 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
Spectral-Refiner: Fine-Tuning of Accurate Spatiotemporal Neural Operator for Turbulent Flows
May 27, 2024Recent advancements in operator-type neural networks have shown promising results in approximating the solutions of spatiotemporal Partial Differential Equations (PDEs). However, these neural networks often entail considerable training expenses, and may not always achieve the desired accuracy required in many scientific and engineering disciplines. In this paper, we propose a new Spatiotemporal Fourier Neural Operator (SFNO) that learns maps between Bochner spaces, and a new learning framework to address these issues. This new paradigm leverages wisdom from traditional numerical PDE theory and techniques to refine the pipeline of commonly adopted end-to-end neural operator training and evaluations. Specifically, in the learning problems for the turbulent flow modeling by the Navier-Stokes Equations (NSE), the proposed architecture initiates the training with a few epochs for SFNO, concluding with the freezing of most model parameters. Then, the last linear spectral convolution layer is fine-tuned without the frequency truncation. The optimization uses a negative Sobolev norm for the first time as the loss in operator learning, defined through a reliable functional-type \emph{a posteriori} error estimator whose evaluation is almost exact thanks to the Parseval identity. This design allows the neural operators to effectively tackle low-frequency errors while the relief of the de-aliasing filter addresses high-frequency errors. Numerical experiments on commonly used benchmarks for the 2D NSE demonstrate significant improvements in both computational efficiency and accuracy, compared to end-to-end evaluation and traditional numerical PDE solvers.
Transformer Meets Boundary Value Inverse Problems
Sep 29, 2022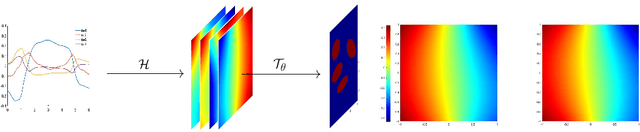


A Transformer-based deep direct sampling method is proposed for solving a class of boundary value inverse problem. A real-time reconstruction is achieved by evaluating the learned inverse operator between carefully designed data and the reconstructed images. An effort is made to give a case study for a fundamental and critical question: whether and how one can benefit from the theoretical structure of a mathematical problem to develop task-oriented and structure-conforming deep neural network? Inspired by direct sampling methods for inverse problems, the 1D boundary data are preprocessed by a partial differential equation-based feature map to yield 2D harmonic extensions in different frequency input channels. Then, by introducing learnable non-local kernel, the approximation of direct sampling is recast to a modified attention mechanism. The proposed method is then applied to electrical impedance tomography, a well-known severely ill-posed nonlinear inverse problem. The new method achieves superior accuracy over its predecessors and contemporary operator learners, as well as shows robustness with respect to noise. This research shall strengthen the insights that the attention mechanism, despite being invented for natural language processing tasks, offers great flexibility to be modified in conformity with the a priori mathematical knowledge, which ultimately leads to the design of more physics-compatible neural architectures.
How to Understand Masked Autoencoders
Feb 09, 2022"Masked Autoencoders (MAE) Are Scalable Vision Learners" revolutionizes the self-supervised learning method in that it not only achieves the state-of-the-art for image pre-training, but is also a milestone that bridges the gap between visual and linguistic masked autoencoding (BERT-style) pre-trainings. However, to our knowledge, to date there are no theoretical perspectives to explain the powerful expressivity of MAE. In this paper, we, for the first time, propose a unified theoretical framework that provides a mathematical understanding for MAE. Specifically, we explain the patch-based attention approaches of MAE using an integral kernel under a non-overlapping domain decomposition setting. To help the research community to further comprehend the main reasons of the great success of MAE, based on our framework, we pose five questions and answer them with mathematical rigor using insights from operator theory.
Choose a Transformer: Fourier or Galerkin
Jun 03, 2021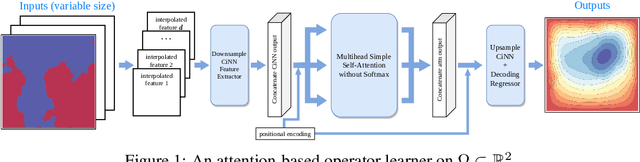

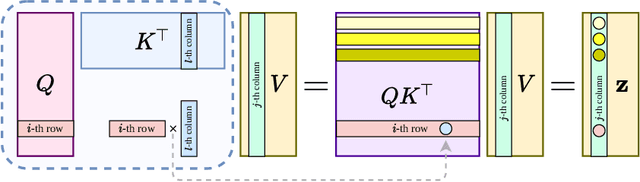

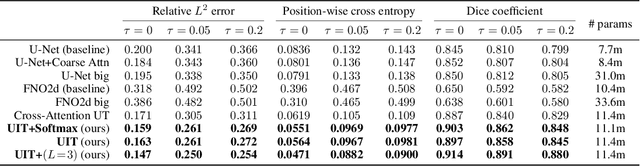
In this paper, we apply the self-attention from the state-of-the-art Transformer in Attention Is All You Need the first time to a data-driven operator learning problem related to partial differential equations. We put together an effort to explain the heuristics of, and improve the efficacy of the self-attention by demonstrating that the softmax normalization in the scaled dot-product attention is sufficient but not necessary, and have proved the approximation capacity of a linear variant as a Petrov-Galerkin projection. A new layer normalization scheme is proposed to allow a scaling to propagate through attention layers, which helps the model achieve remarkable accuracy in operator learning tasks with unnormalized data. Finally, we present three operator learning experiments, including the viscid Burgers' equation, an interface Darcy flow, and an inverse interface coefficient identification problem. All experiments validate the improvements of the newly proposed simple attention-based operator learner over their softmax-normalized counterparts.