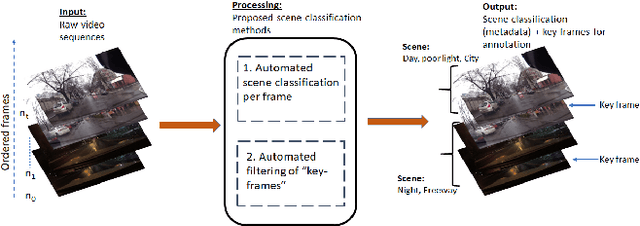

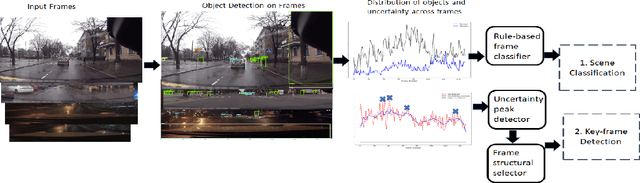
Automating video-based data and machine learning pipelines poses several challenges including metadata generation for efficient storage and retrieval and isolation of key-frames for scene understanding tasks. In this work, we present two semi-supervised approaches that automate this process of manual frame sifting in video streams by automatically classifying scenes for content and filtering frames for fine-tuning scene understanding tasks. The first rule-based method starts from a pre-trained object detector and it assigns scene type, uncertainty and lighting categories to each frame based on probability distributions of foreground objects. Next, frames with the highest uncertainty and structural dissimilarity are isolated as key-frames. The second method relies on the simCLR model for frame encoding followed by label-spreading from 20% of frame samples to label the remaining frames for scene and lighting categories. Also, clustering the video frames in the encoded feature space further isolates key-frames at cluster boundaries. The proposed methods achieve 64-93% accuracy for automated scene categorization for outdoor image videos from public domain datasets of JAAD and KITTI. Also, less than 10% of all input frames can be filtered as key-frames that can then be sent for annotation and fine tuning of machine vision algorithms. Thus, the proposed framework can be scaled to additional video data streams for automated training of perception-driven systems with minimal training images.
QU-net++: Image Quality Detection Framework for Segmentation of 3D Medical Image Stacks
Oct 27, 2021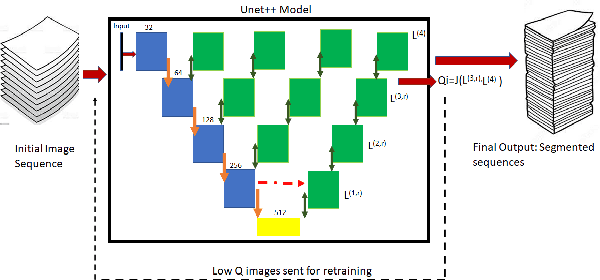
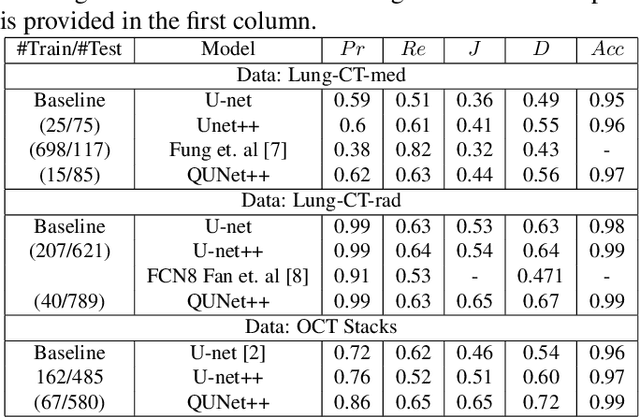
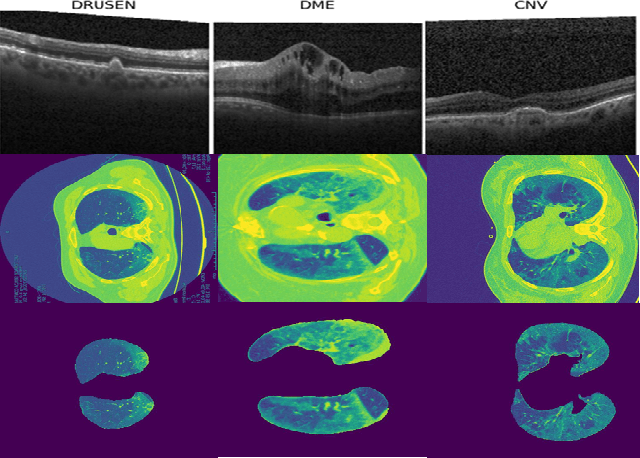
Automated segmentation of pathological regions of interest has been shown to aid prognosis and follow up treatment. However, accurate pathological segmentations require high quality of annotated data that can be both cost and time intensive to generate. In this work, we propose an automated two-step method that evaluates the quality of medical images from 3D image stacks using a U-net++ model, such that images that can aid further training of the U-net++ model can be detected based on the disagreement in segmentations produced from the final two layers. Images thus detected can then be used to further fine tune the U-net++ model for semantic segmentation. The proposed QU-net++ model isolates around 10\% of images per 3D stack and can scale across imaging modalities to segment cysts in OCT images and ground glass opacity in Lung CT images with Dice cores in the range 0.56-0.72. Thus, the proposed method can be applied for multi-modal binary segmentation of pathology.
