 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-specific Convolutional Kernel Modulation for Single Image Super-resolution
Nov 16, 2021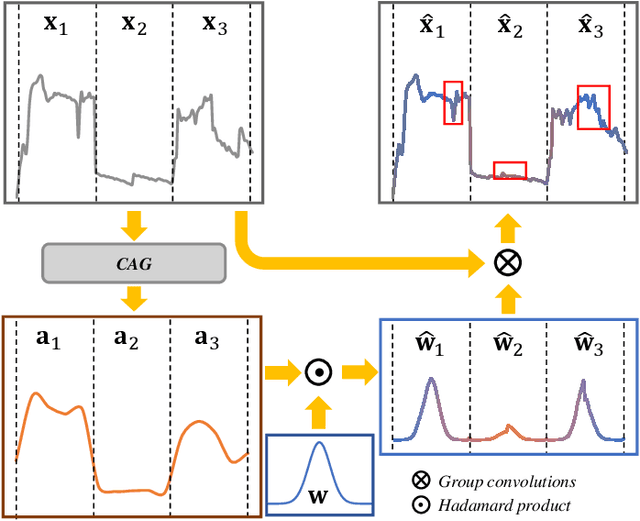
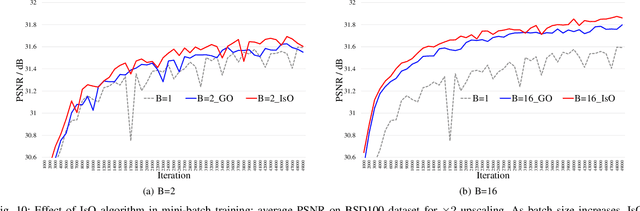
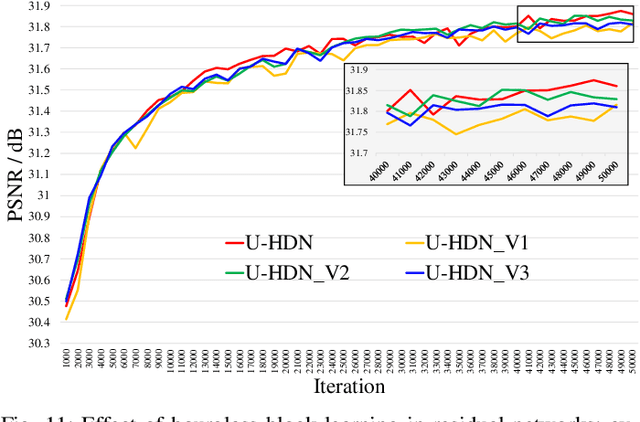
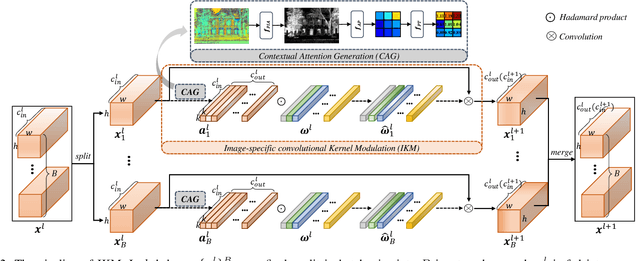
Recently, deep-learning-based super-resolution methods have achieved excellent performances, but mainly focus on training a single generalized deep network by feeding numerous samples. Yet intuitively, each image has its representation, and is expected to acquire an adaptive model. For this issue, we propose a novel image-specific convolutional kernel modulation (IKM) by exploiting the global contextual information of image or feature to generate an attention weight for adaptively modulating the convolutional kernels, which outperforms the vanilla convolution and several existing attention mechanisms while embedding into the state-of-the-art architectures without any additional parameters. Particularly, to optimize our IKM in mini-batch training, we introduce an image-specific optimization (IsO) algorithm, which is more effective than the conventional mini-batch SGD optimization. Furthermore, we investigate the effect of IKM on the state-of-the-art architectures and exploit a new backbone with U-style residual learning and hourglass dense block learning, terms U-Hourglass Dense Network (U-HDN), which is an appropriate architecture to utmost improve the effectiveness of IKM theoretically and experimentally. Extensive experiments on single image super-resolution show that the proposed methods achieve superior performances over state-of-the-art methods. Code is available at github.com/YuanfeiHuang/IKM.
