 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum circuit complexity and unsupervised machine learning of topological order
Aug 06, 2025Inspired by the close relationship between Kolmogorov complexity and unsupervised machine learning, we explore quantum circuit complexity, an important concept in quantum computation and quantum information science, as a pivot to understand and to build interpretable and efficient unsupervised machine learning for topological order in quantum many-body systems. To span a bridge from conceptual power to practical applicability, we present two theorems that connect Nielsen's quantum circuit complexity for the quantum path planning between two arbitrary quantum many-body states with fidelity change and entanglement generation, respectively. Leveraging these connections, fidelity-based and entanglement-based similarity measures or kernels, which are more practical for implementation, are formulated. Using the two proposed kernels, numerical experiments targeting the unsupervised clustering of quantum phases of the bond-alternating XXZ spin chain, the ground state of Kitaev's toric code and random product states, are conducted, demonstrating their superior performance. Relations with classical shadow tomography and shadow kernel learning are also discussed, where the latter can be naturally derived and understood from our approach. Our results establish connections between key concepts and tools of quantum circuit computation, quantum complexity, and machine learning of topological quantum order.
Rejoining fragmented ancient bamboo slips with physics-driven deep learning
May 13, 2025



Bamboo slips are a crucial medium for recording ancient civilizations in East Asia, and offers invaluable archaeological insights for reconstructing the Silk Road, studying material culture exchanges, and global history. However, many excavated bamboo slips have been fragmented into thousands of irregular pieces, making their rejoining a vital yet challenging step for understanding their content. Here we introduce WisePanda, a physics-driven deep learning framework designed to rejoin fragmented bamboo slips. Based on the physics of fracture and material deterioration, WisePanda automatically generates synthetic training data that captures the physical properties of bamboo fragmentations. This approach enables the training of a matching network without requiring manually paired samples, providing ranked suggestions to facilitate the rejoining process. Compared to the leading curve matching method, WisePanda increases Top-50 matching accuracy from 36\% to 52\%. Archaeologists using WisePanda have experienced substantial efficiency improvements (approximately 20 times faster) when rejoining fragmented bamboo slips. This research demonstrates that incorporating physical principles into deep learning models can significantly enhance their performance, transforming how archaeologists restore and study fragmented artifacts. WisePanda provides a new paradigm for addressing data scarcity in ancient artifact restoration through physics-driven machine learning.
Line Drawing Guided Progressive Inpainting of Mural Damages
Nov 12, 2022



