 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning Based Video Semantic Coding for Segmentation
Aug 24, 2022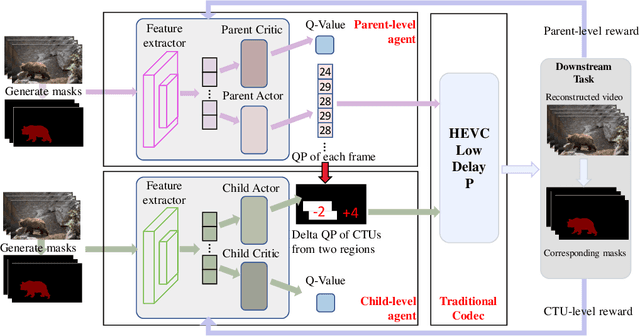
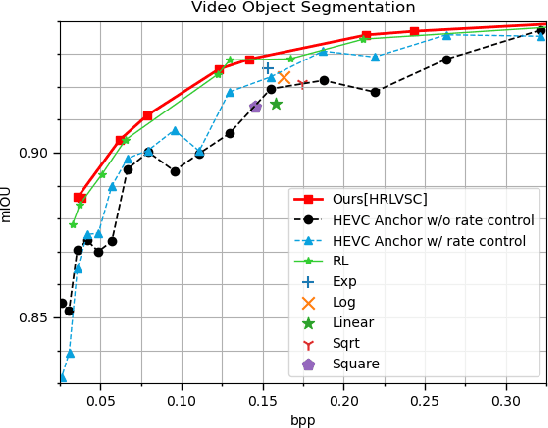
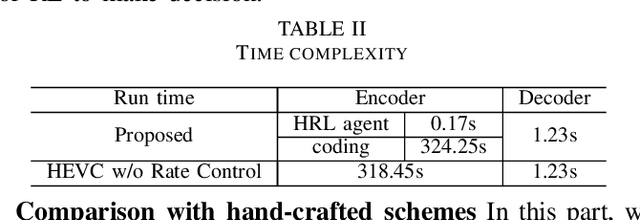
The rapid development of intelligent tasks, e.g., segmentation, detection, classification, etc, has brought an urgent need for semantic compression, which aims to reduce the compression cost while maintaining the original semantic information. However, it is impractical to directly integrate the semantic metric into the traditional codecs since they cannot be optimized in an end-to-end manner. To solve this problem, some pioneering works have applied reinforcement learning to implement image-wise semantic compression. Nevertheless, video semantic compression has not been explored since its complex reference architectures and compression modes. In this paper, we take a step forward to video semantic compression and propose the Hierarchical Reinforcement Learning based task-driven Video Semantic Coding, named as HRLVSC. Specifically, to simplify the complex mode decision of video semantic coding, we divided the action space into frame-level and CTU-level spaces in a hierarchical manner, and then explore the best mode selection for them progressively with the cooperation of frame-level and CTU-level agents. Moreover, since the modes of video semantic coding will exponentially increase with the number of frames in a Group of Pictures (GOP), we carefully investigate the effects of different mode selections for video semantic coding and design a simple but effective mode simplification strategy for it. We have validated our HRLVSC on the video segmentation task with HEVC reference software HM16.19. Extensive experimental results demonstrated that our HRLVSC can achieve over 39% BD-rate saving for video semantic coding under the Low Delay P configuration.