Transitive Learning: Exploring the Transitivity of Degradations for Blind Super-Resolution
Mar 29, 2021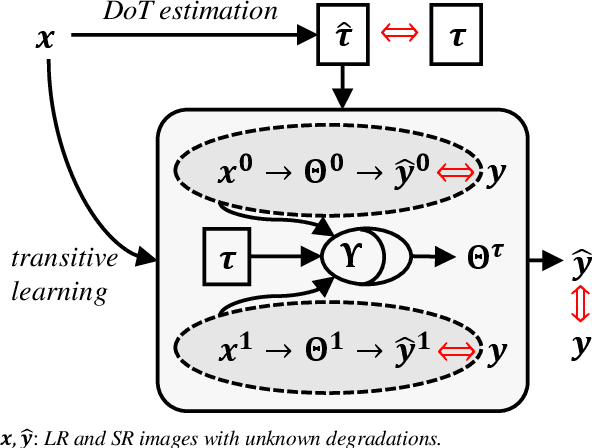
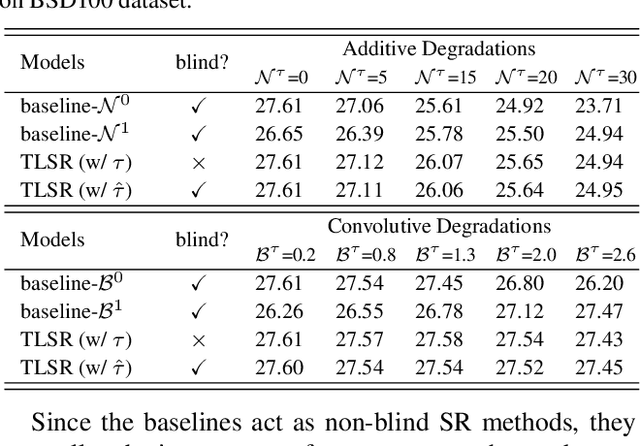
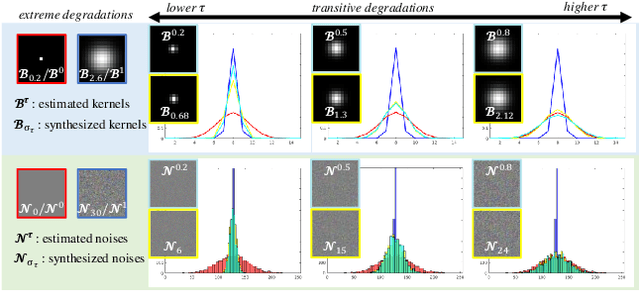
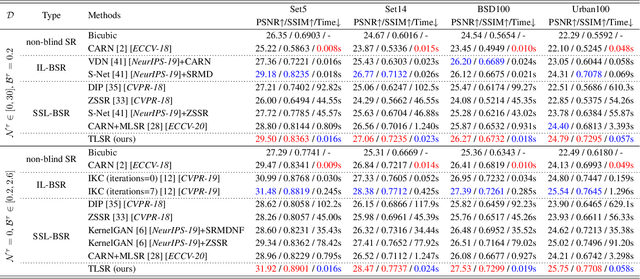
Being extremely dependent on the iterative estimation and correction of data or models, the existing blind super-resolution (SR) methods are generally time-consuming and less effective. To address it, this paper proposes a transitive learning method for blind SR using an end-to-end network without any additional iterations in inference. To begin with, we analyze and demonstrate the transitivity of degradations, including the widely used additive and convolutive degradations. We then propose a novel Transitive Learning method for blind Super-Resolution on transitive degradations (TLSR), by adaptively inferring a transitive transformation function to solve the unknown degradations without any iterative operations in inference. Specifically, the end-to-end TLSR network consists of a degree of transitivity (DoT) estimation network, a homogeneous feature extraction network, and a transitive learning module. Quantitative and qualitative evaluations on blind SR tasks demonstrate that the proposed TLSR achieves superior performance and consumes less time against the state-of-the-art blind SR methods. The code is available at https://github.com/YuanfeiHuang/TLSR.
