 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIT Academy: Cultivating the Complete Agent with a Confucian Three-Domain Curriculum
Apr 20, 2026What does it mean to give an AI agent a complete education? Current agent development produces specialists systems optimized for a single capability dimension, whether tool use, code generation, or security awareness that exhibit predictable deficits wherever they were not trained. We argue this pattern reflects a structural absence: there is no curriculum theory for agents, no principled account of what a fully developed agent should know, be, and be able to do across the full scope of intelligent behavior. This paper introduces the AIT Academy (Agents Institute of Technology Academy), a curriculum framework for cultivating AI agents across the tripartite structure of human knowledge. Grounded in Kagan's Three Cultures and UNESCO ISCED-F 2013, AIT organizes agent capability development into three domains: Natural Science and Technical Reasoning (Domain I), Humanities and Creative Expression (Domain II), and Social Science and Ethical Reasoning (Domain III). The Confucian Six Arts (liuyi) a 2,500-year-old holistic education system are reinterpreted as behavioral archetypes that map directly onto trainable agent capabilities within each domain. Three representative training grounds instantiate the framework across multiple backbone LLMs: the ClawdGO Security Dojo (Domain I), Athen's Academy (Domain II), and the Alt Mirage Stage (Domain III). Experiments demonstrate a 15.9-point improvement in security capability scores under weakest-first curriculum scheduling, and a 7-percentage-point gain in social reasoning performance under principled attribution modeling. A cross-domain finding Security Awareness Calibration Pathology (SACP), in which over-trained Domain I agents fail on out-of-distribution evaluation illustrates the diagnostic value of a multi-domain perspective unavailable to any single-domain framework.
Square Superpixel Generation and Representation Learning via Granular Ball Computing
Mar 31, 2026Superpixels provide a compact region-based representation that preserves object boundaries and local structures, and have therefore been widely used in a variety of vision tasks to reduce computational cost. However, most existing superpixel algorithms produce irregularly shaped regions, which are not well aligned with regular operators such as convolutions. Consequently, superpixels are often treated as an offline preprocessing step, limiting parallel implementation and hindering end-to-end optimization within deep learning pipelines. Motivated by the adaptive representation and coverage property of granular-ball computing, we develop a square superpixel generation approach. Specifically, we approximate superpixels using multi-scale square blocks to avoid the computational and implementation difficulties induced by irregular shapes, enabling efficient parallel processing and learnable feature extraction. For each block, a purity score is computed based on pixel-intensity similarity, and high-quality blocks are selected accordingly. The resulting square superpixels can be readily integrated as graph nodes in graph neural networks (GNNs) or as tokens in Vision Transformers (ViTs), facilitating multi-scale information aggregation and structured visual representation. Experimental results on downstream tasks demonstrate consistent performance improvements, validating the effectiveness of the proposed method.
HyperAlign: Hyperbolic Entailment Cones for Adaptive Text-to-Image Alignment Assessment
Jan 08, 2026With the rapid development of text-to-image generation technology, accurately assessing the alignment between generated images and text prompts has become a critical challenge. Existing methods rely on Euclidean space metrics, neglecting the structured nature of semantic alignment, while lacking adaptive capabilities for different samples. To address these limitations, we propose HyperAlign, an adaptive text-to-image alignment assessment framework based on hyperbolic entailment geometry. First, we extract Euclidean features using CLIP and map them to hyperbolic space. Second, we design a dynamic-supervision entailment modeling mechanism that transforms discrete entailment logic into continuous geometric structure supervision. Finally, we propose an adaptive modulation regressor that utilizes hyperbolic geometric features to generate sample-level modulation parameters, adaptively calibrating Euclidean cosine similarity to predict the final score. HyperAlign achieves highly competitive performance on both single database evaluation and cross-database generalization tasks, fully validating the effectiveness of hyperbolic geometric modeling for image-text alignment assessment.
