 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards World Models in Biomedical Research
Jun 04, 2026A central goal of biomedicine is to understand, predict and ultimately control the dynamic mechanisms by which biological systems respond to perturbations, disease progression and therapeutic intervention. Although foundation models and large language models have accelerated biomedical data interpretation, most current systems remain focused on static pattern recognition rather than prospective simulation of biological futures. Here we propose biomedical world models as a paradigm for AI-driven discovery. These models learn latent representations of molecular, cellular, tissue and clinical states, together with intervention-conditioned dynamics that allow future trajectories to be simulated before actions are taken. We discuss how biomedical world models could function as data engines, environment simulators and scientific planning substrates across applications including virtual cells, organoids, virtual patients and surgical simulation. We outline the data infrastructure, evaluation benchmarks, safety constraints and governance frameworks required. Biomedical world models may provide a foundation for simulation-guided, closed-loop and experimentally actionable biomedical discovery.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Rethinking Cancer Gene Identification through Graph Anomaly Analysis
Dec 23, 2024



Graph neural networks (GNNs) have shown promise in integrating protein-protein interaction (PPI) networks for identifying cancer genes in recent studies. However, due to the insufficient modeling of the biological information in PPI networks, more faithfully depiction of complex protein interaction patterns for cancer genes within the graph structure remains largely unexplored. This study takes a pioneering step toward bridging biological anomalies in protein interactions caused by cancer genes to statistical graph anomaly. We find a unique graph anomaly exhibited by cancer genes, namely weight heterogeneity, which manifests as significantly higher variance in edge