 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adaptive Open-Set Object Detection via Category-Level Collaboration Knowledge Mining
Apr 13, 2026Existing object detectors often struggle to generalize across domains while adapting to emerging novel categories. Adaptive open-set object detection (AOOD) addresses this challenge by training on base categories in the source domain and adapting to both base and novel categories in the target domain without target annotations. However, current AOOD methods remain limited by weak cross-domain representations, ambiguity among novel categories, and source-domain feature bias. To address these issues, we propose a category-level collaboration knowledge mining strategy that exploits both inter-class and intra-class relationships across domains. Specifically, we construct a clustering-based memory bank to encode class prototypes, auxiliary features, and intra-class disparity information, and iteratively update it via unsupervised clustering to enhance category-level knowledge representation. We further design a base-to-novel selection metric to discover source-domain features related to novel categories and use them to initialize novel-category classifiers. In addition, an adaptive feature assignment strategy transfers the learned category-level knowledge to the target domain and asynchronously updates the memory bank to alleviate source-domain bias. Extensive experiments on multiple benchmarks show that our method consistently surpasses state-of-the-art AOOD methods by 1.1-5.5 mAP.
Omni-I2C: A Holistic Benchmark for High-Fidelity Image-to-Code Generation
Mar 18, 2026We present Omni-I2C, a comprehensive benchmark designed to evaluate the capability of Large Multimodal Models (LMMs) in converting complex, structured digital graphics into executable code. We argue that this task represents a non-trivial challenge for the current generation of LMMs: it demands an unprecedented synergy between high-fidelity visual perception -- to parse intricate spatial hierarchies and symbolic details -- and precise generative expression -- to synthesize syntactically sound and logically consistent code. Unlike traditional descriptive tasks, Omni-I2C requires a holistic understanding where any minor perceptual hallucination or coding error leads to a complete failure in visual reconstruction. Omni-I2C features 1080 meticulously curated samples, defined by its breadth across subjects, image modalities, and programming languages. By incorporating authentic user-sourced cases, the benchmark spans a vast spectrum of digital content -- from scientific visualizations to complex symbolic notations -- each paired with executable reference code. To complement this diversity, our evaluation framework provides necessary depth; by decoupling performance into perceptual fidelity and symbolic precision, it transcends surface-level accuracy to expose the granular structural failures and reasoning bottlenecks of current LMMs. Our evaluation reveals a substantial performance gap among leading LMMs; even state-of-the-art models struggle to preserve structural integrity in complex scenarios, underscoring that multimodal code generation remains a formidable challenge. Data and code are available at https://github.com/MiliLab/Omni-I2C.
CognitionCapturerPro: Towards High-Fidelity Visual Decoding from EEG/MEG via Multi-modal Information and Asymmetric Alignment
Mar 13, 2026Visual stimuli reconstruction from EEG remains challenging due to fidelity loss and representation shift. We propose CognitionCapturerPro, an enhanced framework that integrates EEG with multi-modal priors (images, text, depth, and edges) via collaborative training. Our core contributions include an uncertainty-weighted similarity scoring mechanism to quantify modality-specific fidelity and a fusion encoder for integrating shared representations. By employing a simplified alignment module and a pre-trained diffusion model, our method significantly outperforms the original CognitionCapturer on the THINGS-EEG dataset, improving Top-1 and Top-5 retrieval accuracy by 25.9% and 10.6%, respectively. Code is available at: https://github.com/XiaoZhangYES/CognitionCapturerPro.