FCA2: Frame Compression-Aware Autoencoder for Modular and Fast Compressed Video Super-Resolution
Jun 13, 2025State-of-the-art (SOTA) compressed video super-resolution (CVSR) models face persistent challenges, including prolonged inference time, complex training pipelines, and reliance on auxiliary information. As video frame rates continue to increase, the diminishing inter-frame differences further expose the limitations of traditional frame-to-frame information exploitation methods, which are inadequate for addressing current video super-resolution (VSR) demands. To overcome these challenges, we propose an efficient and scalable solution inspired by the structural and statistical similarities between hyperspectral images (HSI) and video data. Our approach introduces a compression-driven dimensionality reduction strategy that reduces computational complexity, accelerates inference, and enhances the extraction of temporal information across frames. The proposed modular architecture is designed for seamless integration with existing VSR frameworks, ensuring strong adaptability and transferability across diverse applications. Experimental results demonstrate that our method achieves performance on par with, or surpassing, the current SOTA models, while significantly reducing inference time. By addressing key bottlenecks in CVSR, our work offers a practical and efficient pathway for advancing VSR technology. Our code will be publicly available at https://github.com/handsomewzy/FCA2.
EyeSim-VQA: A Free-Energy-Guided Eye Simulation Framework for Video Quality Assessment
Jun 13, 2025Free-energy-guided self-repair mechanisms have shown promising results in image quality assessment (IQA), but remain under-explored in video quality assessment (VQA), where temporal dynamics and model constraints pose unique challenges. Unlike static images, video content exhibits richer spatiotemporal complexity, making perceptual restoration more difficult. Moreover, VQA systems often rely on pre-trained backbones, which limits the direct integration of enhancement modules without affecting model stability. To address these issues, we propose EyeSimVQA, a novel VQA framework that incorporates free-energy-based self-repair. It adopts a dual-branch architecture, with an aesthetic branch for global perceptual evaluation and a technical branch for fine-grained structural and semantic analysis. Each branch integrates specialized enhancement modules tailored to distinct visual inputs-resized full-frame images and patch-based fragments-to simulate adaptive repair behaviors. We also explore a principled strategy for incorporating high-level visual features without disrupting the original backbone. In addition, we design a biologically inspired prediction head that models sweeping gaze dynamics to better fuse global and local representations for quality prediction. Experiments on five public VQA benchmarks demonstrate that EyeSimVQA achieves competitive or superior performance compared to state-of-the-art methods, while offering improved interpretability through its biologically grounded design.
The Athenian Academy: A Seven-Layer Architecture Model for Multi-Agent Systems
Apr 18, 2025This paper proposes the "Academy of Athens" multi-agent seven-layer framework, aimed at systematically addressing challenges in multi-agent systems (MAS) within artificial intelligence (AI) art creation, such as collaboration efficiency, role allocation, environmental adaptation, and task parallelism. The framework divides MAS into seven layers: multi-agent collaboration, single-agent multi-role playing, single-agent multi-scene traversal, single-agent multi-capability incarnation, different single agents using the same large model to achieve the same target agent, single-agent using different large models to achieve the same target agent, and multi-agent synthesis of the same target agent. Through experimental validation in art creation, the framework demonstrates its unique advantages in task collaboration, cross-scene adaptation, and model fusion. This paper further discusses current challenges such as collaboration mechanism optimization, model stability, and system security, proposing future exploration through technologies like meta-learning and federated learning. The framework provides a structured methodology for multi-agent collaboration in AI art creation and promotes innovative applications in the art field.
CognitionCapturer: Decoding Visual Stimuli From Human EEG Signal With Multimodal Information
Dec 13, 2024



Electroencephalogram (EEG) signals have attracted significant attention from researchers due to their non-invasive nature and high temporal sensitivity in decoding visual stimuli. However, most recent studies have focused solely on the relationship between EEG and image data pairs, neglecting the valuable ``beyond-image-modality" information embedded in EEG signals. This results in the loss of critical multimodal information in EEG. To address this limitation, we propose CognitionCapturer, a unified framework that fully leverages multimodal data to represent EEG signals. Specifically, CognitionCapturer trains Modality Expert Encoders for each modality to extract cross-modal information from the EEG modality. Then, it introduces a diffusion prior to map the EEG embedding space to the CLIP embedding space, followed by using a pretrained generative model, the proposed framework can reconstruct visual stimuli with high semantic and structural fidelity. Notably, the framework does not require any fine-tuning of the generative models and can be extended to incorporate more modalities. Through extensive experiments, we demonstrate that CognitionCapturer outperforms state-of-the-art methods both qualitatively and quantitatively. Code: https://github.com/XiaoZhangYES/CognitionCapturer.