Deep Frequency Filtering for Domain Generalization
Mar 23, 2022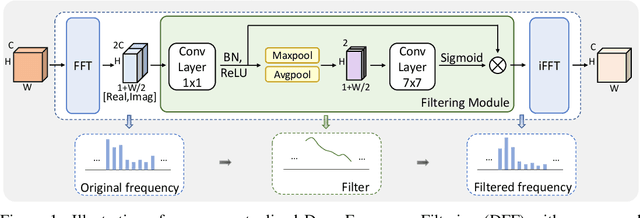
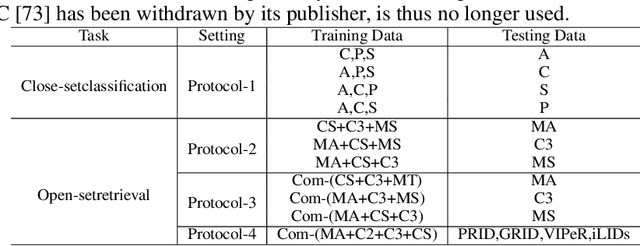
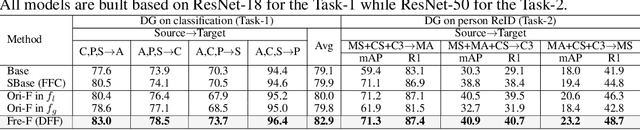

Improving the generalization capability of Deep Neural Networks (DNNs) is critical for their practical uses, which has been a longstanding challenge. Some theoretical studies have revealed that DNNs have preferences to different frequency components in the learning process and indicated that this may affect the robustness of learned features. In this paper, we propose Deep Frequency Filtering (DFF) for learning domain-generalizable features, which is the first endeavour to explicitly modulate frequency components of different transfer difficulties across domains during training. To achieve this, we perform Fast Fourier Transform (FFT) on feature maps at different layers, then adopt a light-weight module to learn the attention masks from frequency representations after FFT to enhance transferable frequency components while suppressing the components not conductive to generalization. Further, we empirically compare different types of attention for implementing our conceptualized DFF. Extensive experiments demonstrate the effectiveness of the proposed DFF and show that applying DFF on a plain baseline outperforms the state-of-the-art methods on different domain generalization tasks, including close-set classification and open-set retrieval.
SelectAugment: Hierarchical Deterministic Sample Selection for Data Augmentation
Dec 06, 2021
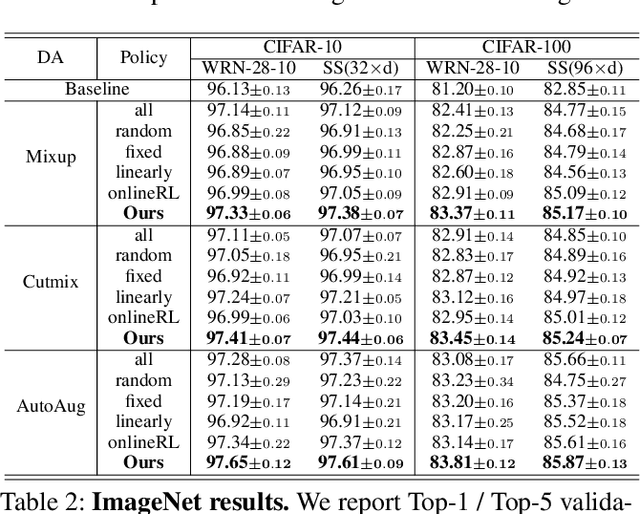
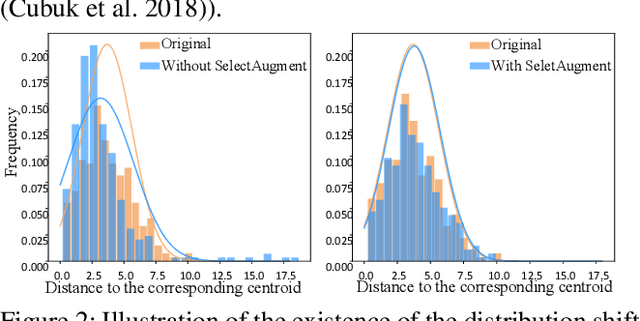
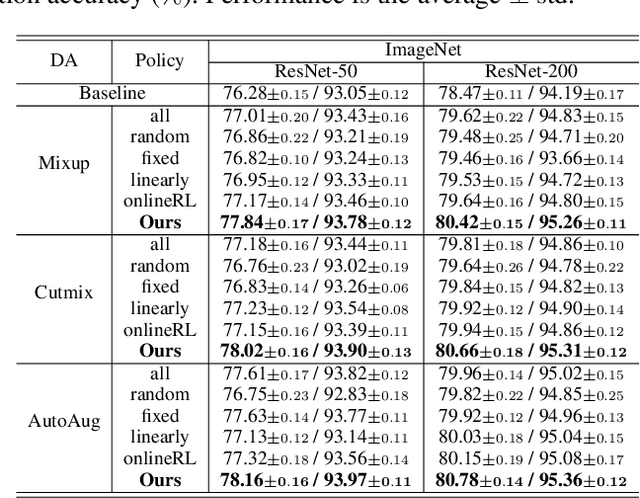
Data augmentation (DA) has been widely investigated to facilitate model optimization in many tasks. However, in most cases, data augmentation is randomly performed for each training sample with a certain probability, which might incur content destruction and visual ambiguities. To eliminate this, in this paper, we propose an effective approach, dubbed SelectAugment, to select samples to be augmented in a deterministic and online manner based on the sample contents and the network training status. Specifically, in