 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Vector Erasure: Unified Training-Free Concept Erasure for Flow Matching Models
Feb 01, 2026Text-to-image diffusion models have demonstrated remarkable capabilities in generating high-quality images, yet their tendency to reproduce undesirable concepts, such as NSFW content, copyrighted styles, or specific objects, poses growing concerns for safe and controllable deployment. While existing concept erasure approaches primarily focus on DDPM-based diffusion models and rely on costly fine-tuning, the recent emergence of flow matching models introduces a fundamentally different generative paradigm for which prior methods are not directly applicable. In this paper, we propose Differential Vector Erasure (DVE), a training-free concept erasure method specifically designed for flow matching models. Our key insight is that semantic concepts are implicitly encoded in the directional structure of the velocity field governing the generative flow. Leveraging this observation, we construct a differential vector field that characterizes the directional discrepancy between a target concept and a carefully chosen anchor concept. During inference, DVE selectively removes concept-specific components by projecting the velocity field onto the differential direction, enabling precise concept suppression without affecting irrelevant semantics. Extensive experiments on FLUX demonstrate that DVE consistently outperforms existing baselines on a wide range of concept erasure tasks, including NSFW suppression, artistic style removal, and object erasure, while preserving image quality and diversity.
Closing the Safety Gap: Surgical Concept Erasure in Visual Autoregressive Models
Sep 26, 2025The rapid progress of visual autoregressive (VAR) models has brought new opportunities for text-to-image generation, but also heightened safety concerns. Existing concept erasure techniques, primarily designed for diffusion models, fail to generalize to VARs due to their next-scale token prediction paradigm. In this paper, we first propose a novel VAR Erasure framework VARE that enables stable concept erasure in VAR models by leveraging auxiliary visual tokens to reduce fine-tuning intensity. Building upon this, we introduce S-VARE, a novel and effective concept erasure method designed for VAR, which incorporates a filtered cross entropy loss to precisely identify and minimally adjust unsafe visual tokens, along with a preservation loss to maintain semantic fidelity, addressing the issues such as language drift and reduced diversity introduce by na\"ive fine-tuning. Extensive experiments demonstrate that our approach achieves surgical concept erasure while preserving generation quality, thereby closing the safety gap in autoregressive text-to-image generation by earlier methods.
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
May 06, 2025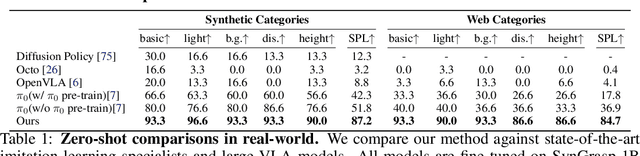



Embodied foundation models are gaining increasing attention for their zero-shot generalization, scalability, and adaptability to new tasks through few-shot post-training. However, existing models rely heavily on real-world data, which is costly and labor-intensive to collect. Synthetic data offers a cost-effective alternative, yet its potential remains largely underexplored. To bridge this gap, we explore the feasibility of training Vision-Language-Action models entirely with large-scale synthetic action data. We curate SynGrasp-1B, a billion-frame robotic grasping dataset generated in simulation with photorealistic rendering and extensive domain randomization. Building on this, we present GraspVLA, a VLA model pretrained on large-scale synthetic action data as a foundational model for grasping tasks. GraspVLA integrates autoregressive perception tasks and flow-matching-based action generation into a unified Chain-of-Thought process, enabling joint training on synthetic action data and Internet semantics data. This design helps mitigate sim-to-real gaps and facilitates the transfer of learned actions to a broader range of Internet-covered objects, achieving open-vocabulary generalization in grasping. Extensive evaluations across real-world and simulation benchmarks demonstrate GraspVLA's advanced zero-shot generalizability and few-shot adaptability to specific human preferences. We will release SynGrasp-1B dataset and pre-trained weights to benefit the community.
