 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Exceed: Stereo Inverse Reinforcement Learning with Concurrent Policy Optimization
Paper and Code
Sep 22, 2020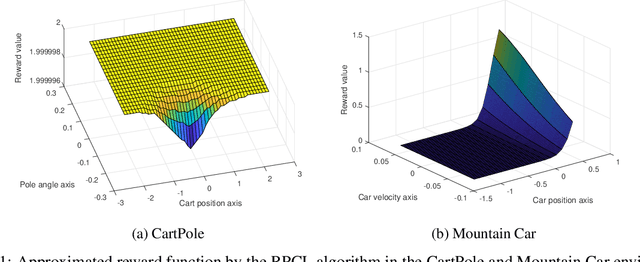
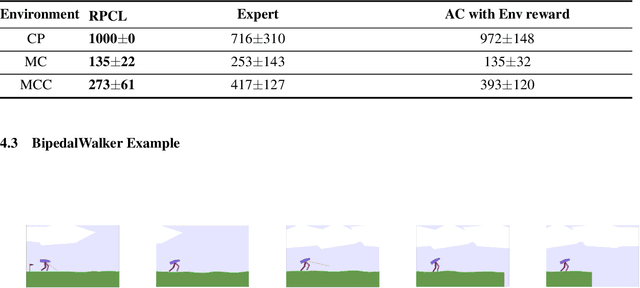
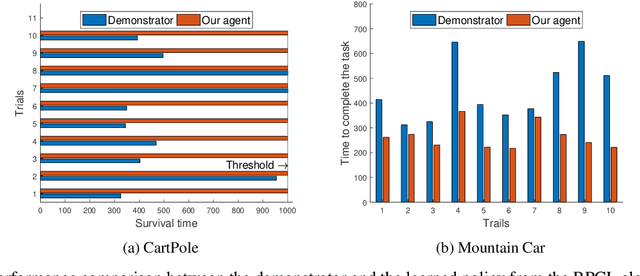
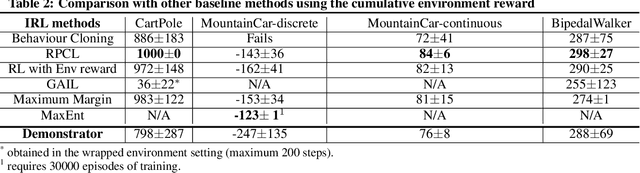
In this paper, we study the problem of obtaining a control policy that can mimic and then outperform expert demonstrations in Markov decision processes where the reward function is unknown to the learning agent. One main relevant approach is the inverse reinforcement learning (IRL), which mainly focuses on inferring a reward function from expert demonstrations. The obtained control policy by IRL and the associated algorithms, however, can hardly outperform expert demonstrations. To overcome this limitation, we propose a novel method that enables the learning agent to outperform the demonstrator via a new concurrent reward and action policy learning approach. In particular, we first propose a new stereo utility definition that aims to address the bias in the interpretation of expert demonstrations. We then propose a loss function for the learning agent to learn reward and action policies concurrently such that the learning agent can outperform expert demonstrations. The performance of the proposed method is first demonstrated in OpenAI environments. Further efforts are conducted to experimentally validate the proposed method via an indoor drone flight scenario.