MKANet: A Lightweight Network with Sobel Boundary Loss for Efficient Land-cover Classification of Satellite Remote Sensing Imagery
Jul 28, 2022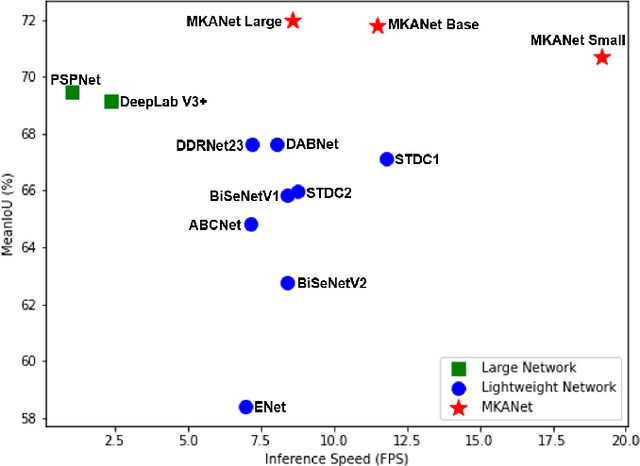
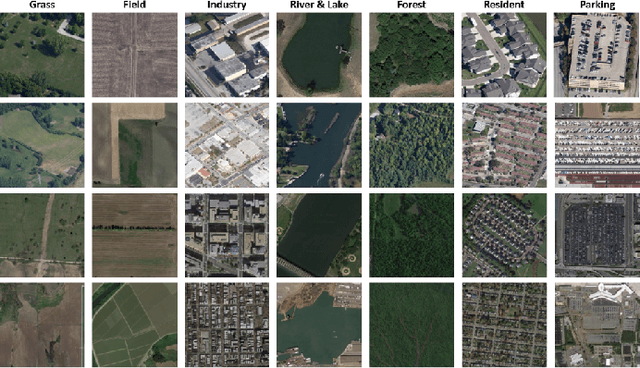
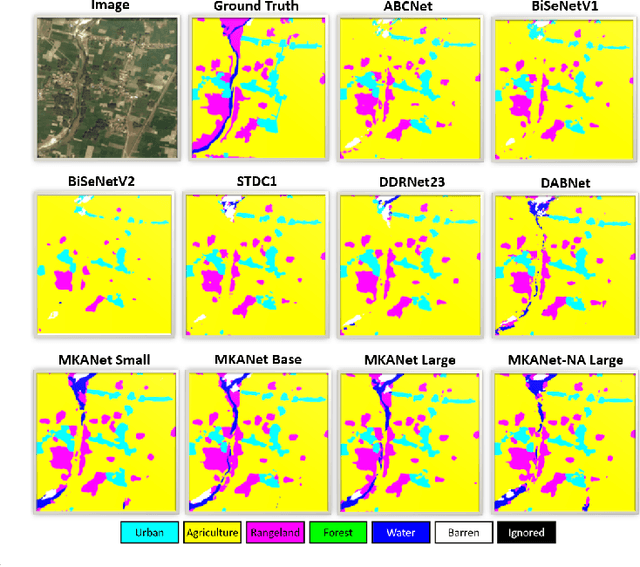
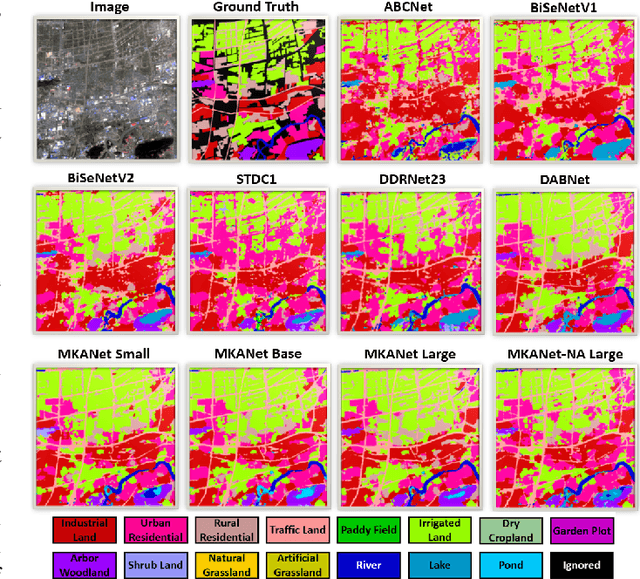
Land cover classification is a multi-class segmentation task to classify each pixel into a certain natural or man-made category of the earth surface, such as water, soil, natural vegetation, crops, and human infrastructure. Limited by hardware computational resources and memory capacity, most existing studies preprocessed original remote sensing images by down sampling or cropping them into small patches less than 512*512 pixels before sending them to a deep neural network. However, down sampling images incurs spatial detail loss, renders small segments hard to discriminate, and reverses the spatial resolution progress obtained by decades of years of efforts. Cropping images into small patches causes a loss of long-range context information, and restoring the predicted results to their original size brings extra latency. In response to the above weaknesses, we