Optimization of Module Transferability in Single Image Super-Resolution: Universality Assessment and Cycle Residual Blocks
May 06, 2025Deep learning has substantially advanced the Single Image Super-Resolution (SISR). However, existing researches have predominantly focused on raw performance gains, with little attention paid to quantifying the transferability of architectural components. In this paper, we introduce the concept of "Universality" and its associated definitions which extend the traditional notion of "Generalization" to encompass the modules' ease of transferability, thus revealing the relationships between module universality and model generalizability. Then we propose the Universality Assessment Equation (UAE), a metric for quantifying how readily a given module could be transplanted across models. Guided by the UAE results of standard residual blocks and other plug-and-play modules, we further design two optimized modules, Cycle Residual Block (CRB) and Depth-Wise Cycle Residual Block (DCRB). Through comprehensive experiments on natural-scene benchmarks, remote-sensing datasets, extreme-industrial imagery and on-device deployments, we demonstrate that networks embedded with the proposed plug-and-play modules outperform several state-of-the-arts, reaching a PSNR enhancement of up to 0.83dB or enabling a 71.3% reduction in parameters with negligible loss in reconstruction fidelity.
EgoViT: Pyramid Video Transformer for Egocentric Action Recognition
Mar 15, 2023



Capturing interaction of hands with objects is important to autonomously detect human actions from egocentric videos. In this work, we present a pyramid video transformer with a dynamic class token generator for egocentric action recognition. Different from previous video transformers, which use the same static embedding as the class token for diverse inputs, we propose a dynamic class token generator that produces a class token for each input video by analyzing the hand-object interaction and the related motion information. The dynamic class token can diffuse such information to the entire model by communicating with other informative tokens in the subsequent transformer layers. With the dynamic class token, dissimilarity between videos can be more prominent, which helps the model distinguish various inputs. In addition, traditional video transformers explore temporal features globally, which requires large amounts of computation. However, egocentric videos often have a large amount of background scene transition, which causes discontinuities across distant frames. In this case, blindly reducing the temporal sampling rate will risk losing crucial information. Hence, we also propose a pyramid architecture to hierarchically process the video from short-term high rate to long-term low rate. With the proposed architecture, we significantly reduce the computational cost as well as the memory requirement without sacrificing from the model performance. We perform comparisons with different baseline video transformers on the EPIC-KITCHENS-100 and EGTEA Gaze+ datasets. Both quantitative and qualitative results show that the proposed model can efficiently improve the performance for egocentric action recognition.
CLIP-FLow: Contrastive Learning by semi-supervised Iterative Pseudo labeling for Optical Flow Estimation
Nov 01, 2022
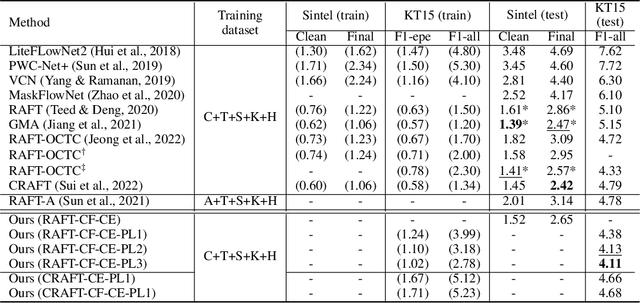
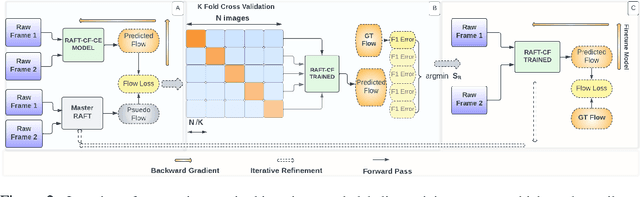
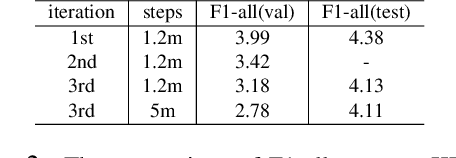
Synthetic datasets are often used to pretrain end-to-end optical flow networks, due to the lack of a large amount of labeled, real-scene data. But major drops in accuracy occur when moving from synthetic to real scenes. How do we better transfer the knowledge learned from synthetic to real domains? To this end, we propose CLIP-FLow, a semi-supervised iterative pseudo-labeling framework to transfer the pretraining knowledge to the target real domain. We leverage large-scale, unlabeled real data to facilitate transfer learning with the supervision of iteratively updated pseudo-ground truth labels, bridging the domain gap between the synthetic and the real. In addition, we propose a contrastive flow loss on reference features and the warped features by pseudo ground truth flows, to further boost the accurate matching and dampen the mismatching due to motion, occlusion, or noisy pseudo labels. We adopt RAFT as the backbone and obtain an F1-all error of 4.11%, i.e. a 19% error reduction from RAFT (5.10%) and ranking 2$^{nd}$ place at submission on the KITTI 2015 benchmark. Our framework can also be extended to other models, e.g. CRAFT, reducing the F1-all error from 4.79% to 4.66% on KITTI 2015 benchmark.