HyperAlign: Hyperbolic Entailment Cones for Adaptive Text-to-Image Alignment Assessment
Jan 08, 2026With the rapid development of text-to-image generation technology, accurately assessing the alignment between generated images and text prompts has become a critical challenge. Existing methods rely on Euclidean space metrics, neglecting the structured nature of semantic alignment, while lacking adaptive capabilities for different samples. To address these limitations, we propose HyperAlign, an adaptive text-to-image alignment assessment framework based on hyperbolic entailment geometry. First, we extract Euclidean features using CLIP and map them to hyperbolic space. Second, we design a dynamic-supervision entailment modeling mechanism that transforms discrete entailment logic into continuous geometric structure supervision. Finally, we propose an adaptive modulation regressor that utilizes hyperbolic geometric features to generate sample-level modulation parameters, adaptively calibrating Euclidean cosine similarity to predict the final score. HyperAlign achieves highly competitive performance on both single database evaluation and cross-database generalization tasks, fully validating the effectiveness of hyperbolic geometric modeling for image-text alignment assessment.
EyeSim-VQA: A Free-Energy-Guided Eye Simulation Framework for Video Quality Assessment
Jun 13, 2025Free-energy-guided self-repair mechanisms have shown promising results in image quality assessment (IQA), but remain under-explored in video quality assessment (VQA), where temporal dynamics and model constraints pose unique challenges. Unlike static images, video content exhibits richer spatiotemporal complexity, making perceptual restoration more difficult. Moreover, VQA systems often rely on pre-trained backbones, which limits the direct integration of enhancement modules without affecting model stability. To address these issues, we propose EyeSimVQA, a novel VQA framework that incorporates free-energy-based self-repair. It adopts a dual-branch architecture, with an aesthetic branch for global perceptual evaluation and a technical branch for fine-grained structural and semantic analysis. Each branch integrates specialized enhancement modules tailored to distinct visual inputs-resized full-frame images and patch-based fragments-to simulate adaptive repair behaviors. We also explore a principled strategy for incorporating high-level visual features without disrupting the original backbone. In addition, we design a biologically inspired prediction head that models sweeping gaze dynamics to better fuse global and local representations for quality prediction. Experiments on five public VQA benchmarks demonstrate that EyeSimVQA achieves competitive or superior performance compared to state-of-the-art methods, while offering improved interpretability through its biologically grounded design.
FCA2: Frame Compression-Aware Autoencoder for Modular and Fast Compressed Video Super-Resolution
Jun 13, 2025State-of-the-art (SOTA) compressed video super-resolution (CVSR) models face persistent challenges, including prolonged inference time, complex training pipelines, and reliance on auxiliary information. As video frame rates continue to increase, the diminishing inter-frame differences further expose the limitations of traditional frame-to-frame information exploitation methods, which are inadequate for addressing current video super-resolution (VSR) demands. To overcome these challenges, we propose an efficient and scalable solution inspired by the structural and statistical similarities between hyperspectral images (HSI) and video data. Our approach introduces a compression-driven dimensionality reduction strategy that reduces computational complexity, accelerates inference, and enhances the extraction of temporal information across frames. The proposed modular architecture is designed for seamless integration with existing VSR frameworks, ensuring strong adaptability and transferability across diverse applications. Experimental results demonstrate that our method achieves performance on par with, or surpassing, the current SOTA models, while significantly reducing inference time. By addressing key bottlenecks in CVSR, our work offers a practical and efficient pathway for advancing VSR technology. Our code will be publicly available at https://github.com/handsomewzy/FCA2.
A Multi-annotated and Multi-modal Dataset for Wide-angle Video Quality Assessment
Jan 21, 2025Wide-angle video is favored for its wide viewing angle and ability to capture a large area of scenery, making it an ideal choice for sports and adventure recording. However, wide-angle video is prone to deformation, exposure and other distortions, resulting in poor video quality and affecting the perception and experience, which may seriously hinder its application in fields such as competitive sports. Up to now, few explorations focus on the quality assessment issue of wide-angle video. This deficiency primarily stems from the absence of a specialized dataset for wide-angle videos. To bridge this gap, we construct the first Multi-annotated and multi-modal Wide-angle Video quality assessment (MWV) dataset. Then, the performances of state-of-the-art video quality methods on the MWV dataset are investigated by inter-dataset testing and intra-dataset testing. Experimental results show that these methods impose significant limitations on their applicability.