weights of cancer gene nodes within the graph. Additionally, from the spectral perspective, we demonstrate that the weight heterogeneity could lead to the "flattening out" of spectral energy, with a concentration towards the extremes of the spectrum. Building on these insights, we propose the HIerarchical-Perspective Graph Neural Network (HIPGNN) that not only determines spectral energy distribution variations on the spectral perspective, but also perceives detailed protein interaction context on the spatial perspective. Extensive experiments are conducted on two reprocessed datasets STRINGdb and CPDB, and the experimental results demonstrate the superiority of HIPGNN.
Histo-Genomic Knowledge Distillation For Cancer Prognosis From Histopathology Whole Slide Images
Mar 18, 2024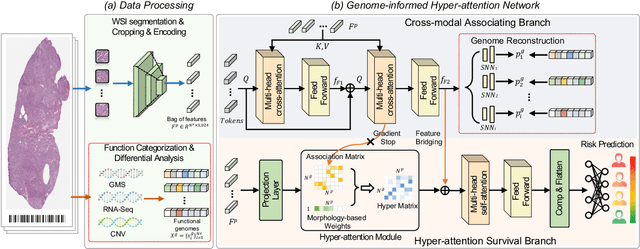
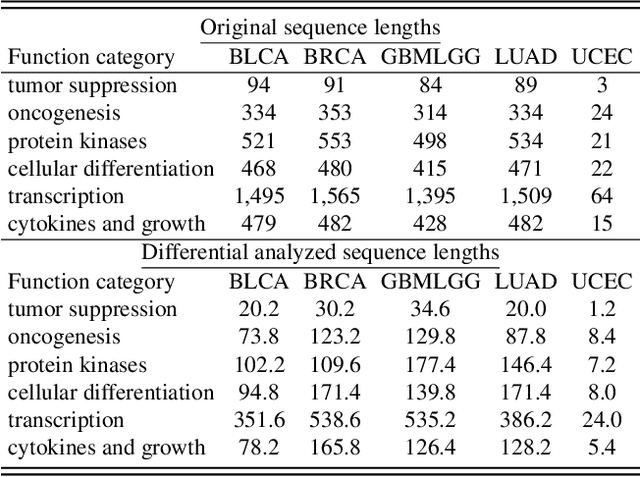
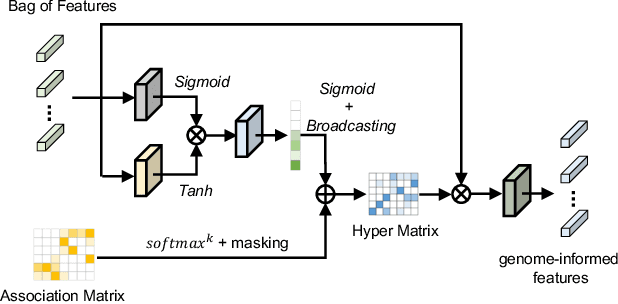
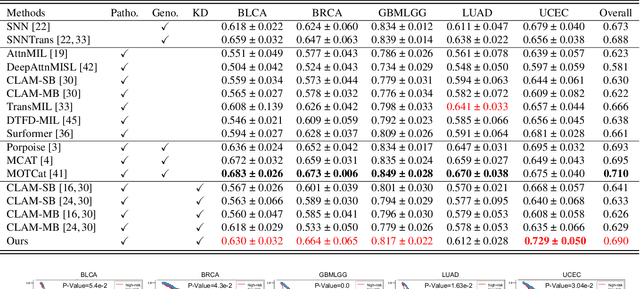
Histo-genomic multi-modal methods have recently emerged as a powerful paradigm, demonstrating significant potential for improving cancer prognosis. However, genome sequencing, unlike histopathology imaging, is still not widely accessible in underdeveloped regions, limiting the application of these multi-modal approaches in clinical settings. To address this, we propose a novel Genome-informed Hyper-Attention Network, termed G-HANet, which is capable of effectively distilling the histo-genomic knowledge during training to elevate uni-modal whole slide image (WSI)-based inference for the first time. Compared with traditional knowledge distillation methods (i.e., teacher-student architecture) in other tasks, our end-to-end model is superior in terms of training efficiency and learning cross-modal interactions. Specifically, the network comprises the cross-modal associating branch (CAB) and hyper-attention survival branch (HSB). Through the genomic data reconstruction from WSIs, CAB effectively distills the associations between functional genotypes and morphological phenotypes and offers insights into the gene expression profiles in the feature