Interpretable Detail-Fidelity Attention Network for Single Image Super-Resolution
Sep 28, 2020

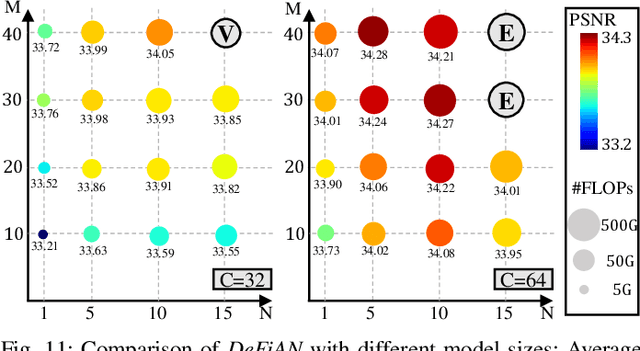
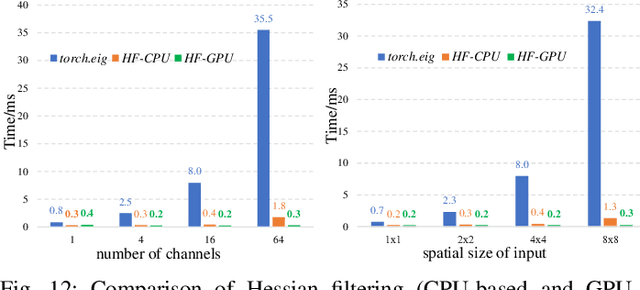
Benefiting from the strong capabilities of deep CNNs for feature representation and nonlinear mapping, deep-learning-based methods have achieved excellent performance in single image super-resolution. However, most existing SR methods depend on the high capacity of networks which is initially designed for visual recognition, and rarely consider the initial intention of super-resolution for detail fidelity. Aiming at pursuing this intention, there are two challenging issues to be solved: (1) learning appropriate operators which is adaptive to the diverse characteristics of smoothes and details; (2) improving the ability of model to preserve the low-frequency smoothes and reconstruct the high-frequency details. To solve them, we propose a purposeful and interpretable detail-fidelity attention network to progressively process these smoothes and details in divide-and-conquer manner, which is a novel and specific prospect of image super-resolution for the purpose on improving the detail fidelity, instead of blindly designing or employing the deep CNNs architectures for merely feature representation in local receptive fields. Particularly, we propose a Hessian filtering for interpretable feature representation which is high-profile for detail inference, a dilated encoder-decoder and a distribution alignment cell to improve the inferred Hessian features in morphological manner and statistical manner respectively. Extensive experiments demonstrate that the proposed methods achieve superior performances over the state-of-the-art methods quantitatively and qualitatively. Code is available at https://github.com/YuanfeiHuang/DeFiAN.
Channel-wise and Spatial Feature Modulation Network for Single Image Super-Resolution
Sep 28, 2018



The performance of single image super-resolution has achieved significant improvement by utilizing deep convolutional neural networks (CNNs). The features in deep CNN contain different types of information which make different contributions to image reconstruction. However, most CNN-based models lack discriminative ability for different types of information and deal with them equally, which results in the representational capacity of the models being limited. On the other hand, as the depth of neural networks grows, the long-term information coming from preceding layers is easy to be weaken or lost in late layers, which is adverse to super-resolving image. To capture more informative features and maintain long-term information for image super-resolution, we propose a channel-wise and spatial feature modulation (CSFM) network in which a sequence of feature-modulation memory (FMM) modules is cascaded with a densely connected structure to transform low-resolution features to high informative features. In each FMM module, we construct a set of channel-wise and spatial attention residual (CSAR) blocks and stack them in a chain structure to dynamically modulate multi-level features in a global-and-local manner. This feature modulation strategy enables the high contribution information to be enhanced and the redundant information to be suppressed. Meanwhile, for long-term information persistence, a gated fusion (GF) node is attached at the end of the FMM module to adaptively fuse hierarchical features and distill more effective information via the dense skip connections and the gating mechanism. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over the state-of-the-art methods.
