 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Depth-Symbiosis: Deeply Coupled Semi-Supervised Learning of Semantics and Depth
Paper and Code
Jun 21, 2022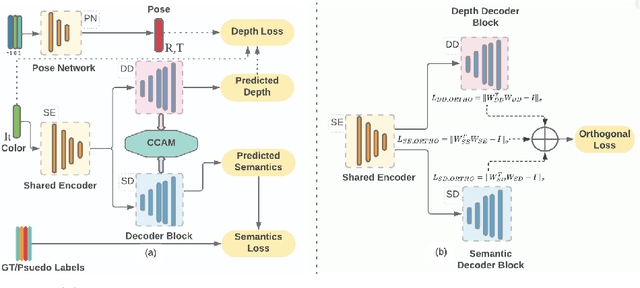
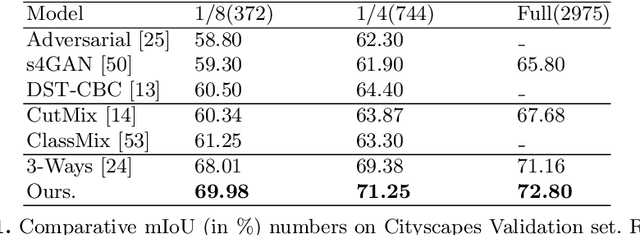
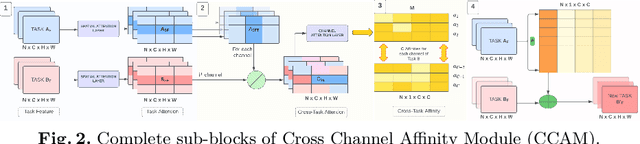
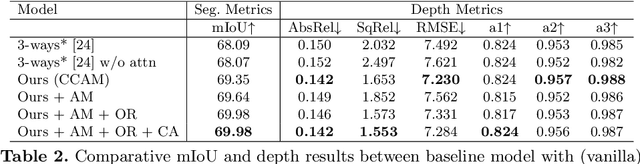
Multi-task learning (MTL) paradigm focuses on jointly learning two or more tasks, aiming for significant improvement w.r.t model's generalizability, performance, and training/inference memory footprint. The aforementioned benefits become ever so indispensable in the case of joint training for vision-related {\bf dense} prediction tasks. In this work, we tackle the MTL problem of two dense tasks, \ie, semantic segmentation and depth estimation, and present a novel attention module called Cross-Channel Attention Module ({CCAM}), which facilitates effective feature sharing along each channel between the two tasks, leading to mutual performance gain with a negligible increase in trainable parameters. In a true symbiotic spirit, we then formulate a novel data augmentation for the semantic segmentation task using predicted depth called {AffineMix}, and a simple depth augmentation using predicted semantics called {ColorAug}. Finally, we validate the performance gain of the proposed method on the Cityscapes dataset, which helps us achieve state-of-the-art results for a semi-supervised joint model based on depth and semantic segmentation.