space. Subsequently, HSB leverages the distilled histo-genomic associations as well as the generated morphology-based weights to achieve the hyper-attention modeling of the patients from both histopathology and genomic perspectives to improve cancer prognosis. Extensive experiments are conducted on five TCGA benchmarking datasets and the results demonstrate that G-HANet significantly outperforms the state-of-the-art WSI-based methods and achieves competitive performance with genome-based and multi-modal methods. G-HANet is expected to be explored as a useful tool by the research community to address the current bottleneck of insufficient histo-genomic data pairing in the context of cancer prognosis and precision oncology.
Multiplex-detection Based Multiple Instance Learning Network for Whole Slide Image Classification
Aug 06, 2022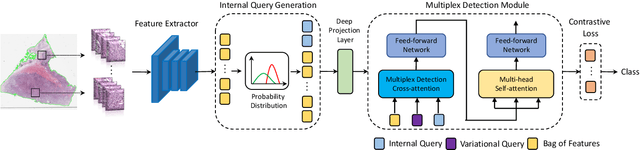
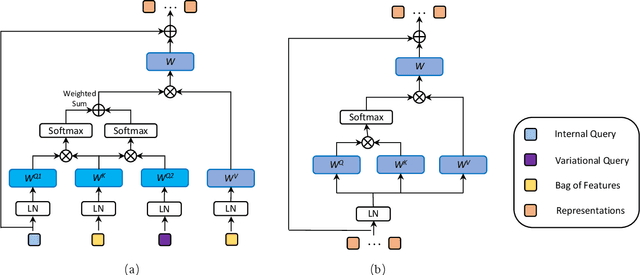
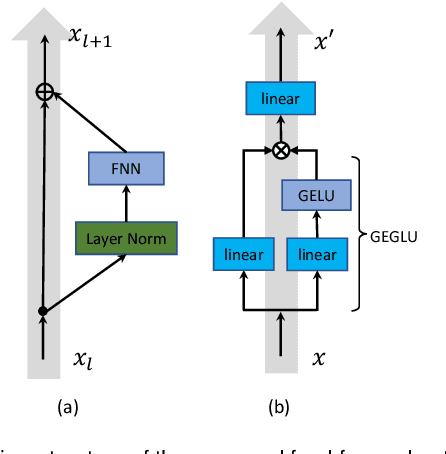
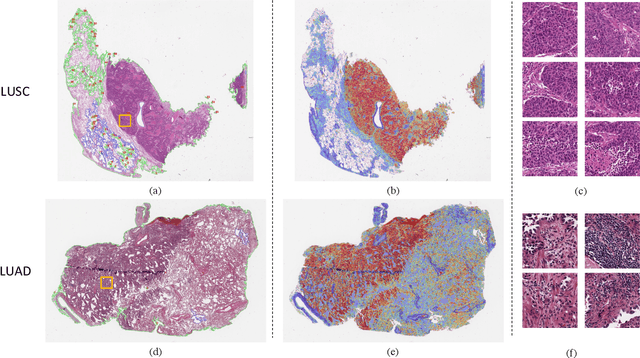
Multiple instance learning (MIL) is a powerful approach to classify whole slide images (WSIs) for diagnostic pathology. A fundamental challenge of MIL on WSI classification is to discover the \textit{critical instances} that trigger the bag label. However, previous methods are primarily designed under the independent and identical distribution hypothesis (\textit{i.i.d}), ignoring either the correlations between instances or heterogeneity of tumours. In this paper, we propose a novel multiplex-detection-based multiple instance learning (MDMIL) to tackle the issues above. Specifically, MDMIL is constructed by the internal query generation module (IQGM) and the multiplex detection module (MDM) and assisted by the memory-based contrastive loss during training. Firstly, IQGM gives the probability of instances and generates the internal query (IQ) for the subsequent MDM by aggregating highly reliable features after the distribution analysis. Secondly, the multiplex-detection cross-attention (MDCA) and multi-head self-attention (MHSA) in MDM cooperate to generate the final representations for the WSI. In this