Mural image inpainting refers to repairing the damage or missing areas in a mural image to restore the visual appearance. Most existing image-inpainting methods tend to take a target image as the only input and directly repair the damage to generate a visually plausible result. These methods obtain high performance in restoration or completion of some specific objects, e.g., human face, fabric texture, and printed texts, etc., however, are not suitable for repairing murals with varied subjects, especially for murals with large damaged areas. Moreover, due to the discrete colors in paints, mural inpainting may suffer from apparent color bias as compared to natural image inpainting. To this end, in this paper, we propose a line drawing guided progressive mural inpainting method. It divides the inpainting process into two steps: structure reconstruction and color correction, executed by a structure reconstruction network (SRN) and a color correction network (CCN), respectively. In the structure reconstruction, line drawings are used by SRN as a guarantee for large-scale content authenticity and structural stability. In the color correction, CCN operates a local color adjustment for missing pixels which reduces the negative effects of color bias and edge jumping. The proposed approach is evaluated against the current state-of-the-art image inpainting methods. Qualitative and quantitative results demonstrate the superiority of the proposed method in mural image inpainting. The codes and data are available at {https://github.com/qinnzou/mural-image-inpainting}.
Label Mask for Multi-Label Text Classification
Jun 18, 2021
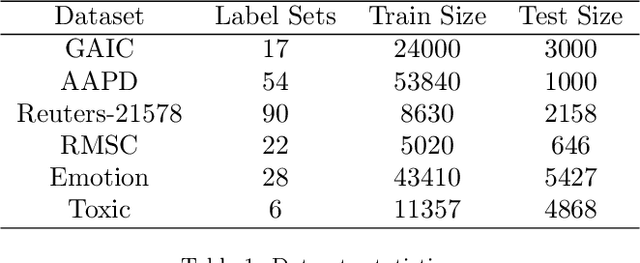
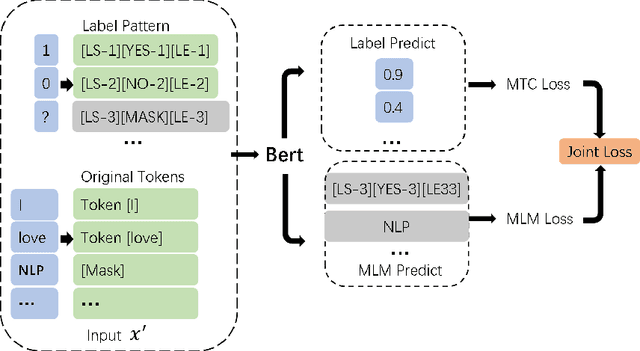
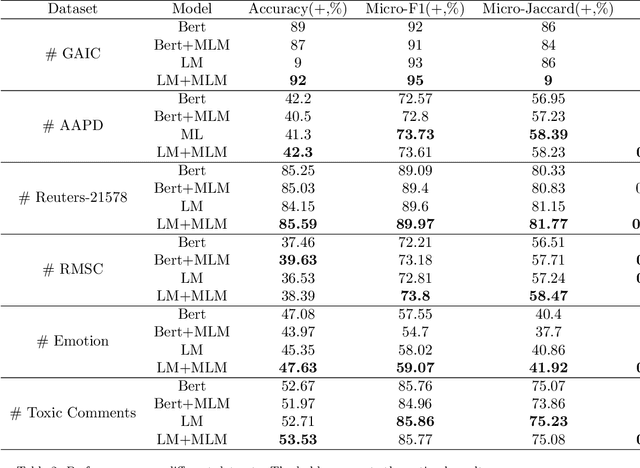
One of the key problems in multi-label text classification is how to take advantage of the correlation among labels. However, it is very challenging to directly model the correlations among labels in a complex and unknown label space. In this paper, we propose a Label Mask multi-label text classification model (LM-MTC), which is inspired by the idea of cloze questions of language model. LM-MTC is able to capture implicit relationships among labels through the powerful ability of pre-train language models. On the basis, we assign a different token to each potential label, and randomly mask the token with a certain probability to build a label based Masked Language Model (MLM). We train the MTC and MLM together, further improving the generalization ability of the model. A large number of experiments on multiple datasets demonstrate the effectiveness of our method.
CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
Apr 04, 2019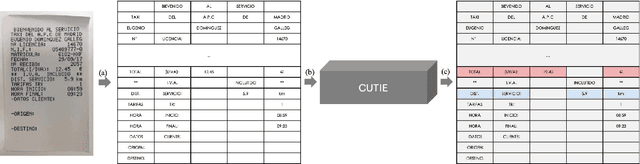
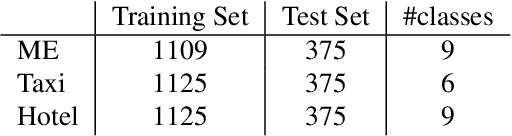
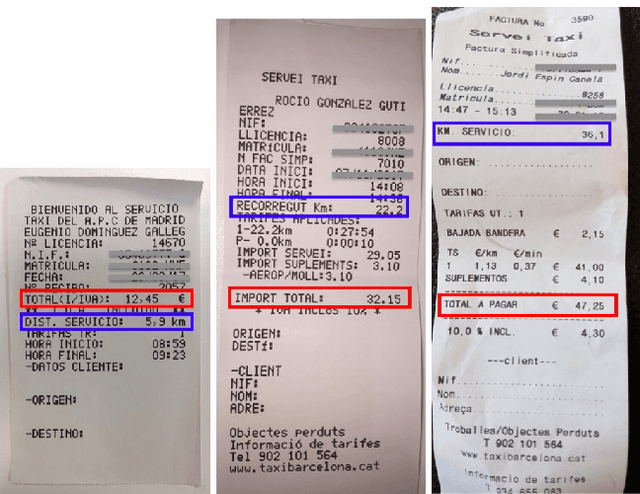

