 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-FLow: Contrastive Learning by semi-supervised Iterative Pseudo labeling for Optical Flow Estimation
Nov 01, 2022
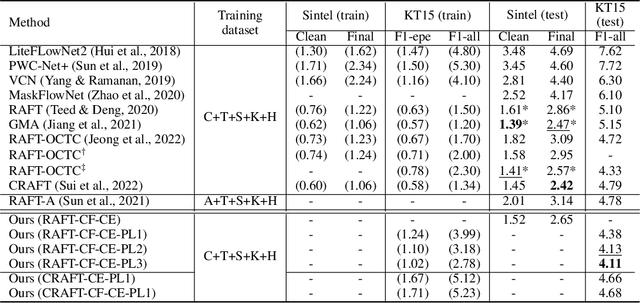
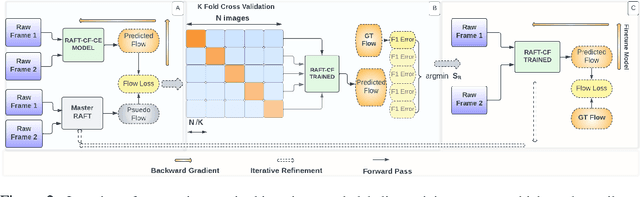
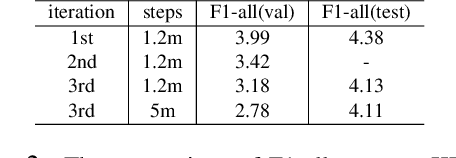
Synthetic datasets are often used to pretrain end-to-end optical flow networks, due to the lack of a large amount of labeled, real-scene data. But major drops in accuracy occur when moving from synthetic to real scenes. How do we better transfer the knowledge learned from synthetic to real domains? To this end, we propose CLIP-FLow, a semi-supervised iterative pseudo-labeling framework to transfer the pretraining knowledge to the target real domain. We leverage large-scale, unlabeled real data to facilitate transfer learning with the supervision of iteratively updated pseudo-ground truth labels, bridging the domain gap between the synthetic and the real. In addition, we propose a contrastive flow loss on reference features and the warped features by pseudo ground truth flows, to further boost the accurate matching and dampen the mismatching due to motion, occlusion, or noisy pseudo labels. We adopt RAFT as the backbone and obtain an F1-all error of 4.11%, i.e. a 19% error reduction from RAFT (5.10%) and ranking 2$^{nd}$ place at submission on the KITTI 2015 benchmark. Our framework can also be extended to other models, e.g. CRAFT, reducing the F1-all error from 4.79% to 4.66% on KITTI 2015 benchmark.
Semantics-Depth-Symbiosis: Deeply Coupled Semi-Supervised Learning of Semantics and Depth
Jun 21, 2022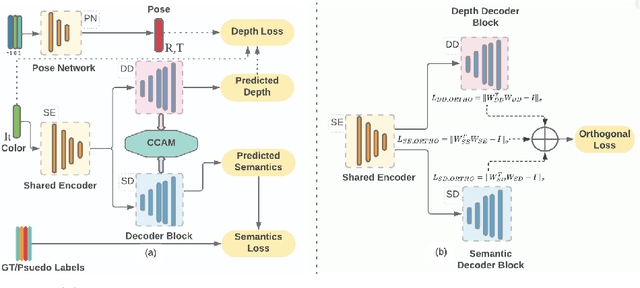
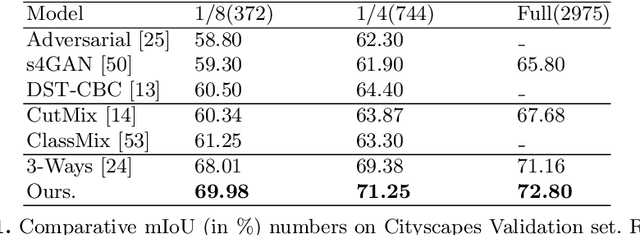
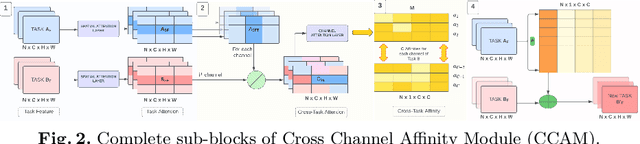
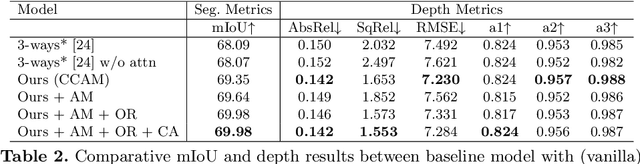
Multi-task learning (MTL) paradigm focuses on jointly learning two or more tasks, aiming for significant improvement w.r.t model's generalizability, performance, and training/inference memory footprint. The aforementioned benefits become ever so indispensable in the case of joint training for vision-related {\bf dense} prediction tasks. In this work, we tackle the MTL problem of two dense tasks, \ie, semantic segmentation and depth estimation, and present a novel attention module called Cross-Channel Attention Module ({CCAM}), which facilitates effective feature sharing along each channel between the two tasks, leading to mutual performance gain with a negligible increase in trainable parameters. In a true symbiotic spirit, we then formulate a novel data augmentation for the semantic segmentation task using predicted depth called {AffineMix}, and a simple depth augmentation using predicted semantics called {ColorAug}. Finally, we validate the performance gain of the proposed method on the Cityscapes dataset, which helps us achieve state-of-the-art results for a semi-supervised joint model based on depth and semantic segmentation.