process, the IQ and trainable variational query (VQ) successfully build up the connections between instances and significantly improve the model's robustness toward heterogeneous tumours. At last, to further enforce constraints in the feature space and stabilize the training process, we adopt a memory-based contrastive loss, which is practicable for WSI classification even with a single sample as input in each iteration. We conduct experiments on three computational pathology datasets, e.g., CAMELYON16, TCGA-NSCLC, and TCGA-RCC datasets. The superior accuracy and AUC demonstrate the superiority of our proposed MDMIL over other state-of-the-art methods.
Multi-channel deep convolutional neural networks for multi-classifying thyroid disease
Mar 06, 2022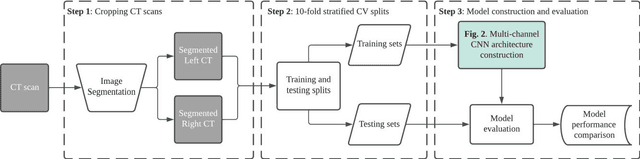

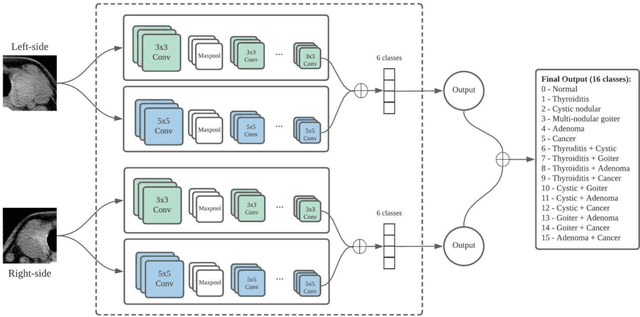

Thyroid disease instances have been continuously increasing since the 1990s, and thyroid cancer has become the most rapidly rising disease among all the malignancies in recent years. Most existing studies focused on applying deep convolutional neural networks for detecting thyroid cancer. Despite their satisfactory performance on binary classification tasks, limited studies have explored multi-class classification of thyroid disease types; much less is known of the diagnosis of co-existence situation for different types of thyroid diseases. Therefore, this study proposed a novel multi-channel convolutional neural network (CNN) architecture to address the multi-class classification task of thyroid disease. The multi-channel CNN merits from computed tomography to drive a comprehensive diagnostic decision for the overall thyroid gland, emphasizing the disease co-existence circumstance. Moreover, this study also examined alternative strategies to enhance the diagnostic accuracy of CNN models through concatenation of different scales of feature maps. Benchmarking experiments demonstrate the improved performance of the proposed multi-channel CNN architecture compared with the standard single-channel CNN architecture. More specifically, the multi-channel CNN