 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNecessity of Cooperative Transmissions for Wireless MapReduce
Jan 17, 2026The paper presents an improved upper bound (achievability result) on the optimal tradeoff between Normalized Delivery Time (NDT) and computation load for distributed computing MapReduce systems in certain ranges of the parameters. The upper bound is based on interference alignment combined with zero-forcing. The paper further provides a lower bound (converse) on the optimal NDT-computation tradeoff that can be achieved when IVAs are partitioned into sub-IVAs, and these sub-IVAs are then transmitted (in an arbitrary form) by a single node, without cooperation among nodes. For appropriate linear functions (e.g., XORs), such non-cooperative schemes can achieve some of the best NDT-computation tradeoff points so far obtained in the literature. However, as our lower bound shows, any non-cooperative scheme achieves a worse NDT-computation tradeoff than our new proposed scheme for certain parameters, thus proving the necessity of cooperative schemes like zero-forcing to attain the optimal NDT-computation tradeoff.
Interference Alignment for Multi-cluster Over-the-Air Computation
Oct 06, 2025One of the main challenges facing Internet of Things (IoT) networks is managing interference caused by the large number of devices communicating simultaneously, particularly in multi-cluster networks where multiple devices simultaneously transmit to their respective receiver. Over-the-Air Computation (AirComp) has emerged as a promising solution for efficient real-time data aggregation, yet its performance suffers in dense, interference-limited environments. To address this, we propose a novel Interference Alignment (IA) scheme tailored for up-link AirComp systems. Unlike previous approaches, the proposed method scales to an arbitrary number $\sf K$ of clusters and enables each cluster to exploit half of the available channels, instead of only $\tfrac{1}{\sf K}$ as in time-sharing. In addition, we develop schemes tailored to scenarios where users are shared between adjacent clusters.
DoF Analysis for -Channels through a Number-Filling Puzzle
Feb 03, 2024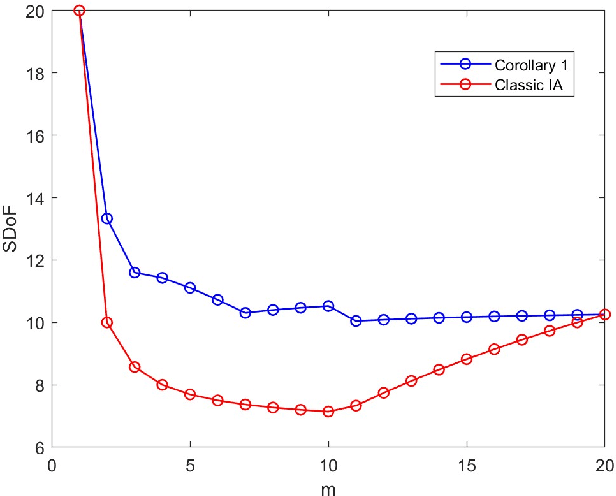
We consider a $\sf K$ user interference network with general connectivity, described by a matrix $\mat{N}$, and general message flows, described by a matrix $\mat{M}$. Previous studies have demonstrated that the standard interference scheme (IA) might not be optimal for networks with sparse connectivity. In this paper, we formalize a general IA coding scheme and an intuitive number-filling puzzle for given $\mat{M}$ and $\mat{N}$ in a way that the score of the solution to the puzzle determines the optimum sum degrees that can be achieved by the IA scheme. A solution to the puzzle is proposed for a general class of symmetric channels, and it is shown that this solution leads to significantly higher $\SDoF$ than the standard IA scheme.
Multiplex-detection Based Multiple Instance Learning Network for Whole Slide Image Classification
Aug 06, 2022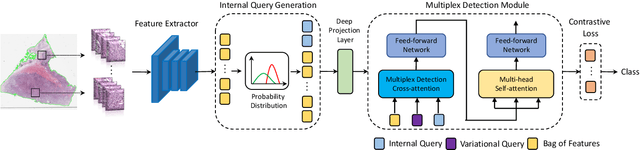
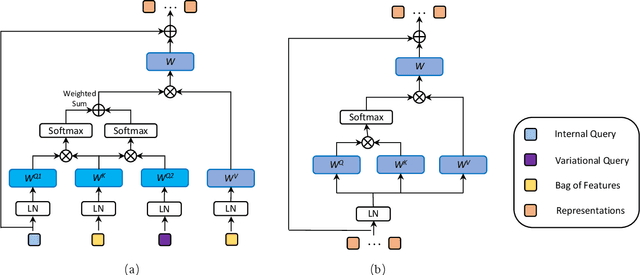
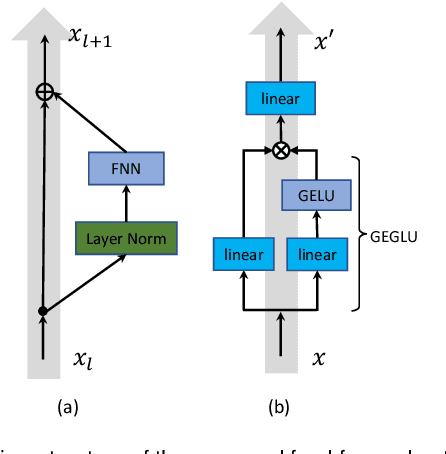
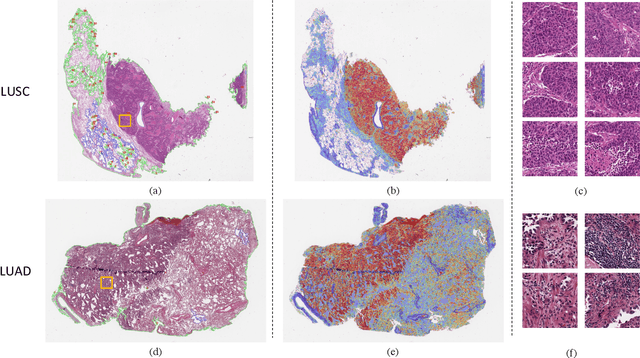
Multiple instance learning (MIL) is a powerful approach to classify whole slide images (WSIs) for diagnostic pathology. A fundamental challenge of MIL on WSI classification is to discover the \textit{critical instances} that trigger the bag label. However, previous methods are primarily designed under the independent and identical distribution hypothesis (\textit{i.i.d}), ignoring either the correlations between instances or heterogeneity of tumours. In this paper, we propose a novel multiplex-detection-based multiple instance learning (MDMIL) to tackle the issues above. Specifically, MDMIL is constructed by the internal query generation module (IQGM) and the multiplex detection module (MDM) and assisted by the memory-based contrastive loss during training. Firstly, IQGM gives the probability of instances and generates the internal query (IQ) for the subsequent MDM by aggregating highly reliable features after the distribution analysis. Secondly, the multiplex-detection cross-attention (MDCA) and multi-head self-attention (MHSA) in MDM cooperate to generate the final representations for the WSI. In this process, the IQ and trainable variational query (VQ) successfully build up the connections between instances and significantly improve the model's robustness toward heterogeneous tumours. At last, to further enforce constraints in the feature space and stabilize the training process, we adopt a memory-based contrastive loss, which is practicable for WSI classification even with a single sample as input in each iteration. We conduct experiments on three computational pathology datasets, e.g., CAMELYON16, TCGA-NSCLC, and TCGA-RCC datasets. The superior accuracy and AUC demonstrate the superiority of our proposed MDMIL over other state-of-the-art methods.