present an efficient lightweight semantic segmentation network termed MKANet. Aimed at the characteristics of top view high-resolution remote sensing imagery, MKANet utilizes sharing kernels to simultaneously and equally handle ground segments of inconsistent scales, and also employs parallel and shallow architecture to boost inference speed and friendly support image patches more than 10X larger. To enhance boundary and small segments discrimination, we also propose a method that captures category impurity areas, exploits boundary information and exerts an extra penalty on boundaries and small segment misjudgment. Both visual interpretations and quantitative metrics of extensive experiments demonstrate that MKANet acquires state-of-the-art accuracy on two land-cover classification datasets and infers 2X faster than other competitive lightweight networks. All these merits highlight the potential of MKANet in practical applications.
Do Deep Neural Networks Always Perform Better When Eating More Data?
May 30, 2022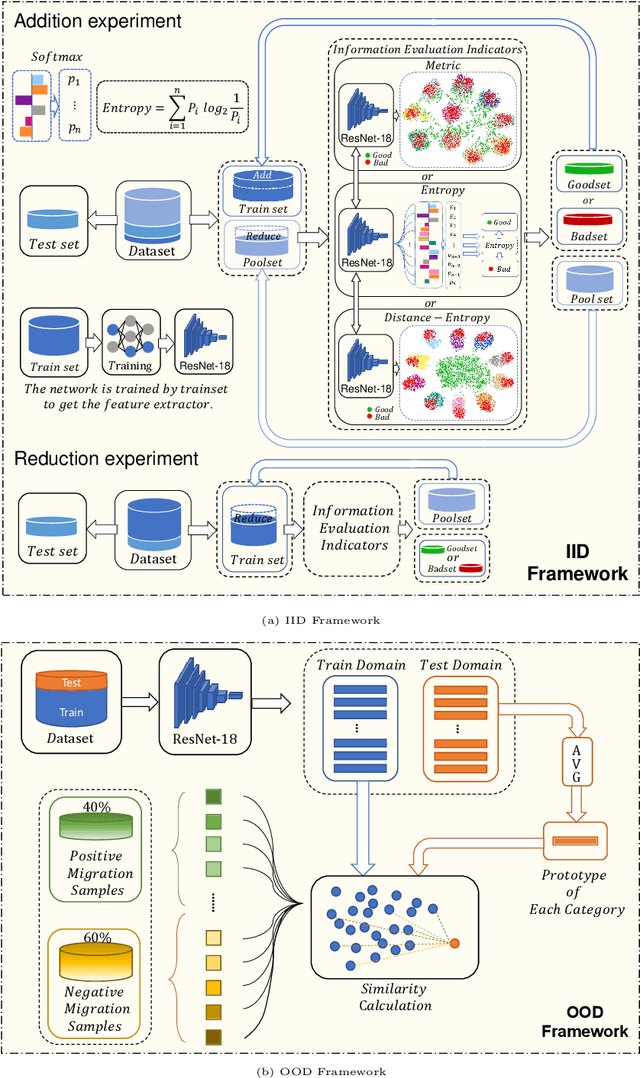
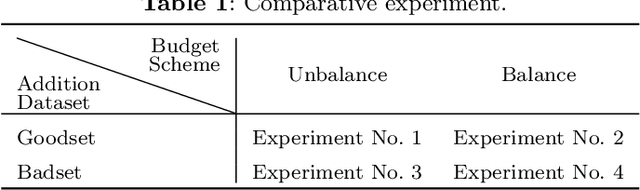
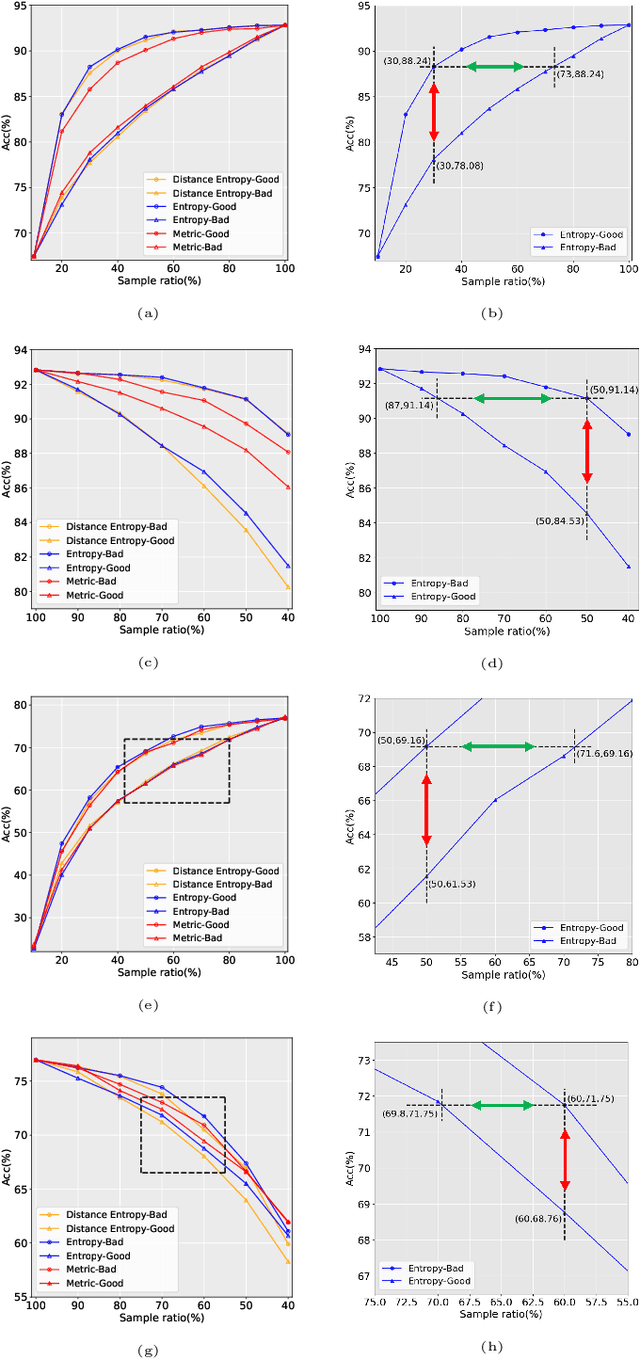
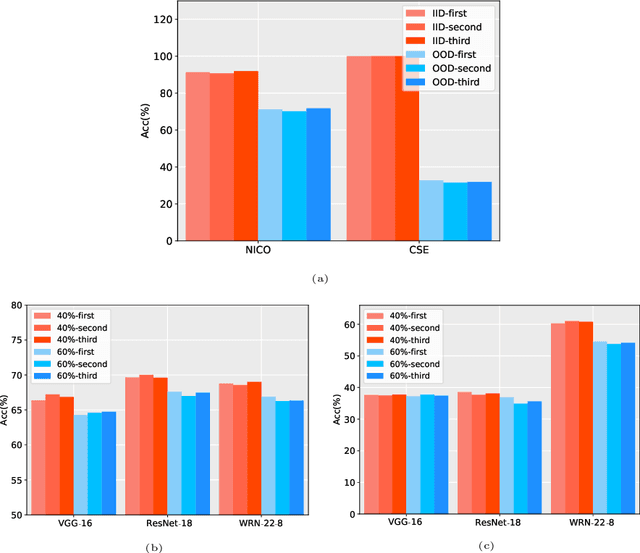