Single Image Super-Resolution via Cascaded Multi-Scale Cross Network
Feb 24, 2018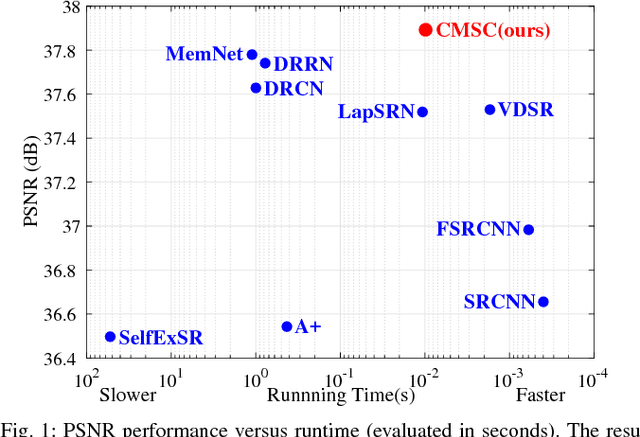

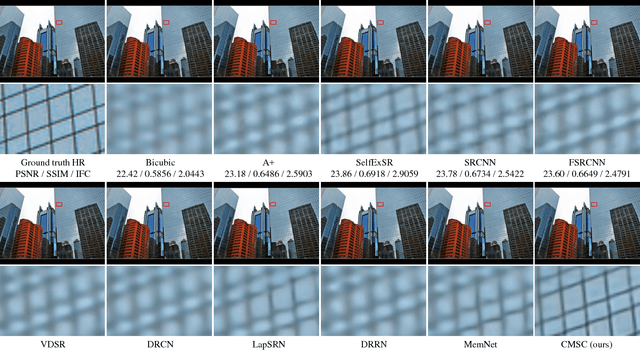
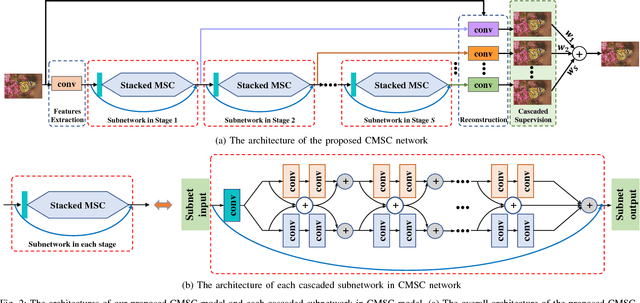
The deep convolutional neural networks have achieved significant improvements in accuracy and speed for single image super-resolution. However, as the depth of network grows, the information flow is weakened and the training becomes harder and harder. On the other hand, most of the models adopt a single-stream structure with which integrating complementary contextual information under different receptive fields is difficult. To improve information flow and to capture sufficient knowledge for reconstructing the high-frequency details, we propose a cascaded multi-scale cross network (CMSC) in which a sequence of subnetworks is cascaded to infer high resolution features in a coarse-to-fine manner. In each cascaded subnetwork, we stack multiple multi-scale cross (MSC) modules to fuse complementary multi-scale information in an efficient way as well as to improve information flow across the layers. Meanwhile, by introducing residual-features learning in each stage, the relative information between high-resolution and low-resolution features is fully utilized to further boost reconstruction performance. We train the proposed network with cascaded-supervision and then assemble the intermediate predictions of the cascade to achieve high quality image reconstruction. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over state-of-the-art super-resolution methods.