CognitionCapturer: Decoding Visual Stimuli From Human EEG Signal With Multimodal Information
Dec 13, 2024



Electroencephalogram (EEG) signals have attracted significant attention from researchers due to their non-invasive nature and high temporal sensitivity in decoding visual stimuli. However, most recent studies have focused solely on the relationship between EEG and image data pairs, neglecting the valuable ``beyond-image-modality" information embedded in EEG signals. This results in the loss of critical multimodal information in EEG. To address this limitation, we propose CognitionCapturer, a unified framework that fully leverages multimodal data to represent EEG signals. Specifically, CognitionCapturer trains Modality Expert Encoders for each modality to extract cross-modal information from the EEG modality. Then, it introduces a diffusion prior to map the EEG embedding space to the CLIP embedding space, followed by using a pretrained generative model, the proposed framework can reconstruct visual stimuli with high semantic and structural fidelity. Notably, the framework does not require any fine-tuning of the generative models and can be extended to incorporate more modalities. Through extensive experiments, we demonstrate that CognitionCapturer outperforms state-of-the-art methods both qualitatively and quantitatively. Code: https://github.com/XiaoZhangYES/CognitionCapturer.
AI-Generated Image Quality Assessment Based on Task-Specific Prompt and Multi-Granularity Similarity
Nov 25, 2024



Recently, AI-generated images (AIGIs) created by given prompts (initial prompts) have garnered widespread attention. Nevertheless, due to technical nonproficiency, they often suffer from poor perception quality and Text-to-Image misalignment. Therefore, assessing the perception quality and alignment quality of AIGIs is crucial to improving the generative model's performance. Existing assessment methods overly rely on the initial prompts in the task prompt design and use the same prompts to guide both perceptual and alignment quality evaluation, overlooking the distinctions between the two tasks. To address this limitation, we propose a novel quality assessment method for AIGIs named TSP-MGS, which designs task-specific prompts and measures multi-granularity similarity between AIGIs and the prompts. Specifically, task-specific prompts are first constructed to describe perception and alignment quality degrees separately, and the initial prompt is introduced for