 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectAugment: Hierarchical Deterministic Sample Selection for Data Augmentation
Paper and Code
Dec 06, 2021
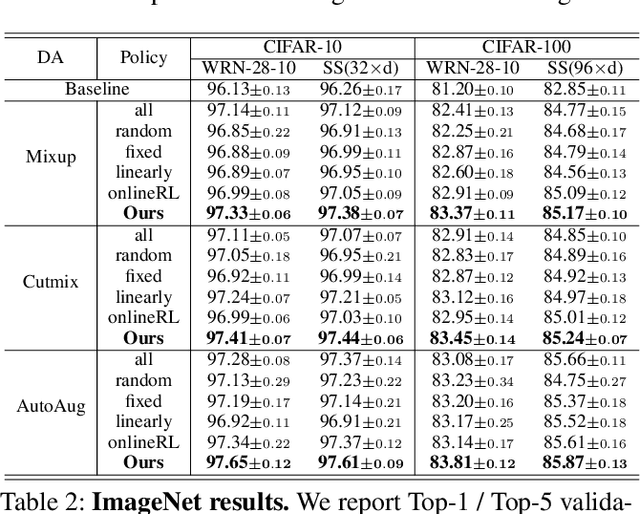
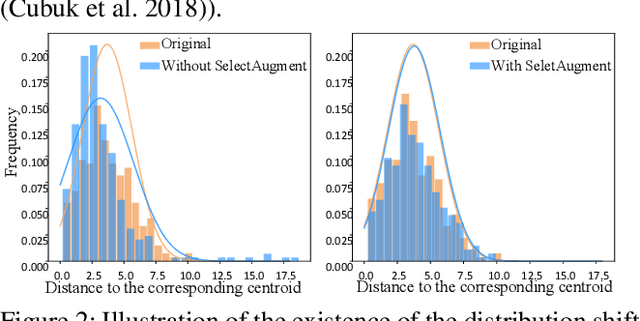
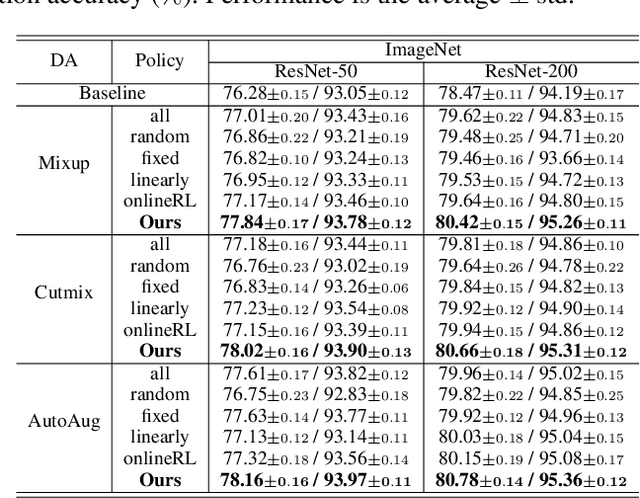
Data augmentation (DA) has been widely investigated to facilitate model optimization in many tasks. However, in most cases, data augmentation is randomly performed for each training sample with a certain probability, which might incur content destruction and visual ambiguities. To eliminate this, in this paper, we propose an effective approach, dubbed SelectAugment, to select samples to be augmented in a deterministic and online manner based on the sample contents and the network training status. Specifically, in each batch, we first determine the augmentation ratio, and then decide whether to augment each training sample under this ratio. We model this process as a two-step Markov decision process and adopt Hierarchical Reinforcement Learning (HRL) to learn the augmentation policy. In this way, the negative effects of the randomness in selecting samples to augment can be effectively alleviated and the effectiveness of DA is improved. Extensive experiments demonstrate that our proposed SelectAugment can be adapted upon numerous commonly used DA methods, e.g., Mixup, Cutmix, AutoAugment, etc, and improve their performance on multiple benchmark datasets of image classification and fine-grained image recognition.