 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosis-oriented Medical Image Compression with Efficient Transfer Learning
Oct 20, 2023Remote medical diagnosis has emerged as a critical and indispensable technique in practical medical systems, where medical data are required to be efficiently compressed and transmitted for diagnosis by either professional doctors or intelligent diagnosis devices. In this process, a large amount of redundant content irrelevant to the diagnosis is subjected to high-fidelity coding, leading to unnecessary transmission costs. To mitigate this, we propose diagnosis-oriented medical image compression, a special semantic compression task designed for medical scenarios, targeting to reduce the compression cost without compromising the diagnosis accuracy. However, collecting sufficient medical data to optimize such a compression system is significantly expensive and challenging due to privacy issues and the lack of professional annotation. In this study, we propose DMIC, the first efficient transfer learning-based codec, for diagnosis-oriented medical image compression, which can be effectively optimized with only few-shot annotated medical examples, by reusing the knowledge in the existing reinforcement learning-based task-driven semantic coding framework, i.e., HRLVSC [1]. Concretely, we focus on tuning only the partial parameters of the policy network for bit allocation within HRLVSC, which enables it to adapt to the medical images. In this work, we validate our DMIC with the typical medical task, Coronary Artery Segmentation. Extensive experiments have demonstrated that our DMIC can achieve 47.594%BD-Rate savings compared to the HEVC anchor, by tuning only the A2C module (2.7% parameters) of the policy network with only 1 medical sample.
Hierarchical Reinforcement Learning Based Video Semantic Coding for Segmentation
Aug 24, 2022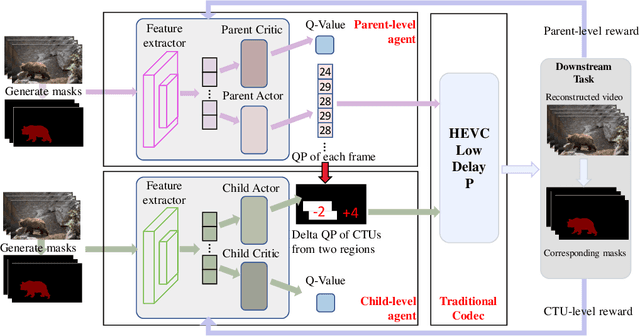
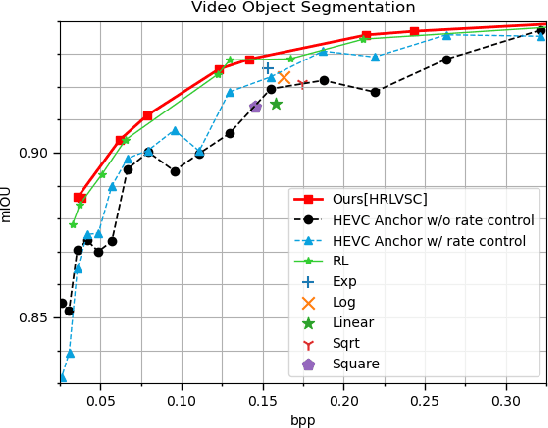
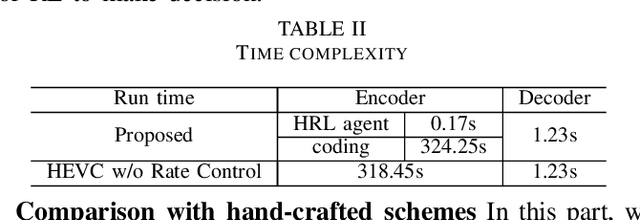
The rapid development of intelligent tasks, e.g., segmentation, detection, classification, etc, has brought an urgent need for semantic compression, which aims to reduce the compression cost while maintaining the original semantic information. However, it is impractical to directly integrate the semantic metric into the traditional codecs since they cannot be optimized in an end-to-end manner. To solve this problem, some pioneering works have applied reinforcement learning to implement image-wise semantic compression. Nevertheless, video semantic compression has not been explored since its complex reference architectures and compression modes. In this paper, we take a step forward to video semantic compression and propose the Hierarchical Reinforcement Learning based task-driven Video Semantic Coding, named as HRLVSC. Specifically, to simplify the complex mode decision of video semantic coding, we divided the action space into frame-level and CTU-level spaces in a hierarchical manner, and then explore the best mode selection for them progressively with the cooperation of frame-level and CTU-level agents. Moreover, since the modes of video semantic coding will exponentially increase with the number of frames in a Group of Pictures (GOP), we carefully investigate the effects of different mode selections for video semantic coding and design a simple but effective mode simplification strategy for it. We have validated our HRLVSC on the video segmentation task with HEVC reference software HM16.19. Extensive experimental results demonstrated that our HRLVSC can achieve over 39% BD-rate saving for video semantic coding under the Low Delay P configuration.