detailed quality perception. Then, the coarse-grained similarity between AIGIs and task-specific prompts is calculated, which facilitates holistic quality awareness. In addition, to improve the understanding of AIGI details, the fine-grained similarity between the image and the initial prompt is measured. Finally, precise quality prediction is acquired by integrating the multi-granularity similarities. Experiments on the commonly used AGIQA-1K and AGIQA-3K benchmarks demonstrate the superiority of the proposed TSP-MGS.
Feature Erasing and Diffusion Network for Occluded Person Re-Identification
Dec 16, 2021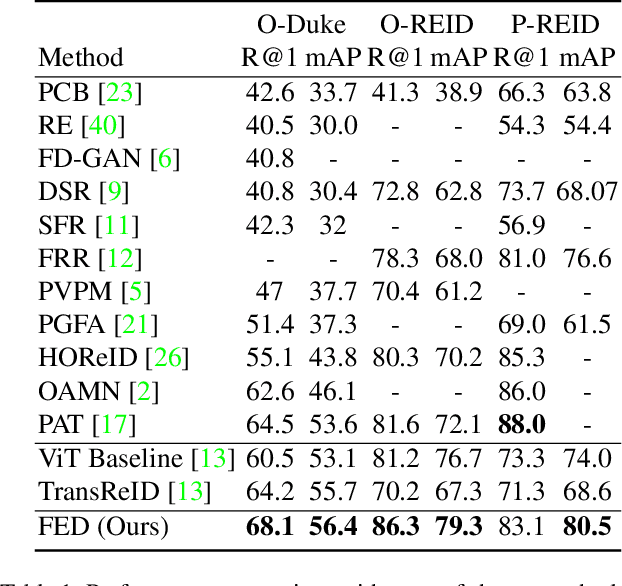
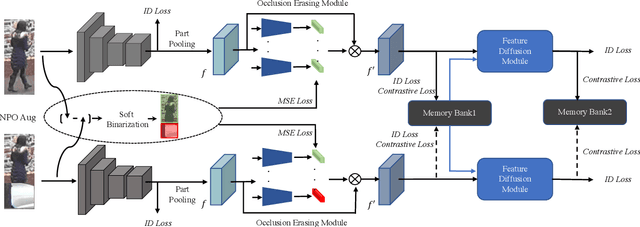
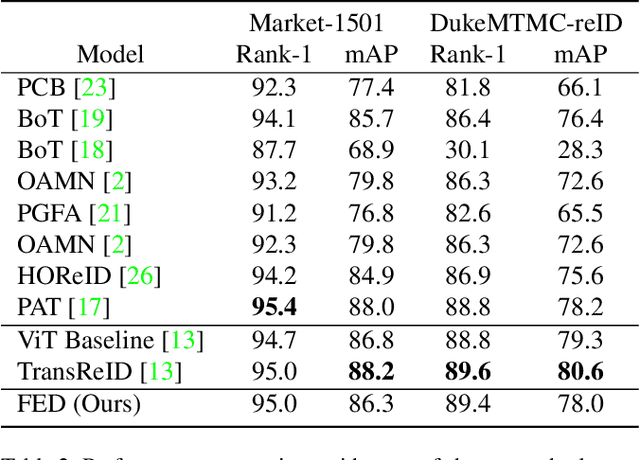
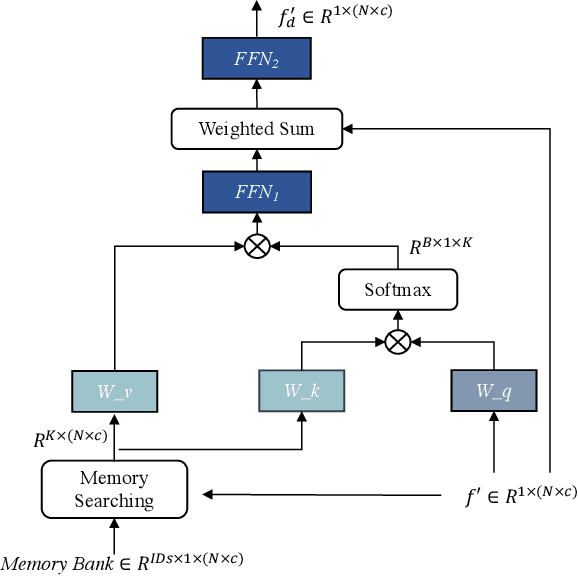
Occluded person re-identification (ReID) aims at matching occluded person images to holistic ones across different camera views. Target Pedestrians (TP) are usually disturbed by Non-Pedestrian Occlusions (NPO) and NonTarget Pedestrians (NTP). Previous methods mainly focus on increasing model's robustness against NPO while ignoring feature contamination from NTP. In this paper, we propose a novel Feature Erasing and Diffusion Network (FED) to simultaneously handle NPO and NTP. Specifically, NPO features are eliminated by our proposed Occlusion Erasing Module (OEM), aided by the NPO augmentation strategy which simulates NPO on holistic pedestrian images and generates precise occlusion masks. Subsequently, we Subsequently, we diffuse the pedestrian representations with other memorized features to synthesize NTP characteristics in the feature space which is achieved by a novel Feature Diffusion Module (FDM) through a learnable cross attention mechanism. With the guidance of the occlusion scores from OEM, the feature diffusion process is mainly conducted on visible body parts, which guarantees the quality of the synthesized NTP characteristics. By jointly optimizing OEM and FDM in our proposed FED network, we can greatly improve the model's perception ability towards TP and alleviate the influence of NPO and NTP. Furthermore, the proposed FDM only works as an auxiliary module for training and will be discarded in the inference phase, thus introducing little inference computational overhead. Experiments on occluded and holistic person ReID benchmarks demonstrate the superiority of FED over state-of-the-arts, where FED achieves 86.3% Rank-1 accuracy on Occluded-REID, surpassing others by at least 4.7%.