Video-Data Pipelines for Machine Learning Applications
Oct 15, 2021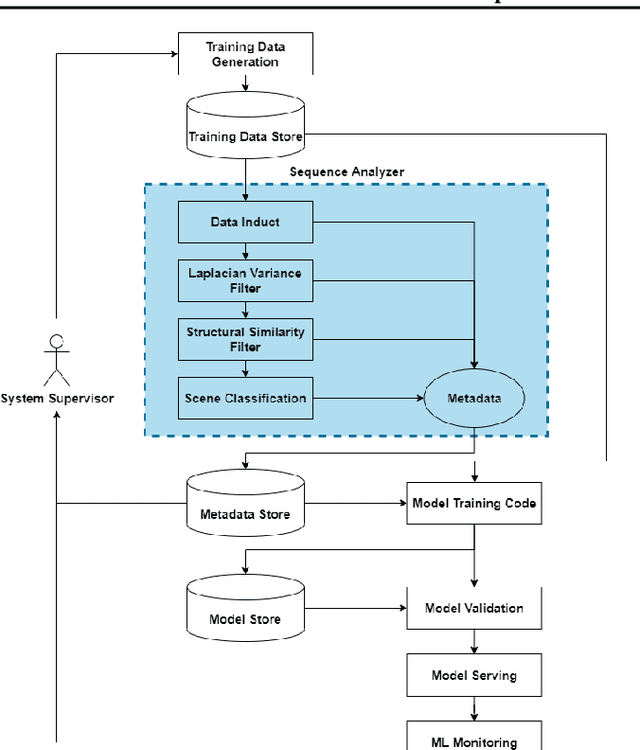
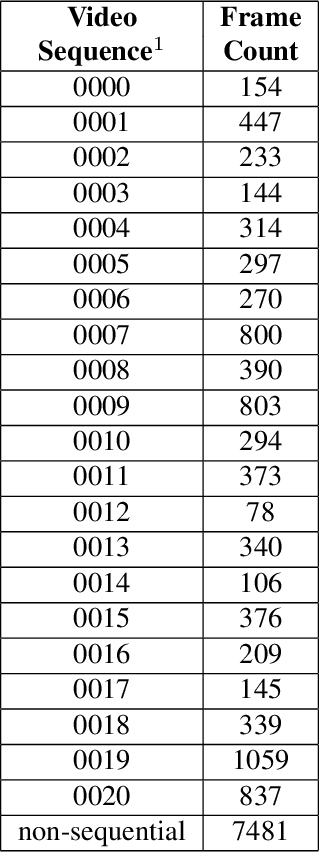

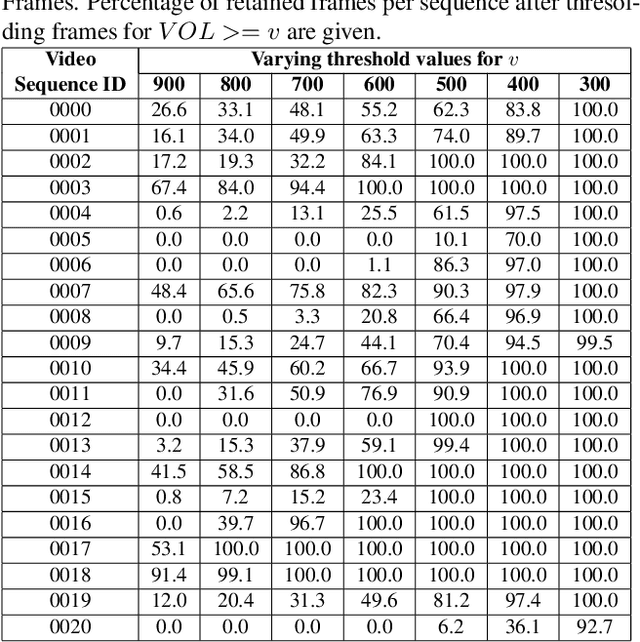
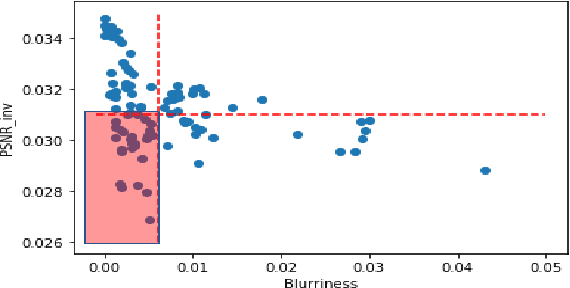
Data pipelines are an essential component for end-to-end solutions that take machine learning algorithms to production. Engineering data pipelines for video-sequences poses several challenges including isolation of key-frames from video sequences that are high quality and represent significant variations in the scene. Manual isolation of such quality key-frames can take hours of sifting through hours worth of video data. In this work, we present a data pipeline framework that can automate this process of manual frame sifting in video sequences by controlling the fraction of frames that can be removed based on image quality and content type. Additionally, the frames that are retained can be automatically tagged per sequence, thereby simplifying the process of automated data retrieval for future ML model deployments. We analyze the performance of the proposed video-data pipeline for versioned deployment and monitoring for object detection algorithms that are trained on outdoor autonomous driving video sequences. The proposed video-data pipeline can retain anywhere between 0.1-20% of the all input frames that are representative of high image quality and high variations in content. This frame selection, automated