achieved an accuracy of 0.909, precision of 0.944, recall of 0.896, specificity of 0.994, and F1 of 0.917, in contrast to the single-channel CNN, which obtained 0.902, 0.892, 0.909, 0.993, 0.898, respectively. In addition, the proposed model was evaluated in different gender groups; it reached a diagnostic accuracy of 0.908 for the female group and 0.901 for the male group. Collectively, the results highlight that the proposed multi-channel CNN has excellent generalization and has the potential to be deployed to provide computational decision support in clinical settings.
Personalized On-Device E-health Analytics with Decentralized Block Coordinate Descent
Dec 17, 2021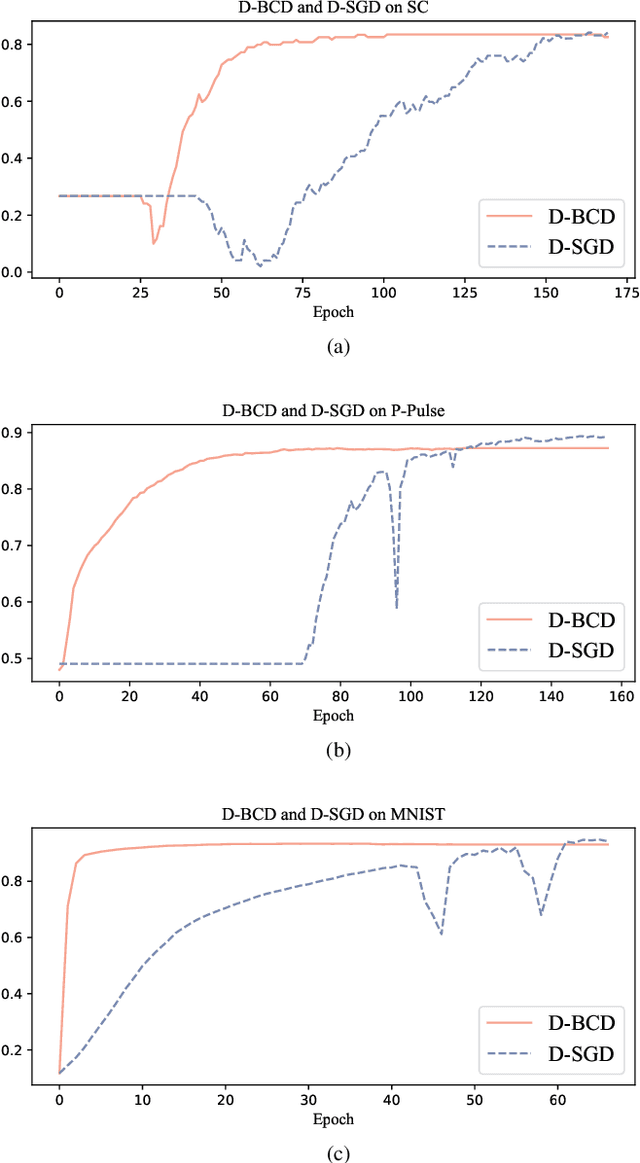
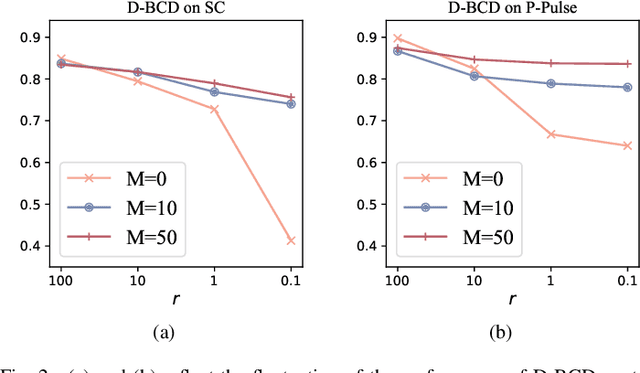

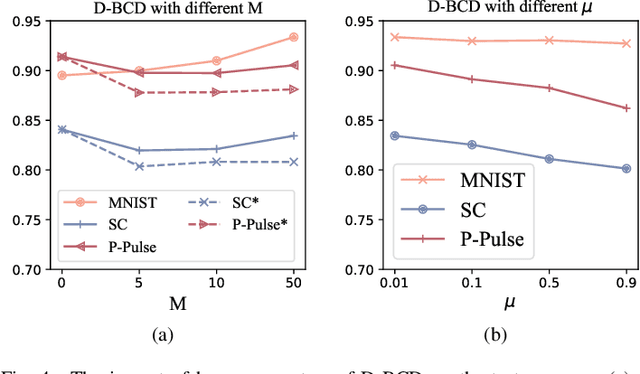
Actuated by the growing attention to personal healthcare and the pandemic, the popularity of E-health is proliferating. Nowadays, enhancement on medical diagnosis via machine learning models has been highly effective in many aspects of e-health analytics. Nevertheless, in the classic cloud-based/centralized e-health paradigms, all the data will be centrally stored on the server to facilitate model training, which inevitably incurs privacy concerns and high time delay. Distributed solutions like Decentralized Stochastic Gradient Descent (D-SGD) are proposed to provide safe and timely diagnostic results based on personal devices. However, methods like D-SGD are subject to the gradient vanishing issue and usually proceed slowly at the early training stage, thereby impeding the effectiveness and efficiency of training. In addition, existing methods are prone to learning models that are biased towards users with dense data, compromising the fairness when providing E-health analytics for minority groups. In this paper, we propose a Decentralized Block Coordinate Descent (D-BCD) learning framework that can better optimize deep neural network-based models distributed on decentralized devices for E-health analytics. Benchmarking experiments on three real-world datasets illustrate the effectiveness and practicality of our proposed D-BCD, where additional simulation study showcases the strong applicability of D-BCD in real-life E-health scenarios.