FisheyeDistill: Self-Supervised Monocular Depth Estimation with Ordinal Distillation for Fisheye Cameras
May 05, 2022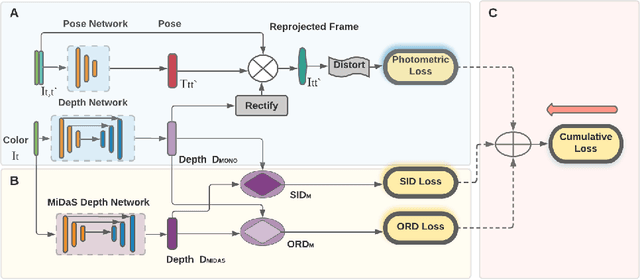



In this paper, we deal with the problem of monocular depth estimation for fisheye cameras in a self-supervised manner. A known issue of self-supervised depth estimation is that it suffers in low-light/over-exposure conditions and in large homogeneous regions. To tackle this issue, we propose a novel ordinal distillation loss that distills the ordinal information from a large teacher model. Such a teacher model, since having been trained on a large amount of diverse data, can capture the depth ordering information well, but lacks in preserving accurate scene geometry. Combined with self-supervised losses, we show that our model can not only generate reasonable depth maps in challenging environments but also better recover the scene geometry. We further leverage the fisheye cameras of an AR-Glasses device to collect an indoor dataset to facilitate evaluation.
PlaneMVS: 3D Plane Reconstruction from Multi-View Stereo
Mar 28, 2022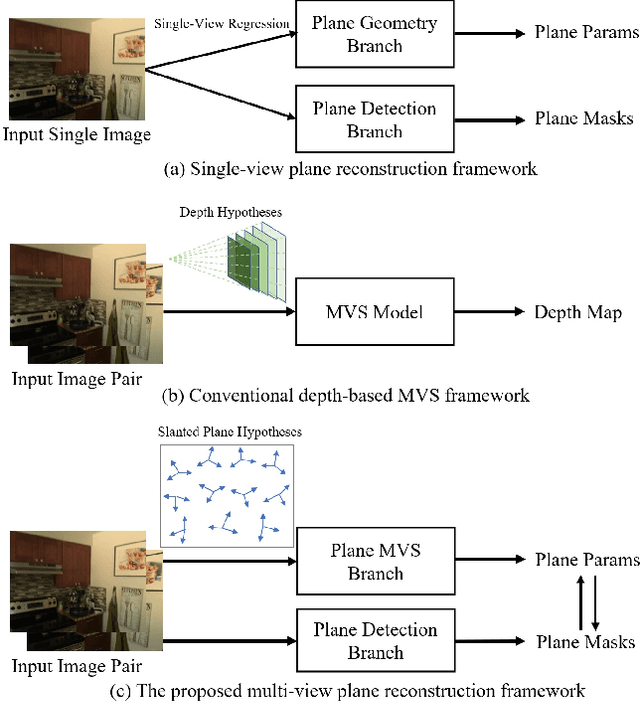

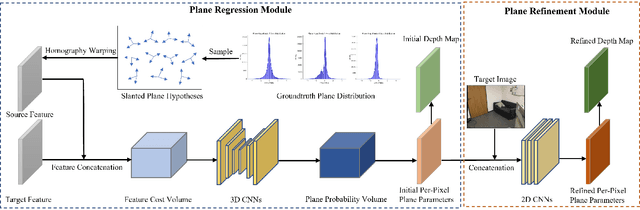
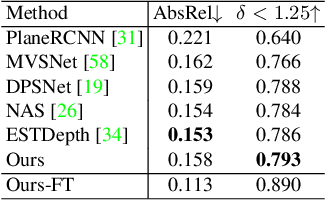
We present a novel framework named PlaneMVS for 3D plane reconstruction from multiple input views with known camera poses. Most previous learning-based plane reconstruction methods reconstruct 3D planes from single images, which highly rely on single-view regression and suffer from depth scale ambiguity. In contrast, we reconstruct 3D planes with a multi-view-stereo (MVS) pipeline that takes advantage of multi-view geometry. We decouple plane reconstruction into a semantic plane detection branch and a plane MVS branch. The semantic plane detection branch is based on a single-view plane detection framework but with differences. The plane MVS branch adopts a set of slanted plane hypotheses to replace