each batch, we first determine the augmentation ratio, and then decide whether to augment each training sample under this ratio. We model this process as a two-step Markov decision process and adopt Hierarchical Reinforcement Learning (HRL) to learn the augmentation policy. In this way, the negative effects of the randomness in selecting samples to augment can be effectively alleviated and the effectiveness of DA is improved. Extensive experiments demonstrate that our proposed SelectAugment can be adapted upon numerous commonly used DA methods, e.g., Mixup, Cutmix, AutoAugment, etc, and improve their performance on multiple benchmark datasets of image classification and fine-grained image recognition.
Patch AutoAugment
Mar 20, 2021
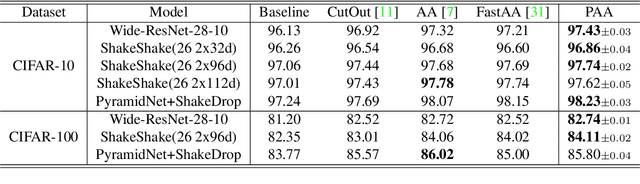
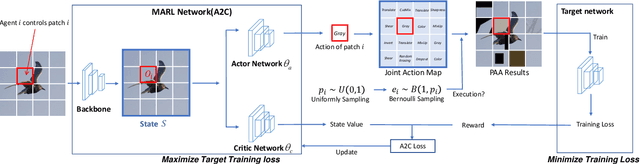
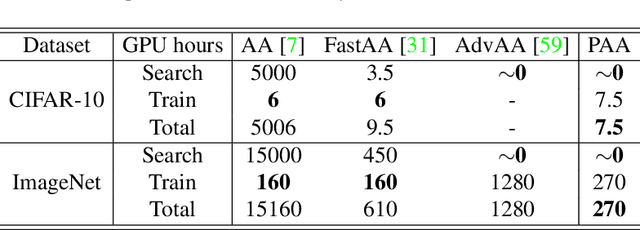
Data augmentation (DA) plays a critical role in training deep neural networks for improving the generalization of models. Recent work has shown that automatic DA policy, such as AutoAugment (AA), significantly improves model performance. However, most automatic DA methods search for DA policies at the image-level without considering that the optimal policies for different regions in an image may be diverse. In this paper, we propose a patch-level automatic DA algorithm called Patch AutoAugment (PAA). PAA divides an image into a grid of patches and searches for the optimal DA policy of each patch. Specifically, PAA allows each patch DA operation to be controlled by an agent and models it as a Multi-Agent Reinforcement Learning (MARL) problem. At each step, PAA samples the most effective operation for each patch based on its content and the semantics of the whole image. The agents cooperate as a team and share a unified team reward for achieving the joint optimal DA policy of the whole image. The experiment shows that PAA consistently improves the target network performance on many benchmark datasets of image classification and fine-grained image recognition. PAA also achieves remarkable computational efficiency, i.e 2.3x faster than FastAA and 56.1x faster than AA on ImageNet.