 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Data Pipelines for Machine Learning Applications
Oct 15, 2021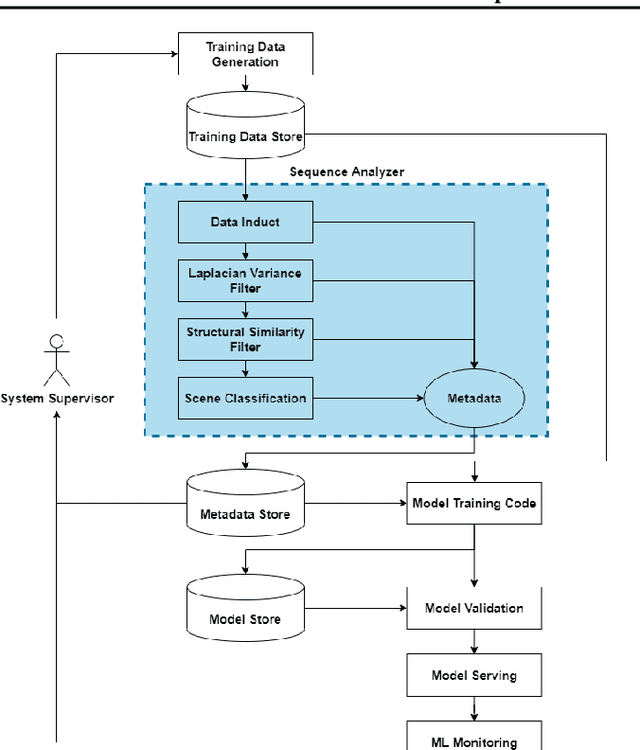
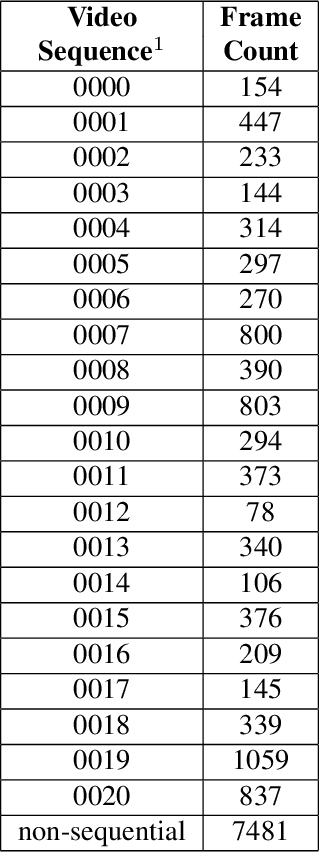

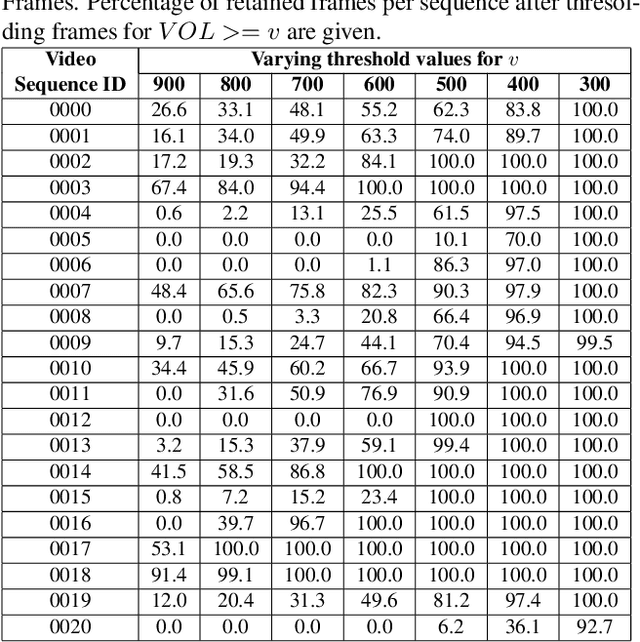
Data pipelines are an essential component for end-to-end solutions that take machine learning algorithms to production. Engineering data pipelines for video-sequences poses several challenges including isolation of key-frames from video sequences that are high quality and represent significant variations in the scene. Manual isolation of such quality key-frames can take hours of sifting through hours worth of video data. In this work, we present a data pipeline framework that can automate this process of manual frame sifting in video sequences by controlling the fraction of frames that can be removed based on image quality and content type. Additionally, the frames that are retained can be automatically tagged per sequence, thereby simplifying the process of automated data retrieval for future ML model deployments. We analyze the performance of the proposed video-data pipeline for versioned deployment and monitoring for object detection algorithms that are trained on outdoor autonomous driving video sequences. The proposed video-data pipeline can retain anywhere between 0.1-20% of the all input frames that are representative of high image quality and high variations in content. This frame selection, automated scene tagging followed by model verification can be completed in under 30 seconds for 22 video-sequences under analysis in this work. Thus, the proposed framework can be scaled to additional video-sequence data sets for automating ML versioned deployments.