Feature Erasing and Diffusion Network for Occluded Person Re-Identification
Dec 16, 2021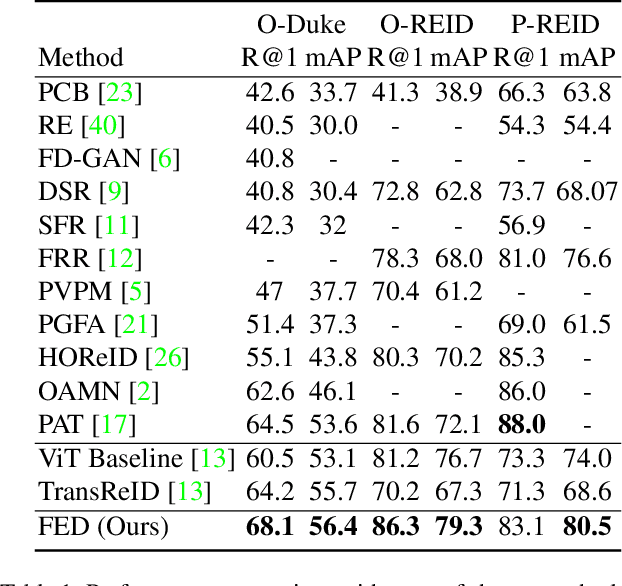
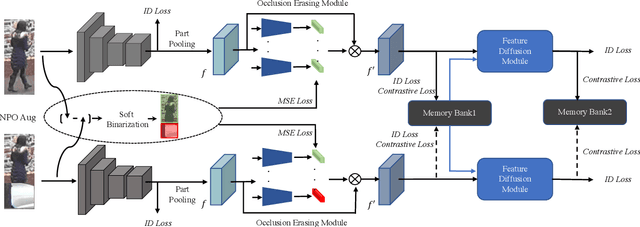
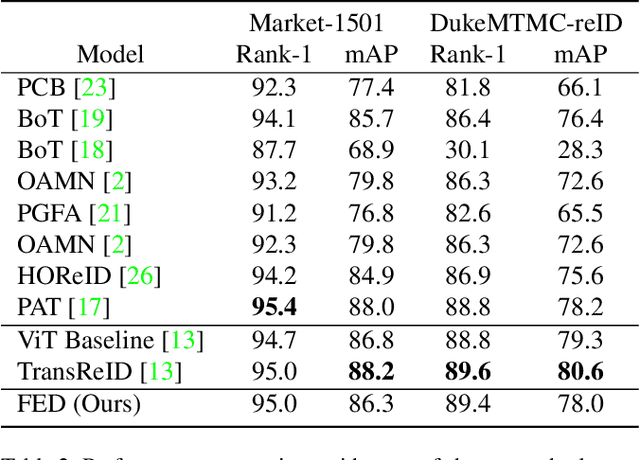
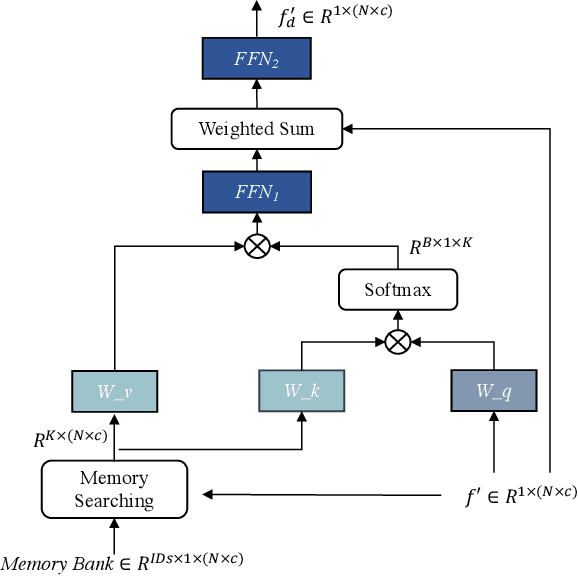
Occluded person re-identification (ReID) aims at matching occluded person images to holistic ones across different camera views. Target Pedestrians (TP) are usually disturbed by Non-Pedestrian Occlusions (NPO) and NonTarget Pedestrians (NTP). Previous methods mainly focus on increasing model's robustness against NPO while ignoring feature contamination from NTP. In this paper, we propose a novel Feature Erasing and Diffusion Network (FED) to simultaneously handle NPO and NTP. Specifically, NPO features are eliminated by our proposed Occlusion Erasing Module (OEM), aided by the NPO augmentation strategy which simulates NPO on holistic pedestrian images and generates precise occlusion masks. Subsequently, we Subsequently, we diffuse the pedestrian representations with other memorized features to synthesize NTP characteristics in the feature space which is achieved by a novel Feature Diffusion Module (FDM) through a learnable cross attention mechanism. With the guidance of the occlusion scores from OEM, the feature diffusion process is mainly conducted on visible body parts, which guarantees the quality of the synthesized NTP characteristics. By jointly optimizing OEM and FDM in our proposed FED network, we can greatly improve the model's perception ability towards TP and alleviate the influence of NPO and NTP. Furthermore, the proposed FDM only works as an auxiliary module for training and will be discarded in the inference phase, thus introducing little inference computational overhead. Experiments on occluded and holistic person ReID benchmarks demonstrate the superiority of FED over state-of-the-arts, where FED achieves 86.3% Rank-1 accuracy on Occluded-REID, surpassing others by at least 4.7%.