MKANet: A Lightweight Network with Sobel Boundary Loss for Efficient Land-cover Classification of Satellite Remote Sensing Imagery
Jul 28, 2022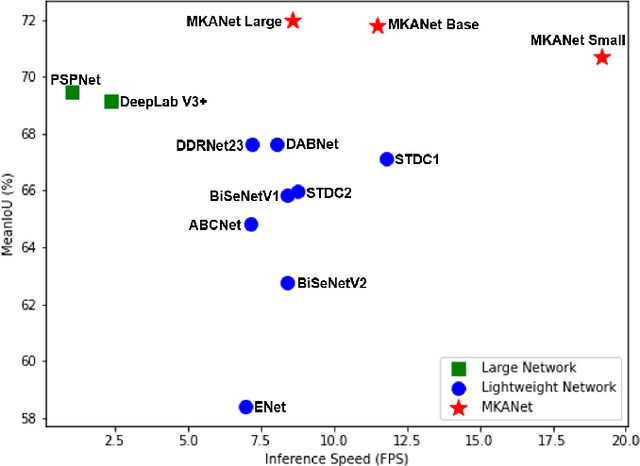
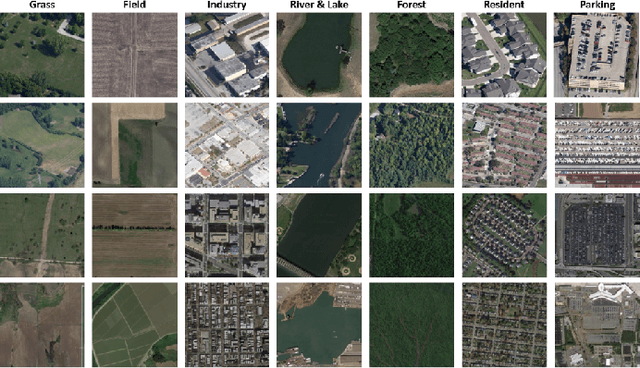
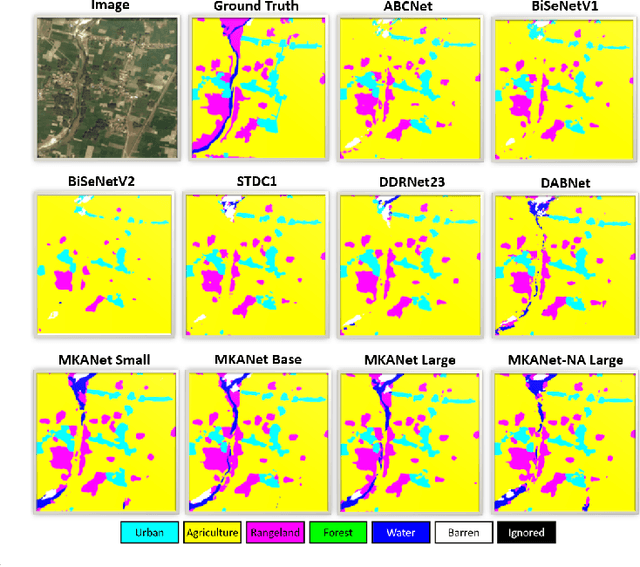
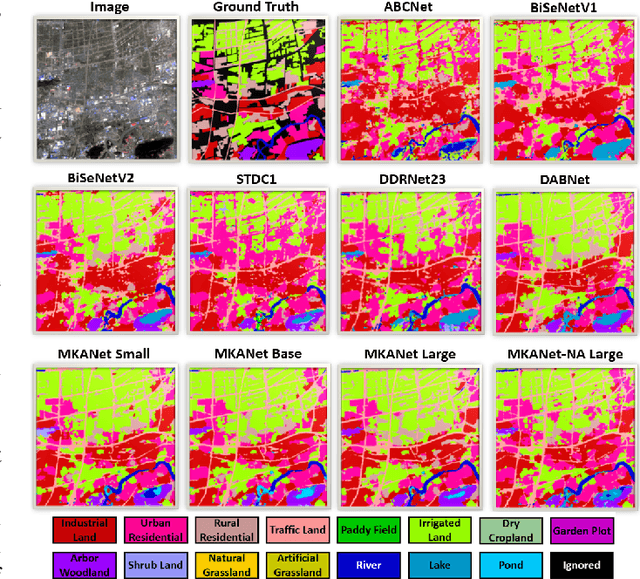
Land cover classification is a multi-class segmentation task to classify each pixel into a certain natural or man-made category of the earth surface, such as water, soil, natural vegetation, crops, and human infrastructure. Limited by hardware computational resources and memory capacity, most existing studies preprocessed original remote sensing images by down sampling or cropping them into small patches less than 512*512 pixels before sending them to a deep neural network. However, down sampling images incurs spatial detail loss, renders small segments hard to discriminate, and reverses the spatial resolution progress obtained by decades of years of efforts. Cropping images into small patches causes a loss of long-range context information, and restoring the predicted results to their original size brings extra latency. In response to the above weaknesses, we present an efficient lightweight semantic segmentation network termed MKANet. Aimed at the characteristics of top view high-resolution remote sensing imagery, MKANet utilizes sharing kernels to simultaneously and equally handle ground segments of inconsistent scales, and also employs parallel and shallow architecture to boost inference speed and friendly support image patches more than 10X larger. To enhance boundary and small segments discrimination, we also propose a method that captures category impurity areas, exploits boundary information and exerts an extra penalty on boundaries and small segment misjudgment. Both visual interpretations and quantitative metrics of extensive experiments demonstrate that MKANet acquires state-of-the-art accuracy on two land-cover classification datasets and infers 2X faster than other competitive lightweight networks. All these merits highlight the potential of MKANet in practical applications.