 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCBench: A Controllable Benchmark for Symbolic and Abstract Challenges in Video Cognition
Paper and Code
Nov 14, 2024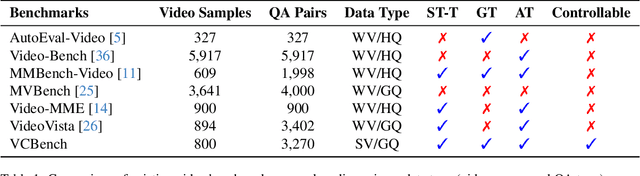
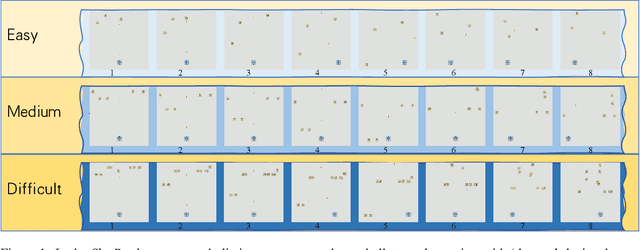
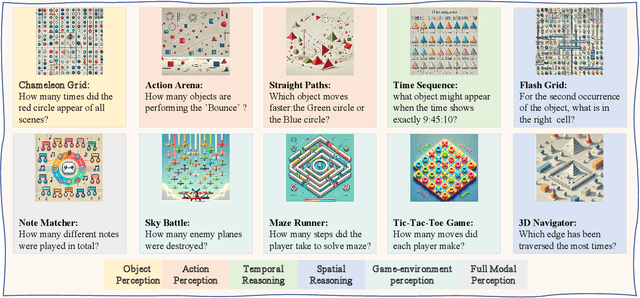
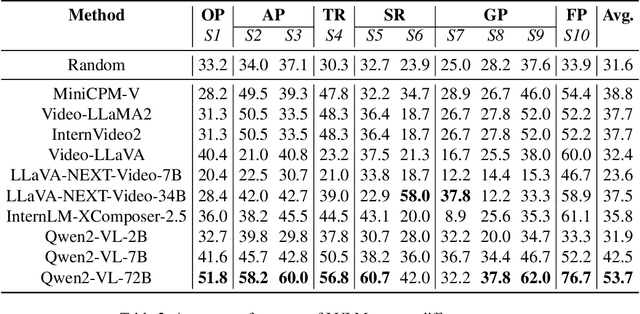
Recent advancements in Large Video-Language Models (LVLMs) have driven the development of benchmarks designed to assess cognitive abilities in video-based tasks. However, most existing benchmarks heavily rely on web-collected videos paired with human annotations or model-generated questions, which limit control over the video content and fall short in evaluating advanced cognitive abilities involving symbolic elements and abstract concepts. To address these limitations, we introduce VCBench, a controllable benchmark to assess LVLMs' cognitive abilities, involving symbolic and abstract concepts at varying difficulty levels. By generating video data with the Python-based engine, VCBench allows for precise control over the video content, creating dynamic, task-oriented videos that feature complex scenes and abstract concepts. Each task pairs with tailored question templates that target specific cognitive challenges, providing a rigorous evaluation test. Our evaluation reveals that even state-of-the-art (SOTA) models, such as Qwen2-VL-72B, struggle with simple video cognition tasks involving abstract concepts, with performance sharply dropping by 19% as video complexity rises. These findings reveal the current limitations of LVLMs in advanced cognitive tasks and highlight the critical role of VCBench in driving research toward more robust LVLMs for complex video cognition challenges.