Data has now become a shortcoming of deep learning. Researchers in their own fields share the thinking that "deep neural networks might not always perform better when they eat more data," which still lacks experimental validation and a convincing guiding theory. Here to fill this lack, we design experiments from Identically Independent Distribution(IID) and Out of Distribution(OOD), which give powerful answers. For the purpose of guidance, based on the discussion of results, two theories are proposed: under IID condition, the amount of information determines the effectivity of each sample, the contribution of samples and difference between classes determine the amount of sample information and the amount of class information; under OOD condition, the cross-domain degree of samples determine the contributions, and the bias-fitting caused by irrelevant elements is a significant factor of cross-domain. The above theories provide guidance from the perspective of data, which can promote a wide range of practical applications of artificial intelligence.
Regularized Deep Linear Discriminant Analysis
May 15, 2021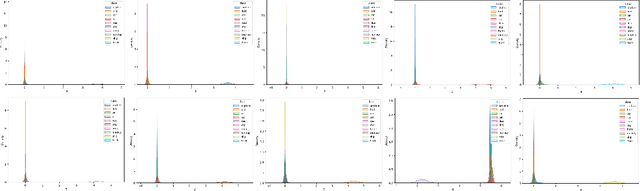

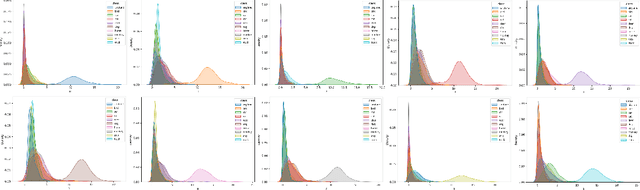
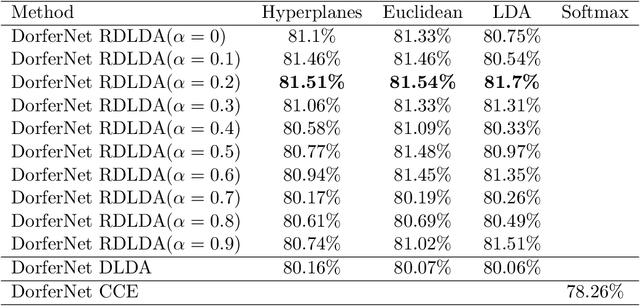
As a non-linear extension of the classic Linear Discriminant Analysis(LDA), Deep Linear Discriminant Analysis(DLDA) replaces the original Categorical Cross Entropy(CCE) loss function with eigenvalue-based loss function to make a deep neural network(DNN) able to learn linearly separable hidden representations. In this paper, we first point out DLDA focuses on training the cooperative discriminative ability of all the dimensions in the latent subspace, while put less emphasis on training the separable capacity of single dimension. To improve DLDA, a regularization method on within-class scatter matrix is proposed to strengthen the discriminative ability of each dimension, and also keep them complement each other. Experiment results on STL-10, CIFAR-10 and Pediatric Pneumonic Chest X-ray Dataset showed that our proposed regularization method Regularized Deep Linear Discriminant Analysis(RDLDA) outperformed DLDA and conventional neural network with CCE as objective. To further improve the discriminative ability of RDLDA in the local space, an algorithm named Subclass RDLDA is also proposed.