MKANet: A Lightweight Network with Sobel Boundary Loss for Efficient Land-cover Classification of Satellite Remote Sensing Imagery
Jul 28, 2022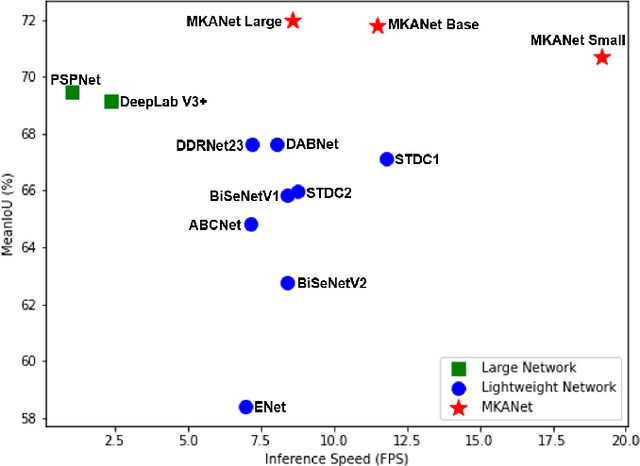
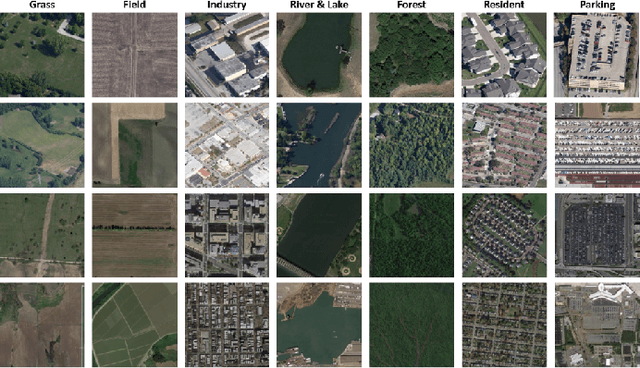
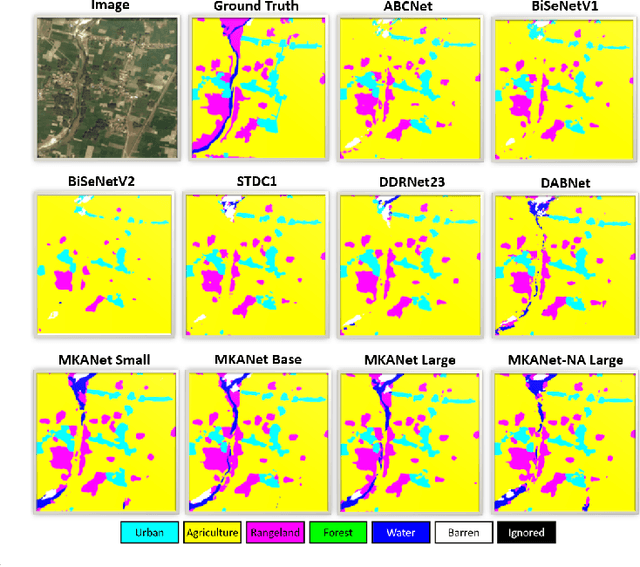
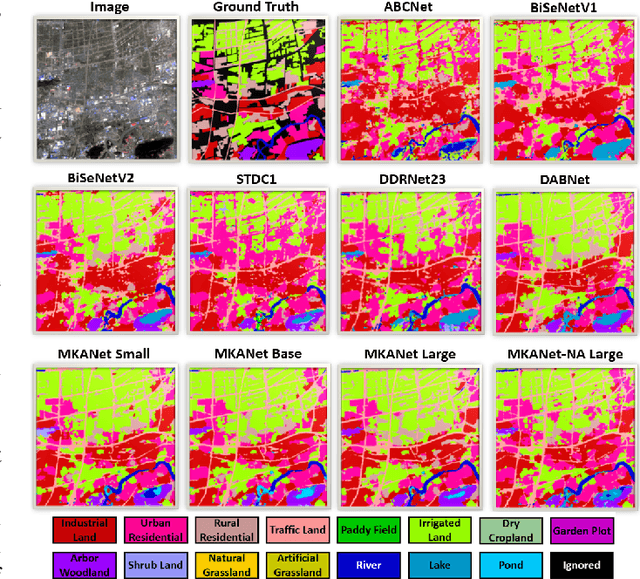
Land cover classification is a multi-class segmentation task to classify each pixel into a certain natural or man-made category of the earth surface, such as water, soil, natural vegetation, crops, and human infrastructure. Limited by hardware computational resources and memory capacity, most existing studies preprocessed original remote sensing images by down sampling or cropping them into small patches less than 512*512 pixels before sending them to a deep neural network. However, down sampling images incurs spatial detail loss, renders small segments hard to discriminate, and reverses the spatial resolution progress obtained by decades of years of efforts. Cropping images into small patches causes a loss of long-range context information, and restoring the predicted results to their original size brings extra latency. In response to the above weaknesses, we present an efficient lightweight semantic segmentation network termed MKANet. Aimed at the characteristics of top view high-resolution remote sensing imagery, MKANet utilizes sharing kernels to simultaneously and equally handle ground segments of inconsistent scales, and also employs parallel and shallow architecture to boost inference speed and friendly support image patches more than 10X larger. To enhance