scene tagging followed by model verification can be completed in under 30 seconds for 22 video-sequences under analysis in this work. Thus, the proposed framework can be scaled to additional video-sequence data sets for automating ML versioned deployments.
SISE-PC: Semi-supervised Image Subsampling for Explainable Pathology
Mar 10, 2021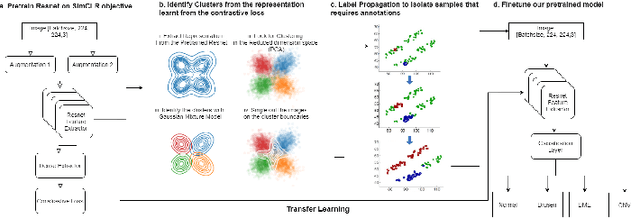
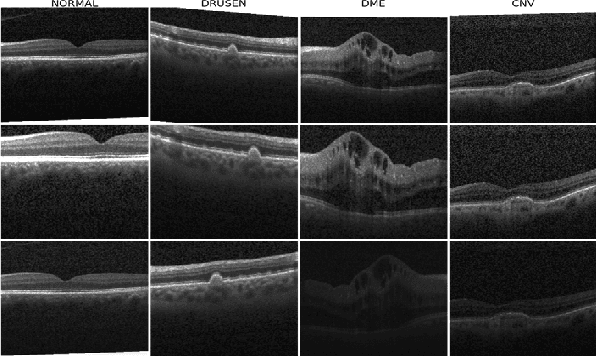
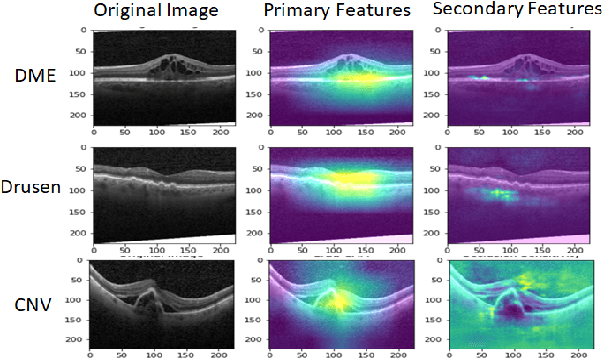
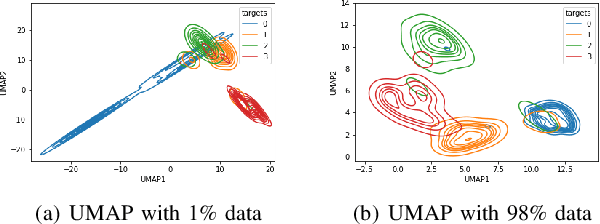
Although automated pathology classification using deep learning (DL) has proved to be predictively efficient, DL methods are found to be data and compute cost intensive. In this work, we aim to reduce DL training costs by pre-training a Resnet feature extractor using SimCLR contrastive loss for latent encoding of OCT images. We propose a novel active learning framework that identifies a minimal sub-sampled dataset containing the most uncertain OCT image samples using label propagation on the SimCLR latent encodings. The pre-trained Resnet model is then fine-tuned with the labelled minimal sub-sampled data and the underlying pathological sites are visually explained. Our framework identifies upto 2% of OCT images to be most uncertain that need prioritized specialist attention and that can fine-tune a Resnet model to achieve upto 97% classification accuracy. The proposed method can be extended to other medical images to minimize prediction costs.