Extracting key information from documents, such as receipts or invoices, and preserving the interested texts to structured data is crucial in the document-intensive streamline processes of office automation in areas that includes but not limited to accounting, financial, and taxation areas. To avoid designing expert rules for each specific type of document, some published works attempt to tackle the problem by learning a model to explore the semantic context in text sequences based on the Named Entity Recognition (NER) method in the NLP field. In this paper, we propose to harness the effective information from both semantic meaning and spatial distribution of texts in documents. Specifically, our proposed model, Convolutional Universal Text Information Extractor (CUTIE), applies convolutional neural networks on gridded texts where texts are embedded as features with semantical connotations. We further explore the effect of employing different structures of convolutional neural network and propose a fast and portable structure. We demonstrate the effectiveness of the proposed method on a dataset with up to $4,484$ labelled receipts, without any pre-training or post-processing, achieving state of the art performance that is much higher than BERT but with only $1/10$ parameters and without requiring the $3,300$M word dataset for pre-training. Experimental results also demonstrate that the CUTIE being able to achieve state of the art performance with much smaller amount of training data.
Improving the Interpretability of Deep Neural Networks with Knowledge Distillation
Dec 28, 2018
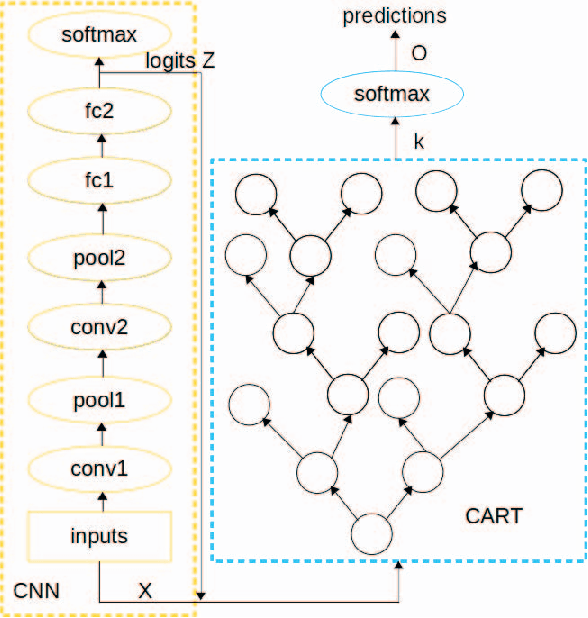


Deep Neural Networks have achieved huge success at a wide spectrum of applications from language modeling, computer vision to speech recognition. However, nowadays, good performance alone is not sufficient to satisfy the needs of practical deployment where interpretability is demanded for cases involving ethics and mission critical applications. The complex models of Deep Neural Networks make it hard to understand and reason the predictions, which hinders its further progress. To tackle this problem, we apply the Knowledge Distillation technique to distill Deep Neural Networks into decision trees in order to attain good performance and interpretability simultaneously. We formulate the problem at hand as a multi-output regression problem and the experiments demonstrate that the student model achieves significantly better accuracy performance (about 1\% to 5\%) than vanilla decision trees at the same level of tree depth. The experiments are implemented on the TensorFlow platform to make it scalable to big datasets. To the best of our knowledge, we are the first to distill Deep Neural Networks into vanilla decision trees on multi-class datasets.
Interpretable Deep Convolutional Neural Networks via Meta-learning
Aug 19, 2018

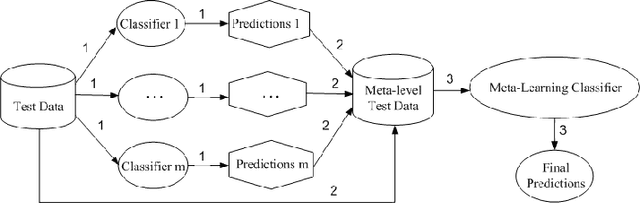

Model interpretability is a requirement in many applications in which crucial decisions are made by users relying on a model's outputs. The recent movement for "algorithmic fairness" also stipulates explainability, and therefore interpretability of learning models. And yet the most successful contemporary Machine Learning approaches, the Deep Neural Networks, produce models that are highly non-interpretable. We attempt to address this challenge by proposing a technique called CNN-INTE to interpret deep Convolutional Neural Networks (CNN) via meta-learning. In this work, we interpret a specific hidden layer of the deep CNN model on the MNIST image dataset. We use a clustering algorithm in a two-level structure to find the meta-level training data and Random Forest as base learning algorithms to generate the meta-level test data. The interpretation results are displayed visually via diagrams, which clearly indicates how a specific test instance is classified. Our method achieves global interpretation for all the test instances without sacrificing the accuracy obtained by the original deep CNN model. This means our model is faithful to the deep CNN model, which leads to reliable interpretations.