conventional depth hypotheses to perform plane sweeping strategy and finally learns pixel-level plane parameters and its planar depth map. We present how the two branches are learned in a balanced way, and propose a soft-pooling loss to associate the outputs of the two branches and make them benefit from each other. Extensive experiments on various indoor datasets show that PlaneMVS significantly outperforms state-of-the-art (SOTA) single-view plane reconstruction methods on both plane detection and 3D geometry metrics. Our method even outperforms a set of SOTA learning-based MVS methods thanks to the learned plane priors. To the best of our knowledge, this is the first work on 3D plane reconstruction within an end-to-end MVS framework.
Can We Gain More from Orthogonality Regularizations in Training Deep CNNs?
Oct 22, 2018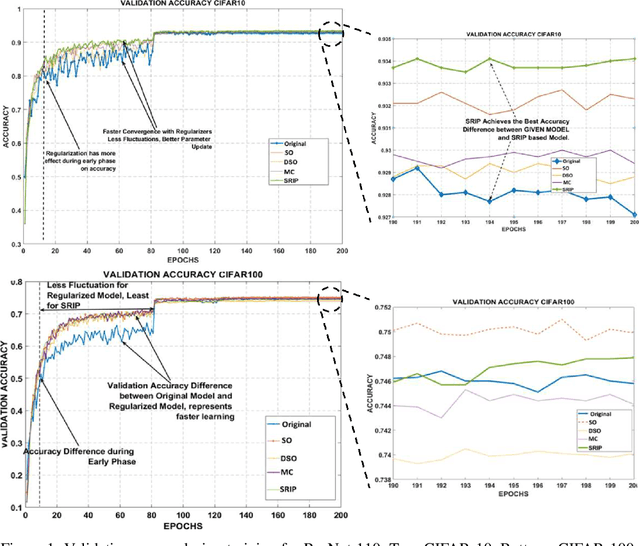

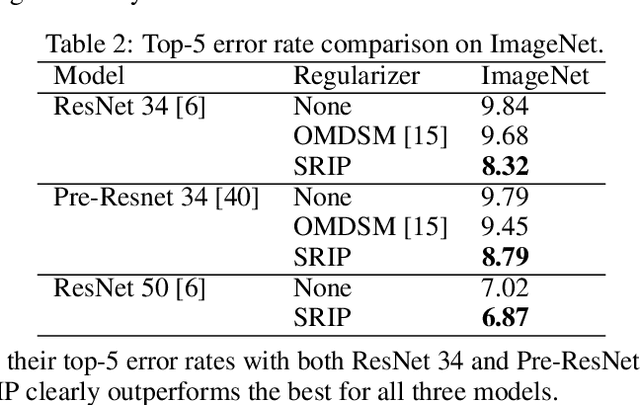
This paper seeks to answer the question: as the (near-) orthogonality of weights is found to be a favorable property for training deep convolutional neural networks, how can we enforce it in more effective and easy-to-use ways? We develop novel orthogonality regularizations on training deep CNNs, utilizing various advanced analytical tools such as mutual coherence and restricted isometry property. These plug-and-play regularizations can be conveniently incorporated into training almost any CNN without extra hassle. We then benchmark their effects on state-of-the-art models: ResNet, WideResNet, and ResNeXt, on several most popular computer vision datasets: CIFAR-10, CIFAR-100, SVHN and ImageNet. We observe consistent performance gains after applying those proposed regularizations, in terms of both the final accuracies achieved, and faster and more stable convergences. We have made our codes and pre-trained models publicly available: https://github.com/nbansal90/Can-we-Gain-More-from-Orthogonality.