 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch AutoAugment
Paper and Code

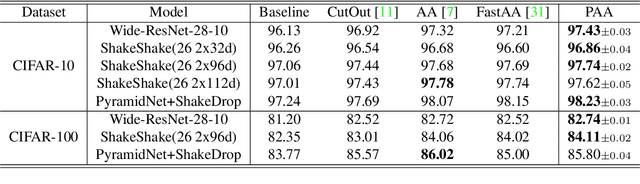
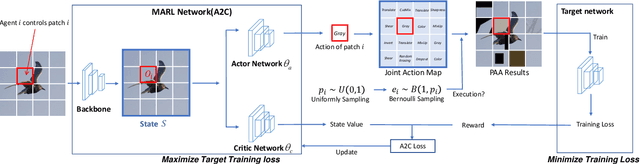
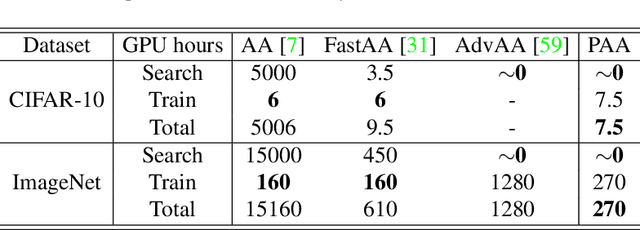
Data augmentation (DA) plays a critical role in training deep neural networks for improving the generalization of models. Recent work has shown that automatic DA policy, such as AutoAugment (AA), significantly improves model performance. However, most automatic DA methods search for DA policies at the image-level without considering that the optimal policies for different regions in an image may be diverse. In this paper, we propose a patch-level automatic DA algorithm called Patch AutoAugment (PAA). PAA divides an image into a grid of patches and searches for the optimal DA policy of each patch. Specifically, PAA allows each patch DA operation to be controlled by an agent and models it as a Multi-Agent Reinforcement Learning (MARL) problem. At each step, PAA samples the most effective operation for each patch based on its content and the semantics of the whole image. The agents cooperate as a team and share a unified team reward for achieving the joint optimal DA policy of the whole image. The experiment shows that PAA consistently improves the target network performance on many benchmark datasets of image classification and fine-grained image recognition. PAA also achieves remarkable computational efficiency, i.e 2.3x faster than FastAA and 56.1x faster than AA on ImageNet.