boundary and small segments discrimination, we also propose a method that captures category impurity areas, exploits boundary information and exerts an extra penalty on boundaries and small segment misjudgment. Both visual interpretations and quantitative metrics of extensive experiments demonstrate that MKANet acquires state-of-the-art accuracy on two land-cover classification datasets and infers 2X faster than other competitive lightweight networks. All these merits highlight the potential of MKANet in practical applications.
Label Mask for Multi-Label Text Classification
Jun 18, 2021
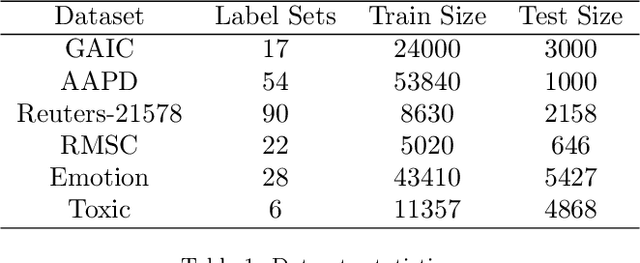
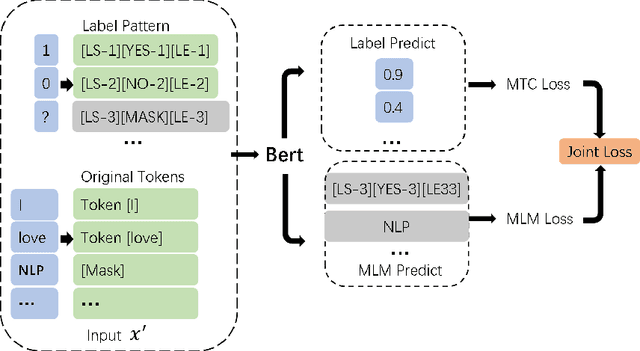
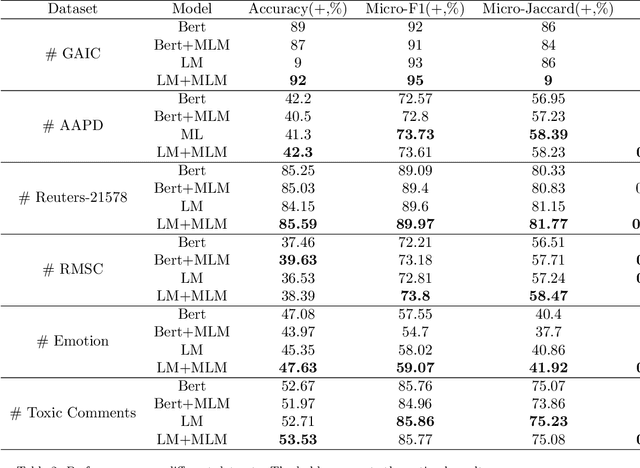
One of the key problems in multi-label text classification is how to take advantage of the correlation among labels. However, it is very challenging to directly model the correlations among labels in a complex and unknown label space. In this paper, we propose a Label Mask multi-label text classification model (LM-MTC), which is inspired by the idea of cloze questions of language model. LM-MTC is able to capture implicit relationships among labels through the powerful ability of pre-train language models. On the basis, we assign a different token to each potential label, and randomly mask the token with a certain probability to build a label based Masked Language Model (MLM). We train the MTC and MLM together, further improving the generalization ability of the model. A large number of experiments on multiple datasets demonstrate the effectiveness of our method.
Holographic Maxwellian near-eye display with adjustable and continuous eye-box replication
Jun 11, 2021



The Maxwellian display presents always-focused images to the viewer, alleviating the vergence-accommodation conflict (VAC) in near-eye displays (NEDs). However, the limited eyebox of the typical Maxwellian display prevents it from wider applications. We propose a holographic Maxwellian near-eye display with adjustable and continuous eye-box replication. Holographic display provides a way to match the human pupil size with the interval of the replicated eyeboxes, making it possible to eliminate or alleviate double image or blind area problem, which exists long in eyebox expansion for Maxwellian display. Besides, seamless image conversion between viewing points has been achieved through hologram pre-processing. Optical experiment confirms that the interval between replicated eyeboxes is dynamically adjustable, ranging from 2mm to 6mm. The proposed display can present always-focused images and seamless conversion among viewpoints with 5.32$^\circ$ horizontal field of view, and 9mmH * 3mmV eyebox.
FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
May 23, 2019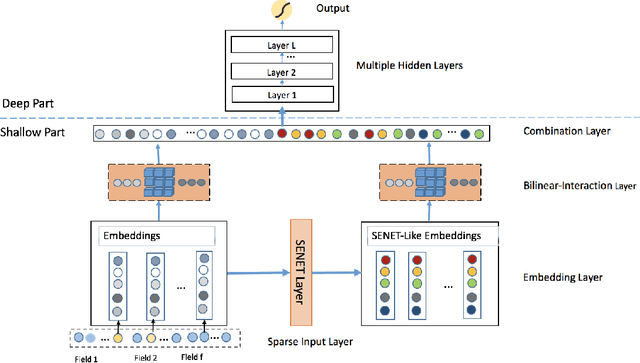

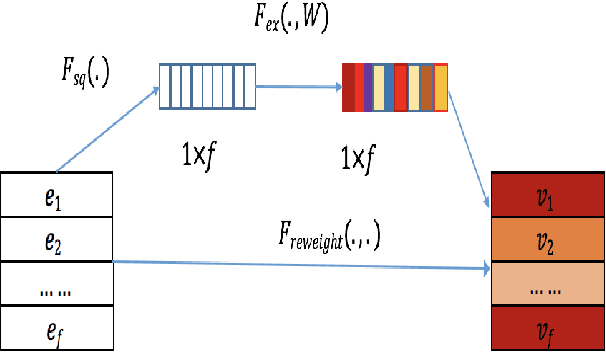

Advertising and feed ranking are essential to many Internet companies such as Facebook and Sina Weibo. Among many real-world advertising and feed ranking systems, click through rate (CTR) prediction plays a central role. There are many proposed models in this field such as logistic regression, tree based models, factorization machine based models and deep learning based CTR models. However, many current works calculate the feature interactions in a simple way such as Hadamard product and inner product and they care less about the importance of features. In this paper, a new model named FiBiNET as an abbreviation for Feature Importance and Bilinear feature Interaction NETwork is proposed to dynamically learn the feature importance and fine-grained feature interactions. On the one hand, the FiBiNET can dynamically learn the importance of features via the Squeeze-Excitation network (SENET) mechanism; on the other hand, it is able to effectively learn the feature interactions via bilinear function. We conduct extensive experiments on two real-world datasets and show that our shallow model outperforms other shallow models such as factorization machine(FM) and field-aware factorization machine(FFM). In order to improve performance further, we combine a classical deep neural network(DNN) component with the shallow model to be a deep model. The deep FiBiNET consistently outperforms the other state-of-the-art deep models such as DeepFM and extreme deep factorization machine(XdeepFM).